 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOpsAWS spot instances are an excellent way to significantly reduce your EC2 on demand instance cost by up to 90%. Increasing numbers of companies, from SMBs to enterprises, have been leveraging spot instances for even mission-critical and production workloads. Spot instances pricing has helped them greatly optimize their cloud costs.
AWS spot instances represent AWS’s excess capacity. As a cloud provider, they must have spare capacity available for any surge in customer demand. To offset the loss of idle infrastructure, AWS offers this excess capacity at a massive discount to drive usage. That is why spot instances pricing is so affordable in comparison to EC2 pricing on demand.
In this article, you will learn:
- When should you use Amazon spot instances?
- What are Spot Instance Interruptions?
- How Can You Check and Select Pricing for Spot Instances?
- How Can You Check Spot Instance Price History?
- What is AWS Spot Fleet?
- Automated Spot Instance Management with Spot
When should you use Amazon spot instances?
The general perception of Amazon spot instances is that they are ideal for web services, containerized applications or other stateless, fault-tolerant workloads.
However, in reality, they can also be used for a much broader set of use cases, without any significant impact on availability or performance. Here are some examples:
- Stateful applications typically require data and IP persistence. With automated solutions, even in the event of AWS spot instance replacement, your workload will immediately restart in the desired Availability Zone, from the same exact data point, maintaining root and data volumes as well as private and public IPs.
- Machine Learning is another area in which deep learning and training progress can be negatively impacted by unplanned AWS spot instance interruptions. But with the right tools, you can successfully run all your ML projects on spot instances.
- CI/CD operations, whether Jenkins, Chef, Gitlab or others, can be run at scale on spot instances quite easily.
- Big Data running on AWS EMR, Hadoop or Spark are great candidates for spot instances.
- Distributed DBs such as Elasticsearch, Cassandra, Mongo which can handle a “reboot” of a single instance without losing data or affect service, can also run on spot instances.
What are Spot Instance Interruptions?
This discounted Amazon EC2 spot instance pricing comes with a caveat. AWS can “pull the plug” and terminate spot instances with just a 2 minute warning. These interruptions occur when AWS needs to draw from the excess capacity to service customers who purchased reserved instances, savings plans or on-demand instances.
While AWS does offer “capacity rebalancing” signals which might notify you that an EC2 spot instance is at risk of termination, AWS does not guarantee these signals will be delivered early enough for you to take action.
Here are some of the reasons Amazon EC2 may interrupt a spot instance:
- Capacity—EC2 does not have enough unused instances to supply on-Demand or reserved instances, so it suspends spot instances to fulfill those requests.
- Constraint—if the spot instance request specified a launch group or Availability Zone group, and these constraints cannot be accommodated, instances will be terminated as a group.
When an instance is interrupted, you can select one of three possible actions—terminating the spot instance (default), stopping the spot instance (making it possible to restart it with the same launch specifications), or hibernating the instance.
How Can You Check and Select Pricing for Spot Instances?
You can find spot instance pricing on AWS’s spot instance pricing page as well as on the spot instance advisor page. This will help you determine the savings you can achieve in comparison to EC2 pricing on demand.
Regarding the selection of your spot instance price, there is no real benefit to bidding higher than the default, on-demand price.
This is true because:
- AWS determines the actual price based on overall market trends, not on specific, real-time bids
- AWS spot instance interruptions are determined by AWS without any relation to your bid price
Therefore, you can safely leave maximum price at whatever default AWS has it set to.

How Can You Check Spot Instance Price History?
If however, you only wish to spend a very specific amount, whether below the on-demand rate, or even below the current spot instance rate, you can check out historical spot instance prices, and specify your desired price. That way you will only run your EC2 spot instance when the actual market price matches your specific bid or is lower.
To view spot price history:
- Open the Amazon EC2 console and click Spot Requests.
- Select Pricing history.
- Choose a product (operating system), instance type, and date range, and a price history is displayed. Move the pointer over the chart to see price trends over time.
