 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOpsWhat is Kubernetes ReplicaSet?
A ReplicaSet (RS) is a Kubernetes object that ensures there is always a stable set of running pods for a specific workload. The ReplicaSet configuration defines a number of identical pods required, and if a pod is evicted or fails, creates more pods to compensate for the loss.
In Kubernetes, you do not create ReplicaSets directly. ReplicaSets are set up as part of the Deployment construct. We’ll show how Deployments automatically create ReplicaSets, with a practical code example.
Learn more in our detailed guide to kubernetes deployment strategy.
This is part of our series of articles on Kubernetes autoscaling.
Related content: Read our guide to cluster autoscaler.
In this article, you will learn:
- How Does a ReplicaSet Work and When Should You Use it?
- 3 Types of Kubernetes Replication
- Quick Tutorial: Create a Deployment with a ReplicaSet
- Kubernetes Infrastructure Automation with Spot by NetApp
How Does a ReplicaSet Work and When Should You Use it?
You can define a ReplicaSet with fields, including:
- A selector—lets you specify how the selector should choose pods.
- A number of replicas—this indicates how many pods the ReplicaSet should maintain.
- A pod template—the ReplicaSet uses the pod template when creating pods, and adding pods to meet the required number of replicas.
Once you define the fields, the ReplicaSet starts creating and deleting pods to reach the specified amount.
Related content: read our guide to Kubernetes autoscaling.
3 Types of Kubernetes Replication
A ReplicaSet is one of three types of Kubernetes replication. Replication Controllers were the precursor to ReplicaSets, and Deployments are a declarative way to control ReplicaSets and pods. The code examples in this section were shared by Mirantis.
Another mechanism that deploys pods on multiple nodes, primarily used for background services, is the Kubernetes Daemonset – learn more in our guide.
Kubernetes ReplicationController
This is an older replication mechanism, which was replaced by ReplicaSets, but still works and is widely used. It creates a certain number of identical pods, and if a pod fails, replaces it. It also lets you update several pods or delete pods with one command.
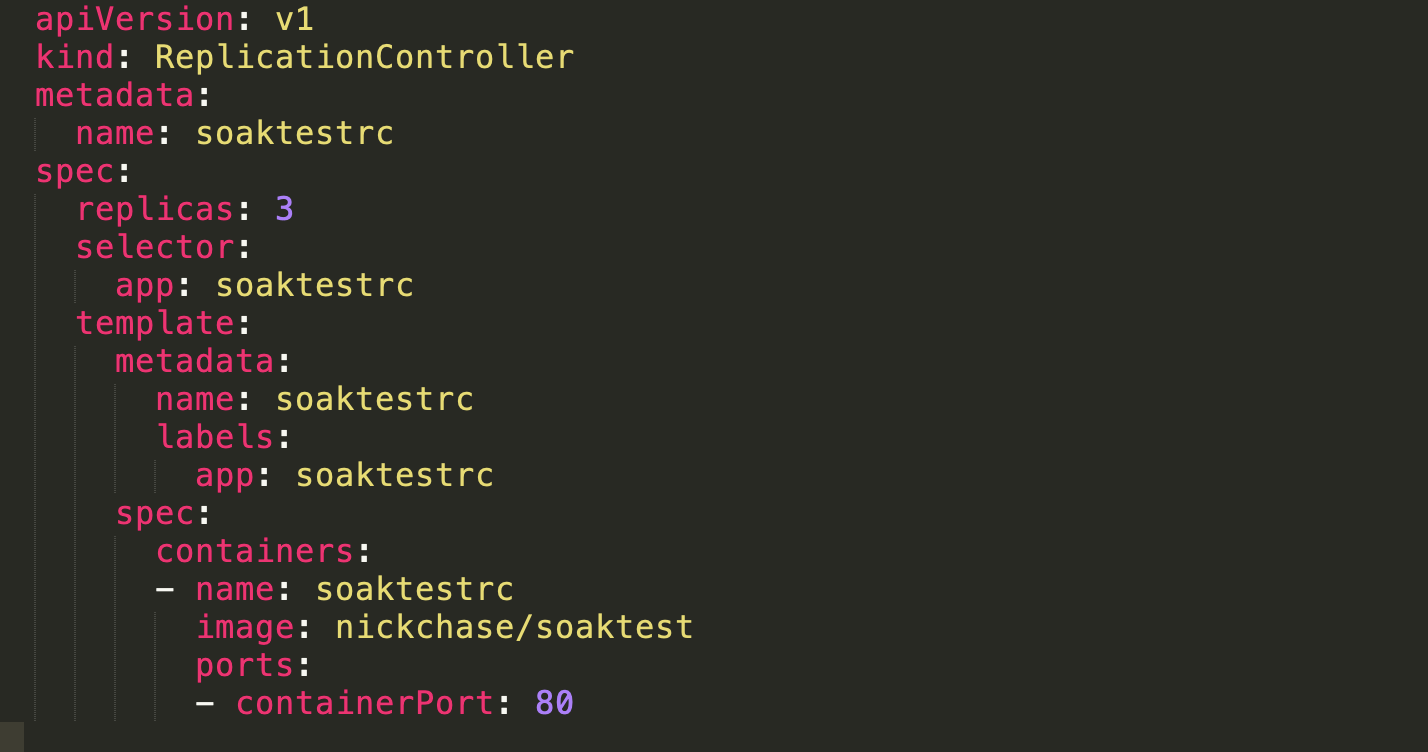
The ReplicationController has a name, and specifies how many times the pod should be replicated (3 in the example above). The template specifies which pod should be replicated. The selector determines which pods belong to this Replication Controller.
