 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Here at Spot by NetApp we’re continuously innovating our machine learning models used for identifying and predicting spot capacity usage and interruptions for all major public clouds (AWS, Azure and GCP). These proprietary algorithms expand the ability to utilize spot capacity for production and mission-critical workloads, allowing our customers to enjoy up to 90% cloud compute cost reduction with SLAs and SLOs that guarantee availability.
Recently we’ve rolled out a package of significant enhancements to those models, most notably our new Predictive Rebalancing feature. This new rebalancing model is application–driven, combining advanced predictive algorithms with a deep understanding of infrastructure and real-time analysis of workload requirements to automatically provision and allocate cloud infrastructure in the most efficient and effective way possible. This not only provides far earlier and more finely tuned predictions but takes your unique workload and application requirements into consideration thereby ensuring that each and every process has the time it needs to be completed. In the event of a predicted interruption, each application will be able to gracefully transition to new replacement instances. This alignment of predictions with application needs ensures uptime, scale and successful workload execution for any situation.
In practical terms, you now can reliably run an even broader range of applications on spot capacity, as our more accurate visibility into supply and demand drives better selection of long-living spot instances and greater proactivity in avoiding interruptions and disruptions.
Let’s peek under the hood as well as review some of the new features you’ll have access to, using AWS EC2 spot instances as an example.
Tracking spot instance capacity
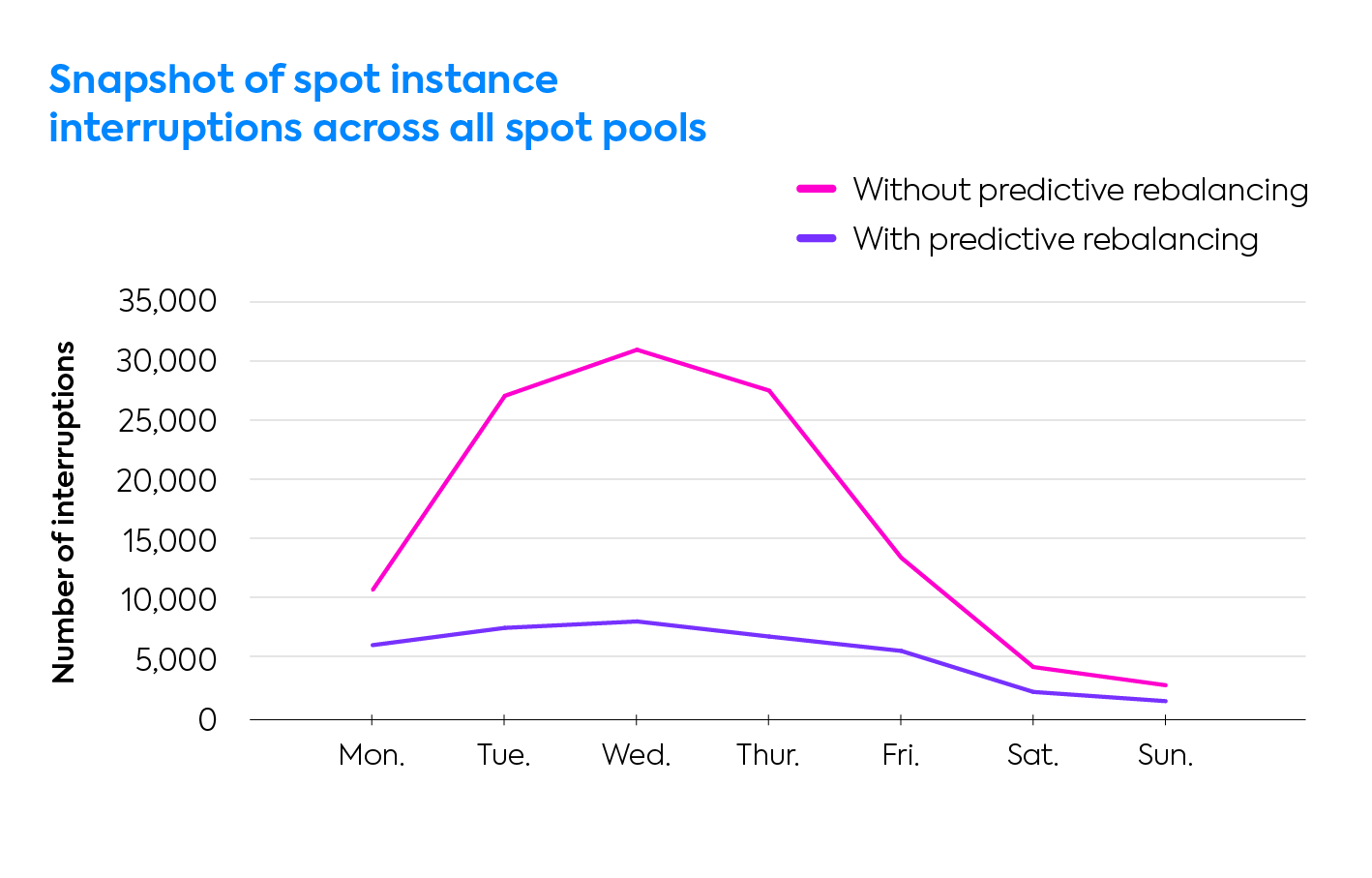
AWS has approximately 15,000 spot instance capacity pools across the globe, each uniquely defined by its region/availability zone, instance type, size and operating system. With availability based on ever-changing supply and demand, determining which spot instances will have greater longevity and which are about to be terminated requires access to significant amounts of both historical and current EC2 consumption, upon which machine-learning algorithms can learn to accurately predict these capacity pools’ behavior.
