 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOpsWhat Are Kubernetes Jobs?
Kubernetes simplifies the process of managing, scaling, and deploying applications across clusters of servers. Kubernetes Jobs are a resource within Kubernetes that helps schedule and automatically carry out batch tasks—short-term, one-off tasks that need to be run to completion.
A Job creates one or more pods (the smallest unit of management in Kubernetes, including one or more containers) and ensures that a specified number of them successfully terminate. For example, let’s say you have a script that needs to be run once a day. Instead of manually starting the script each day, or scheduling a regular cron job on a specific machine (which could fail or malfunction), you can create a Kubernetes Job to handle it automatically. The Job would start a pod, run the script, and then ensure that the pod successfully completed its task.
This is part of a series of articles about Kubernetes architecture
In this article:
Types of Kubernetes Jobs
Non-Parallel Jobs
Non-parallel Jobs are designed to run a single task to completion. They’re the simplest type of Job, but they’re also the most reliable.
Non-parallel Jobs are ideal for tasks that can’t be divided among multiple pods. For example, you might have a script that needs to be run once a day. A non-parallel Job would start a pod, run the script, and then ensure that the pod successfully completed its task.
Multiple Parallel Jobs
Consider a situation where you need to process a large batch of data. You could run a single Job to handle the entire batch, but this would be time-consuming and inefficient. Instead, you could use multiple parallel jobs to divide the workload among several pods, each processing a portion of the data.
Multiple parallel jobs allow you to leverage the power of Kubernetes’ distributed architecture. Your workload is spread across multiple nodes, allowing for faster processing and more efficient resource utilization.
Parallel Jobs with Fixed Number of Completions
This type of Job is similar to multiple parallel jobs, but with an important difference: they continue running until a specified number of tasks have successfully completed.
This type of Job is useful for tasks that need to be run a certain number of times. For example, you might have a test suite that needs to be run on several different configurations. You could create a parallel job with a fixed number of completions, and configure it to run the test suite on each configuration, ensuring that all tests are run the required number of times.
Related content: Read our guide to Kubernetes pod
How to Use Kubernetes Jobs with Code Examples
Creating and Configuring a Job
To create a Kubernetes Job, you will need to define it in a YAML or JSON configuration file. Here is a simple example of a Job configuration file:
apiVersion: batch/v1
kind: Job
metadata:
name: hello-world
spec:
template:
spec:
containers:
- name: hello-world
image: busybox
command: ["echo", "Hello, World!"]
restartPolicy: OnFailureThis configuration file describes a Job that runs a single pod with a container based on the busybox image. The command echo "Hello, World!" is executed in the container. If the container fails for any reason, Kubernetes will restart it because the restartPolicy is set to OnFailure.
A Kubernetes Job has a few configuration options, determined by the spec field in the Job manifest. This field contains several subfields that you can use to specify the behavior of the Job. The most important ones are:
completionssubfield: Determines the desired number of successfully finished pods a Job should have. For example, if you setcompletionsto 5, Kubernetes will ensure that five Pods have completed successfully.parallelismsubfield: Determines the maximum number of Pods that can run in parallel. For example, if you setparallelismto 2, Kubernetes will ensure that no more than two pods are running at the same time.
Schedule a Job
Kubernetes uses a resource called CronJob to schedule Jobs. A CronJob creates Jobs on a time-based schedule, as specified in cron format.
For example, you can create a CronJob that runs a Job every minute. Here’s an example of a CronJob configuration file:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello-world
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello-world
image: busybox
command: ["echo", "Hello, World!"]
restartPolicy: OnFailureThe schedule subfield uses the Linux cron format, which is explained here.
The above configuration file uses the schedule "* * * * *", which runs a Job every minute. The Job runs a single Pod with a container based on the busybox image. The command echo "Hello, World!" is executed in the container.
Learn more in our detailed guide to kubernetes job scheduler.