While pods created by ReplicationController are semantically identical, their configuration may change over time. This makes it useful for replicated stateless applications, sharded topologies, worker-pool, and other scenarios.
Kubernetes ReplicaSets
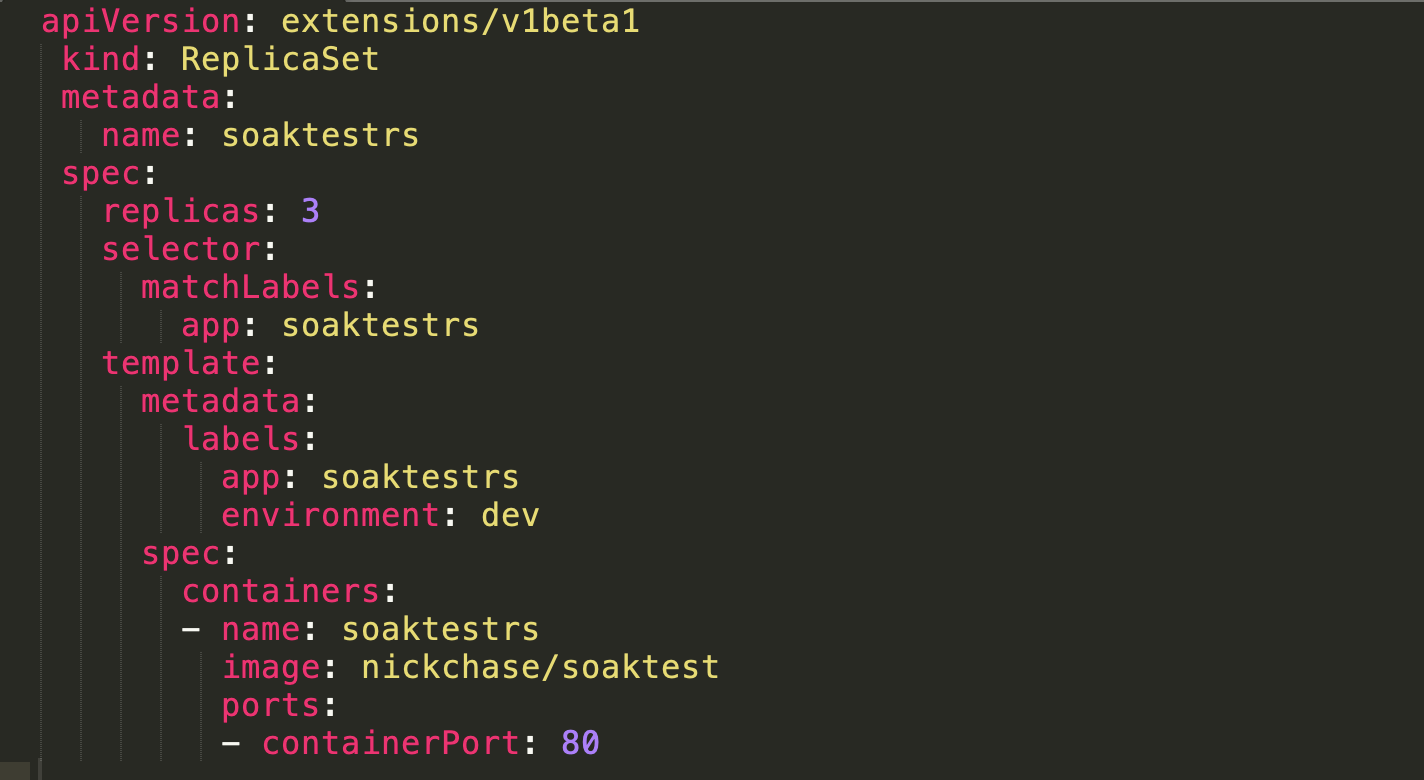
ReplicaSets are declared in a similar way to ReplicationControllers, but provide more selector options. According to the Kubernetes documentation, ReplicaSets are usually not used directly—they are typically created as part of a deployment.