With over billions of events, collected by our platform, Spot has access to exactly this sort of unique data. Coupling this with our brand-new algorithm we are now able to reliably predict, to an even greater extent than before, which spot instances will be interrupted and which will enjoy greater longevity, benefiting our customers with lowest-cost cloud compute and enterprise-level SLA for high availability.
Machine learning algorithms for predicting spot instance interruptions
Our updated algorithms for Predictive Rebalancing can accurately predict and replace spot instances, with an 85% level of accuracy, up to an hour ahead of an interruption during peak business hours. Additionally, when it comes to selecting desired spot instance types (see below), periods of longevity can be requested with our algorithms deploying matching instances with the highest probability of matching the defined requirements.
These predictive algorithms sample multiple, statistically significant data sets and have been proven to accurately reflect spot instance behavior in the broader AWS EC2 environment.
Predictive Rebalancing features
Spot customers using Elastigroup for applications can now run a broader range of workloads, even those that are more sensitive to interruptions – for example, applications that have long draining times – on inexpensive EC2 spot instances without concern for downtime or performance degradation.
Once you have chosen your desired cluster configurations, you can define the parameters for managing your spot instances in the event of actual or potential interruptions.
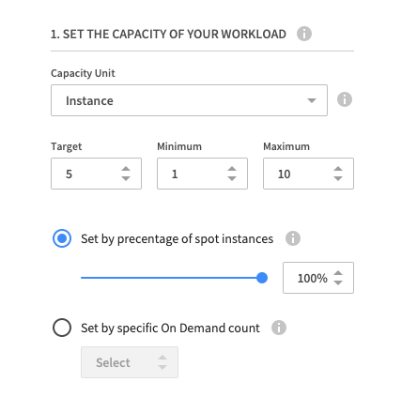
Workload capacity
Here you can select either instances or vCPUs and the desired target, minimum and maximum respectively. If you wish to always run part of your workload with on-demand instances you can define either a specific number of instances or set a percentage of on-demand vs. spot instances.
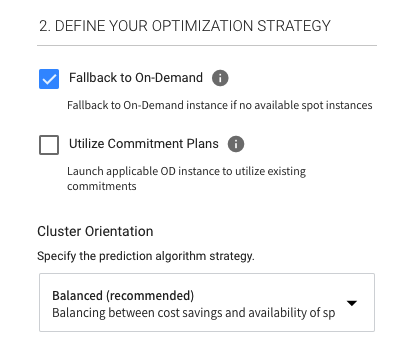
Optimization strategy
This feature has three parts. Firstly, you can select fallback to on-demand in the event there are no available spot instances. Secondly, you can opt to utilize any available reserved instances before spinning up new spot instances. This drives even greater cost-efficiency by using already paid for resources.
Finally, you can define your spot instance portfolio’s overall orientation as follows:
- Cost – Spot by NetApp will seek out the least expensive spot instances to run on, even at the risk of more frequent replacements.
- Availability – Spot will seek out the pool of spot instances with the greatest longevity for your workload.