Running a Job
Running a Kubernetes Job is a straightforward process. Once you have your Job or CronJob configuration file defined, you can run it using the kubectl command-line tool.
For instance, to run a Job defined in a configuration file named job.yaml, you would use the command kubectl apply -f job.yaml. Kubernetes will then create the Job and schedule the Pods as specified in the configuration file.
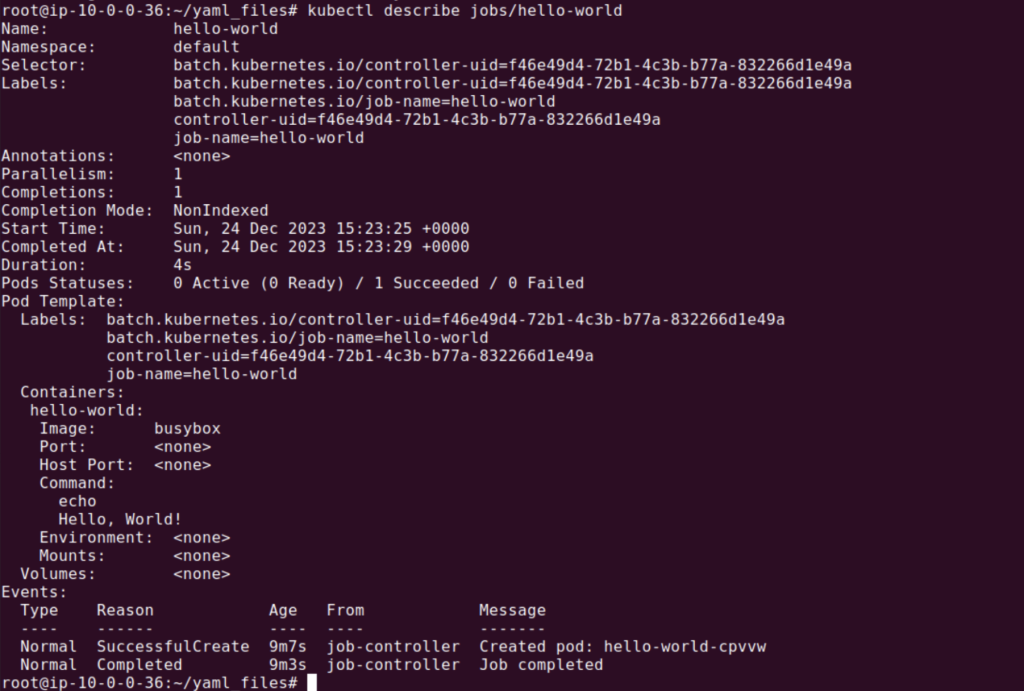
Once the Job is running, you can monitor its progress using the command kubectl describe jobs/<job-name>. This will display detailed information about the Job, including its current status and any events related to it.
Clean Up Finished Jobs Automatically
By default, Kubernetes does not delete finished Jobs. However, you can configure a Job or CronJob to automatically delete its finished Jobs by setting the .spec.ttlSecondsAfterFinished field.
This field determines the TTL (Time to Live) period for a Job, in seconds. Once a Job finishes, if this field is set, Kubernetes starts the TTL timer. When the TTL expires, Kubernetes deletes the Job.
Automating Kubernetes Infrastructure with Spot
Spot Ocean from Spot frees DevOps teams from the tedious management of their cluster’s worker nodes while helping reduce cost by up to 90%. Spot Ocean’s automated optimization delivers the following benefits:
- Container-driven autoscaling for the fastest matching of pods with appropriate nodes
- Easy management of workloads with different resource requirements in a single cluster
- Intelligent bin-packing for highly utilized nodes and greater cost-efficiency
- Cost allocation by namespaces, resources, annotation and labels
- Reliable usage of the optimal blend of spot, reserved and on-demand compute pricing models
- Automated infrastructure headroom ensuring high availability
- Right-sizing based on actual pod resource consumption
Learn more about Spot Ocean today!