Here is a simple example using matchLabels as the selector.
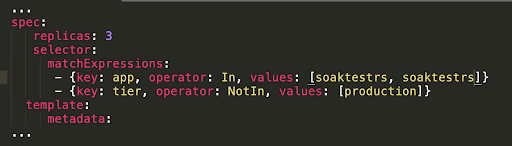
Here is a more advanced example that checks two conditions to see if a pod belongs to the ReplicaSet: testing if the app label matches the matchExpressions, and checking if the “tier” label does not equal to “production”.
Deployments
Deployments are one level up from ReplicaSets. They allow you to use a declarative method to deploy ReplicaSets and pods. You use YAML configuration to define what your group of pods should look like, and the deployment manipulates Kubernetes objects to create pods exactly according to the YAML specification.
Unlike a ReplicaSet, in a deployment, you can modify the YAML Pod template, and the deployment will take care of rolling out the changes. You can roll back to a previous version of your configuration if necessary.
Quick Tutorial: Create a Deployment with a ReplicaSet
This tutorial is based on code from the Kubernetes documentation. We’ll define a deployment with a ReplicaSet that provisions 3 NGINX pods.
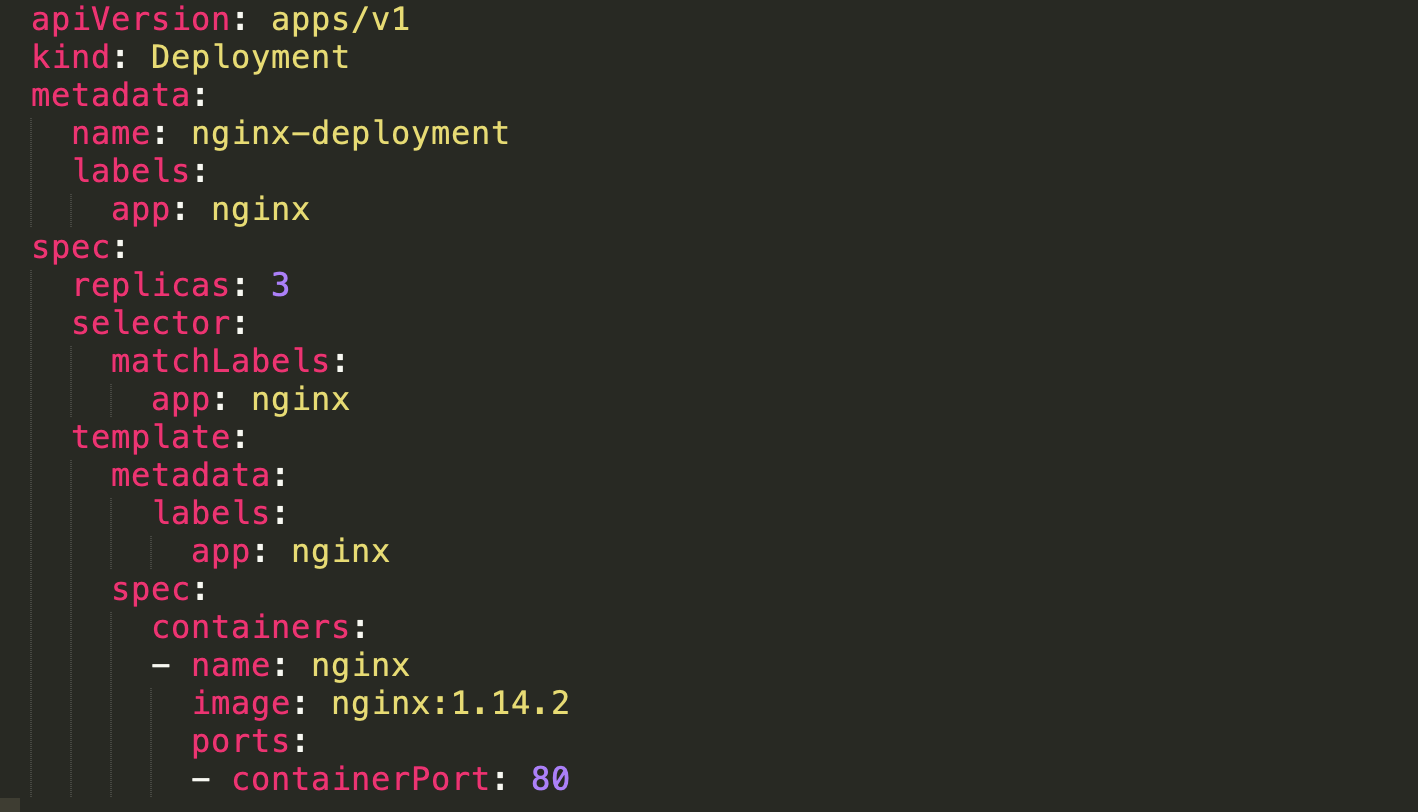
A few things to note about the deployment structure:
- The .spec.replicas field defines the number of replica pods
- The .spec.selector field defines how to find pods to manage as part of this ReplicaSet—in this case using MatchLabels
- The .spec.template field specifies how to create new pods in this ReplicaSet—containers using the nginx image on Docker Hub. New containers are named nginx.