- Balanced – This is the Spot’s recommended orientation where a balance between cost and availability is sought.
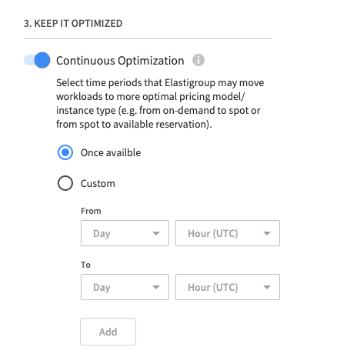
Continuous optimization
If fallback to on-demand instances occurred, you can choose when your workload should be returned to spot instances or moved to an instance type that has already-purchased and available reserved capacity.
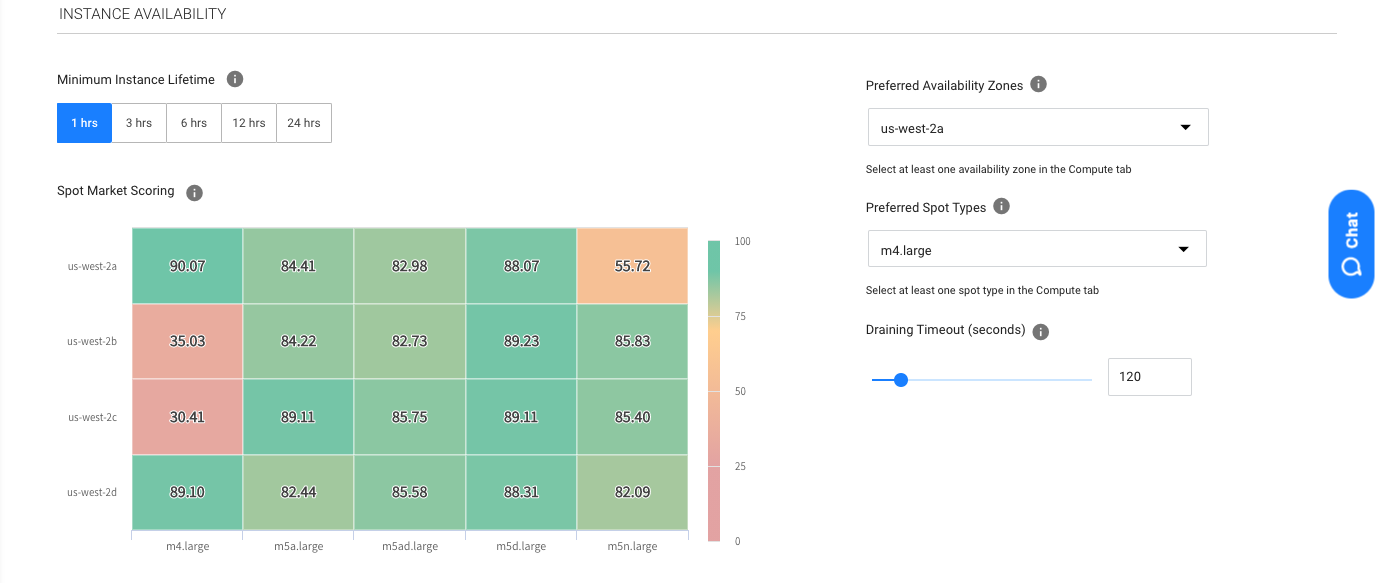
Visibility into EC2 spot instance availability and lifespan
Here you can select the desired amount of time you wish your workloads to run without any interruption to their underlying instances. Spot will seek out spot instances from your selected families, sizes and AZ’s that have the greatest probability for running that long.
You can also define the draining period your application requires so our automation will start replacing the instances with enough time before the interruption is predicted to occur, allowing for complete and graceful draining.
Application Driven Predictive Rebalancing
Using spot instances for mission-critical workloads always carried the risk of interruptions, making their use, while financially attractive, less than ideal. Spot has been enabling cloud consumers to use spot instances for dramatic cost savings, while ensuring high availability. Today we are taking this to the next level by coupling our new Predictive Rebalancing with our advanced cloud compute automation and continuous optimization, so all your applications and workloads will always have the resources they need for high availability, performance and maximum cost efficiency.
Predictive Rebalancing is being rolled out across our customer base and is accessible via the Spot console. You will be able to configure Predictive Rebalancing through the UI, API or your preferred IAC – Terraform or Cloudformation. To get started contact us today!