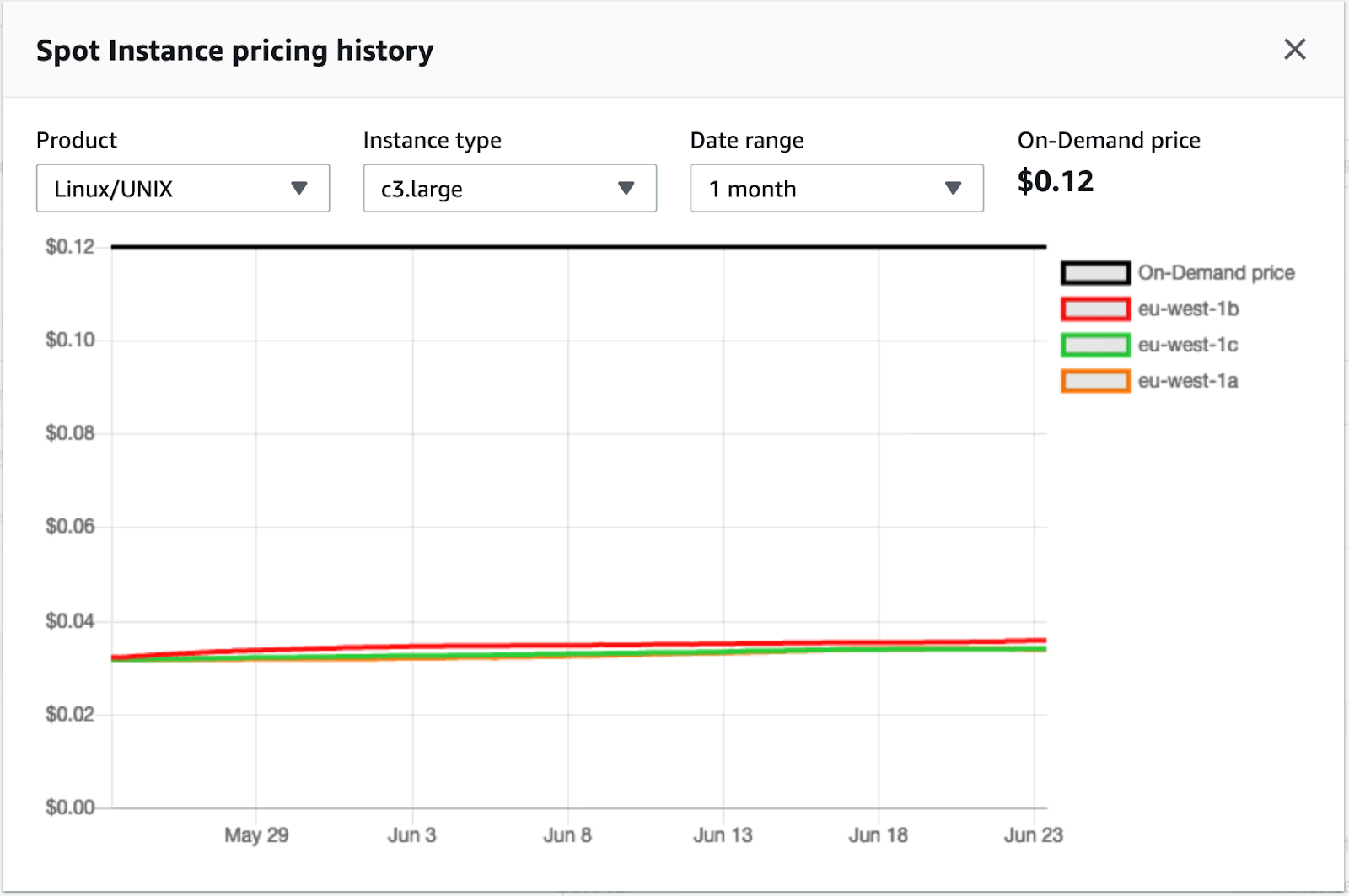
Source: AWS
{kind=link}
You can select from one of two pricing options for spot instances:
- Regular spot pricing—instances can be terminated with 2 minutes notice.
- Defined duration—you can get a spot instance guaranteed to run for a period of 1-6 hours. The longer the defined duration, the lower the discount provided for the spot instance. Defined duration instances grant discounts of 30-50% vs. On-Demand pricing.
What is AWS Spot Fleet?
Spot Fleet is a collection of spot instances. It makes it easier to respond to events on spot instances, such as instance termination, and provides central management, without requiring applications to continuously poll spot instances.
You can create Spot Fleet requests using the Spot Fleet API or the CLI. A Spot Fleet request includes the number of instances required, type of instances, the target capacity, and maximum price.
EC2 tries to maintain the target capacity, adding spot instances if available, based on the request details. When spot instances are terminated, Spot Fleet attempts to replace them using the lowest price option available.