To create a deployment using this example, run this command:
kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yaml
To check deployment status:
- Run kubectl get deployments to see if the new deployment has been created.
- Run kubectl rollout status deployment/nginx-deployment to see rollout status of replicas in this deployment.
- Run kubectl get rs (ReplicaSet) to see ReplicaSets created by the deployment.
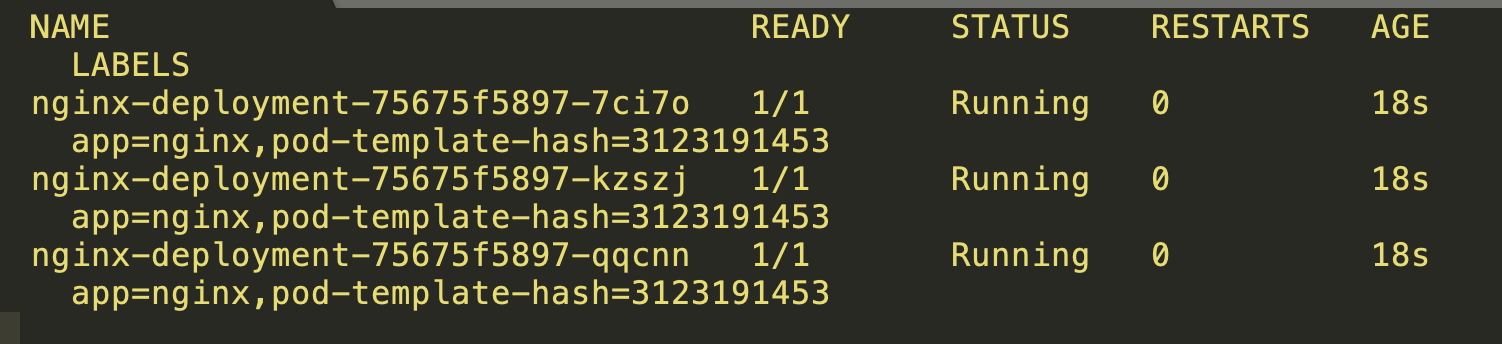
- Run kubectl get pods –show-labels to see which labels were generated for the pods within the ReplicaSet.
The final output of pods running in the ReplicaSet will look like this:
Automating Kubernetes Infrastructure with Spot
Spot Ocean from Spot frees DevOps teams from the tedious management of their cluster’s worker nodes while helping reduce cost by up to 90%. Spot Ocean’s automated optimization delivers the following benefits:
- Container-driven autoscaling for the fastest matching of pods with appropriate nodes
- Easy management of workloads with different resource requirements in a single cluster
- Intelligent bin-packing for highly utilized nodes and greater cost-efficiency
- Cost allocation by namespaces, resources, annotation and labels
- Reliable usage of the optimal blend of spot, reserved and on-demand compute pricing models
- Automated infrastructure headroom ensuring high availability
- Right-sizing based on actual pod resource consumption
Learn more about Spot Ocean today!