 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps
Ocean by Spot enables a serverless container infrastructure experience. Today, we are excited to deliver a configurable health check period for auto scaling nodes in order to increase the flexibility of Ocean to meet all of our customer’s needs.
When it comes to running containerized applications, every organization has their own unique set of dependencies. Whether it’s upgrading nodes on AMI (Amazon Machine Image) or Kubelet updates, installing observability agents (e.g. Datadog, NewRelic), or running Machine Learning workloads via GPU with custom packages like Nvidia libraries, meeting dependencies ensures that nodes are healthy. With startup times for infrastructure nodes varying due to these dependencies, a configurable health check ensures that nodes are ready and healthy for scheduling Kubernetes pods.
Previously, Ocean had fixed the health check period at 300 seconds, within which a node must declare itself as healthy. We have now enabled the ability to configure a grace period for every node auto scaled by Ocean. This will ensure that there are no false-positive nodes marked for replacement when they are simply taking (comparatively) longer to become healthy.
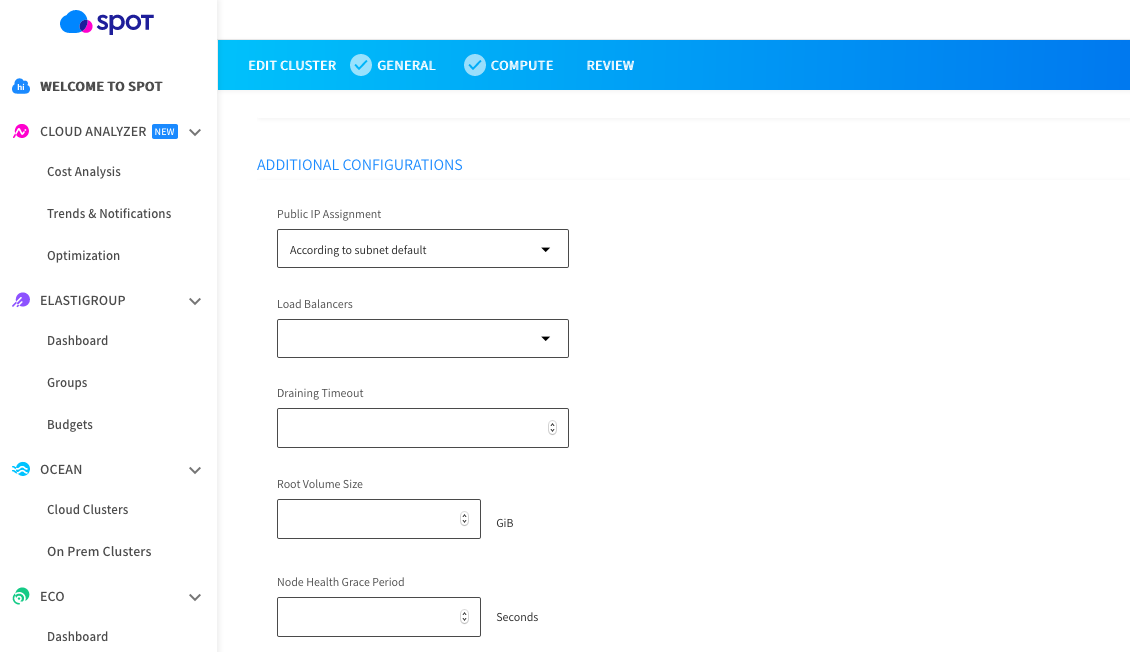
Configurable health check via Node Health Grace Period is available via console, under Edit Cluster:
Via API:
"strategy": {
"fallbackToOd": true,
"utilizeReservedInstances": true,
"drainingTimeout": 60,
"gracePeriod": 600
},
And via Terraform:
// --- STRATEGY -------------------- fallback_to_ondemand = true draining_timeout = 120 utilize_reserved_instances = false grace_period = 600 // ---------------------------------