Automated Spot Instance Management with Spot
While AWS Spot Fleet enables you to manage a large group or fleet of spot instances with different allocation strategies (i.e. lowest price, diversified, capacity optimized, etc.) along with many other options, to make it all work well, requires a large amount of manual configuration, setup and maintenance.
If you are looking for a turn-key solution to move more of your workloads to spot instances, with greater ease and confidence, here is a checklist of value-added functionality that you can get with Spot.
| Use Case | Feature | Do-it-yourself | Spot.io |
| All | SLA for availability | None | 99.99% availability |
| Containerized workloads | Container-driven autoscaling and bin-packing | Requires significant configuration. Also, requires multiple ASGs to accommodate instance size diversification. | Turn-key solution with optimized bin-packing, built in support for variable and dynamic instance sizes/types/life cycles, container autoscaler based on Pod/Task requirements. |
| Stateful workloads | Storage persistence | EBS volumes can be saved. Re-attachment to replacement instance is possible only when capacity is available in the same market, and provided the spot request is defined as “persistent”, or the spot fleet has “maintain” enabled. | Proactive identification of termination allows for reliable and automatic re-attachment of EBS volumes (same state) to replacement instances across instance types and sizes, or even AZs. |
| All | Graceful draining | With just a 2 minute warning of spot instance termination, applications and services might be interrupted mid-process. Note: AWS capacity rebalancing signal is not guaranteed to arrive early enough to proactively take action. | Early prediction of spot instance termination allows for graceful draining and automatic workload relocation to new instance(s). |
| All | Automatic fallback to on-demand | Not supported | Fully automated for scenarios where there are no available spot instances. |
| All | Automatic return from on-demand to spot instance(s) | Not supported | Workload will be automatically moved back from on-demand as soon as appropriate spot instance type is available. |
| Containerized workloads | Cloud-native cost allocation for Kubernetes and ECS | Not supported | Cost allocation and showback at the container level by namespaces, resources, labels and annotations. |
| All | Proactive usage of available reservations and savings plans | Not supported | Workloads will always be prioritized to run on available AWS Savings Plans & reserved instances and will revert to spot instances for increased savings when applicable. |
| Containerized workloads | Vertical container rightsizing | Requires additional collection of metrics and manual analysis. | Real-time measurement of Pods’ and Tasks’ CPU and Memory consumption informs requirements for cost-efficient cluster deployments. |
| Containerized workloads | Customizable buffer of spare nodes for workloads that cannot wait for scaling | Not supported | Fully supported |
| Containerized workloads | Centralized management of multiple node groups | Requires management of multiple autoscaling groups, one per node group. | Single point of management for multiple worker node groups, each with their own launch specifications. |
| Containerized workloads | Declarative infrastructure | Node Lifecycle control for Pods requires manual configuration of Labels & Taints on each Node Group as well as matching tolerations on the pods. | Simply declare infrastructure requirements from the Pod specifications by using a single label. |
| Autoscaling workloads | Instance auto-recovery | AWS provides retroactive recovery, after spot instance termination (2 min advance notice) only with “Maintain” status, and depending on availability. | Proactive detection of spot instance termination triggers deployment of replacement instances, with recovery to different markets as relevant. |
| Stateful workloads | IP persistence | Supported only if the instance or fleet is defined as “persistent” or “maintain” respectively. | Fully Supported, across spot instance markets. |
| All | Preferred compute pool & network subnet prioritization | A structured, hierarchal priority list can be configured, but will follow the exact, defined order even when less than optimal. | Able to prioritize AZs and Instance Types within spot instance allocation strategy, to dynamically match workloads with optimal resources. |
| All | Support for AWS services and 3rd party integrations | Available via Auto Scaling Groups (ECS, EKS, Beanstalk). | Available with Beanstalk, EMR, CodeDeploy, OpsWorks, ELB/ALB, Route53, Chef, Jenkins, GitLab, Rancher, Docker Swarm, RightScale, D2iQ as well as automatically generated templates for Terraform, CloudFormation, and JSON |
| Stateful workloads | Instance auto-recovery | 2 minutes notification before spot instance interruption, restricts duration of any shutdown processes. Additionally, only recovers to the same spot instance market. | Advanced prediction of interruption, allows for graceful termination and recovery to alternative spot instance types and even on-demand, ensures highest availability |
To make AWS EC2 spot instances a real part of your cloud cost optimization strategy, see our Ocean product page for Kubernetes and containerized workloads and our Elastigroup product page for non-containerized applications.