 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOpsCompanies are embracing microservices and containers for their significant benefits to speed, agility and scalability in the cloud. Many are using Kubernetes as the de facto container orchestrator for deployment and operation of modern microservices. As a distributed system, the architecture of Kubernetes is flexible and loosely-coupled, with a control plane for managing the overall cluster, and the data plane to provide capacity such as CPU, memory, network, and storage so that the containers can run and connect to a network.
In this guide:
The Anatomy of Kubernetes
Kubernetes offers users a way to automate much of the manual tasks involved with operating containers such as autoscaling, resiliency management, metrics monitoring and more. All of that work is done within the Kubernetes cluster, which is made up of different components, each doing its part to operate and execute tasks in your container environment.
Related content: Read our guide to kubernetes monitoring.
The Control Plane
The control plane consists of the manager nodes in a Kubernetes cluster. Here, Kubernetes carries out communications internally, and where all the connections from outside— via the API—come into the cluster to tell it what to do. Container engines like Amazon EKS, Google GKE, and Azure AKS, (or alternatives to Kubernetes, i.e. Amazon ECS) are what the major public cloud providers offer by way of container orchestration services for Kubernetes.
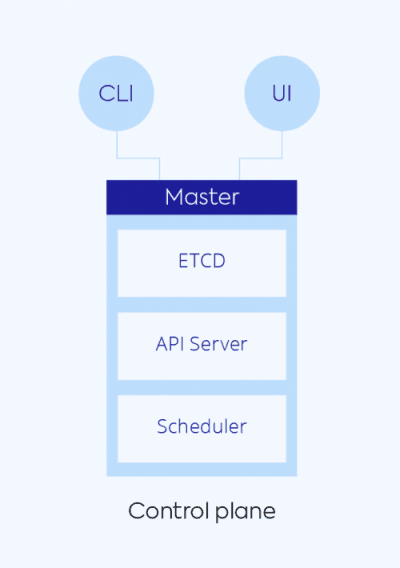
As a user, you’ll interact mostly with the control plane, which is where the cluster configurations, scheduling and communications happen. Although the control plane doesn’t scale very large, typically only using a few instances to run on, it is critical to running the entire cluster. The components listed below make up the control plane’s master node:
- etcd stores all the information about the configuration and state of the cluster
- API server is how a user interacts with the Kubernetes cluster through the CLI or UI
- The scheduler addresses the resourcing needs of the Kubernetes clusters and pods. It is responsible for assigning pods to worker nodes, taking into consideration all the possible constraints (i.e. compute/storage resources, desired connections between pods, etc.)
The Data Plane
If the control plane is the brains of Kubernetes, where all the decisions are made, then the data plane is the body. Worker nodes (i.e. VMs) on the data plane carries out commands from the control plane and can communicates with each other via the kubelet, while the kube-proxy handles the networking layer.
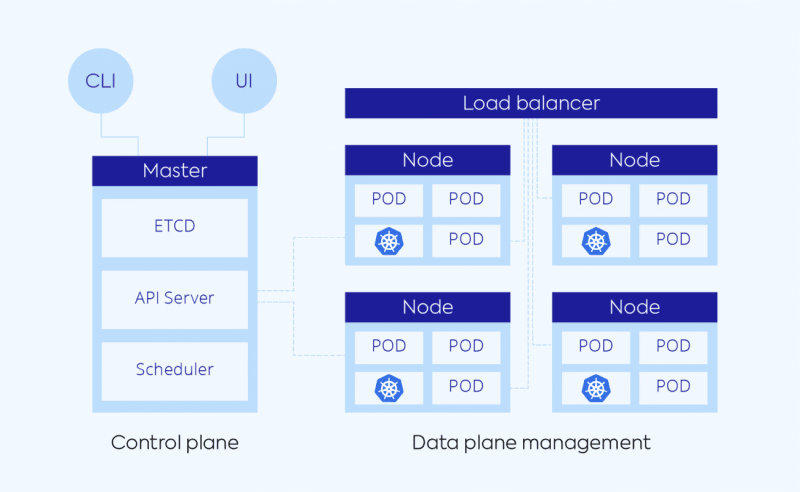
Inside the worker nodes are the pods, which share compute, networking and storage resources within each isolated pod. Containers are deployed within pods, and pods can scale across nodes as their application requirements change. For the different container engines there are different limitations to how many pods can run per node.
Learn more in our detailed guide to kubernetes cpu limit.
As Kubernetes was originally designed to manage applications on-prem, it natively offers pod scaling services, but doesn’t automatically scale infrastructure in the cloud. Kubernetes is scoped to the lifecycle of pods and will schedule them on any node that meets its requirements and is registered to the cluster. While this approach ensures that a node is healthy enough for a pod to run on, it can also result in significant inefficiencies inside the Kubernetes cluster.
With all the infrastructure (VMs or bare metal), workloads and dynamically scaling pods, the data plane, in contrast to the low capacity needs of the control plane, is where organizations will need the most compute capacity and see the most costs. It’s also where they can find the most efficiency by getting rid of waste. As a fully managed container infrastructure solution, Ocean by Spot fills this gap for Kubernetes environments, automatically provisioning compute infrastructure based on container and pod requirements.
Discover how far you can take your containers and learn more about what Spot Ocean can do for you.