 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOpsWhat Is Kubernetes VPA (Vertical Pod Autoscaler)?
Kubernetes VPA (Vertical Pod Autoscaler) manages the resource limits of pods in a Kubernetes cluster. It adjusts the CPU and memory reservations automatically based on usage, ensuring that pods receive the resources they need to operate effectively. This feature minimizes manual intervention and helps in maintaining the performance of applications.
VPA operates in three modes: Off, where it only provides recommendations, Initial, allocating resources at pod start, and Auto, adjusting resources as needed. This adaptability promotes efficiency and reduces waste, making it useful for dynamic, resource-sensitive environments.
This is part of a series of articles about Kubernetes architecture.
In this article:
- Components of VPA
- Kubernetes HPA vs. VPA: What Are the Differences?
- Kubernetes Vertical Pod Autoscaling Pros
- Kubernetes Vertical Pod Autoscaling Cons
- How to Use Kubernetes VPA, Step By Step
- Kubernetes VPA Best Practices
Components of VPA
Here’s an overview of Kubernetes VPA’s components.
Recommender
The VPA Recommender module evaluates the current and past resource usage against the defined requirements and recommends the necessary adjustments to a Pod’s CPU and memory requests. It uses historical usage data to predict future demands, ensuring pods are not over-provisioned or under-provisioned.
Using machine learning algorithms, the Recommender can accurately forecast needed resources even in complex applications. It updates its recommendations periodically, which allows continual adaptation to changes in workload patterns.
Updater
The VPA Updater checks for pods that require resizing and evicts them based on the current recommendations. It respects the Pod Disruption Budgets, ensuring that evictions do not violate specified application availability constraints. The Updater ensures that resource adjustments are effectively implemented in running pods.
This process is crucial for maintaining service stability and reliability during scale-ups. It makes sure that the application adapts to load changes smoothly without significant downtimes.
Admission Controller
The VPA Admission Controller modifies pod requests for CPU and memory at the time of creation based on the VPA recommendations. It ensures that no pod is created with resource limits that are too low or too high, maintaining efficiency from the start.
The controller interjects during the pod creation phase, overriding the container’s resource requests with values that align better with usage history and predictions. This ensures that applications perform optimally from the moment they are deployed.
Kubernetes HPA vs. VPA: What Are the Differences?
HPA (Horizontal Pod Autoscaler) increases or decreases the number of pod replicas based on CPU utilization or other application-provided metrics. It is useful in scenarios where the application load is variable and distributed across multiple instances.
VPA adjusts the CPU and memory resources of individual pods. Unlike HPA, which scales horizontally by modifying the number of pods, VPA scales vertically by tweaking the resources each pod requires. This makes VPA preferable in scenarios where adding more instances is not feasible or effective.
Kubernetes Vertical Pod Autoscaling Pros
There are several reasons to use VPA in Kubernetes:
Cost Efficiency and Stability
VPA can lead to significant cost savings and enhanced stability of applications. By efficiently allocating resources, VPA prevents overprovisioning, reducing unnecessary costs associated with unused CPU and memory. It ensures that applications are using just enough resources to function optimally without wastage.
Cluster Resource Optimization
VPA optimizes the utilization of underlying cluster resources by dynamically adjusting allocations based on workload requirements. Proper resource management also ensures that all pods within the cluster have adequate resources to perform their tasks, harmonizing operations and maintenance.
Elimination of Manual Benchmarking
Manual benchmarking of application resources is time-consuming and often imprecise. VPA eliminates this need by automatically analyzing and adjusting resource levels. This automation reduces the human effort required for capacity planning and continuous adjustment of resources.
Kubernetes Vertical Pod Autoscaling Cons
Here are some of the limitations associated with VPA in Kubernetes.
Incompatibility with Horizontal Pod Autoscaling
Vertical Pod Autoscaler (VPA) and Horizontal Pod Autoscaler (HPA) operate on different axes of scaling, which often leads to conflicts. VPA focuses on adjusting the CPU and memory limits of pods, whereas HPA scales the number of pods based on CPU utilization metrics. When both are used simultaneously, they can interfere with each other’s scaling decisions.
No Consideration of the Network and I/O
One major limitation of VPA is its exclusive focus on CPU and memory resources, ignoring network and I/O metrics. This oversight can lead to suboptimal scaling decisions in applications where network throughput or disk I/O are the bottlenecks. Without considering these metrics, VPA might increase CPU and memory where enhancing network bandwidth or disk throughput is required.
This lack of network and I/O consideration becomes particularly problematic in distributed systems where network latency and data transfer rates impact overall performance. By not optimizing these crucial resources, VPA may hinder the application’s capacity to handle data-intensive operations efficiently.
Use of Limited Historical Data
VPA primarily utilizes recent metrics for making scaling decisions, typically looking at the past few hours or days. This short-term focus might not accurately capture longer-term trends or repeating patterns in resource usage, potentially leading to under-provisioning during peak periods or over-provisioning during off-peaks.
The reliance on limited historical data means that VPA may not adjust optimally when faced with longer-term changes in application behavior. These could include changes due to seasonal usage variations or evolving user behaviors. Thus, some manual intervention might be necessary for effective scaling.
Related content: Read our guide to Kubernetes pod
How to Use Kubernetes VPA, Step By Step
Before we begin, install VPA in your Kubernetes cluster, see instructions here.
Step 1: Create a Deployment Object
To utilize Vertical Pod Autoscaler for managing resource recommendations, start by defining a Kubernetes Deployment. Below is an example using a YAML manifest where no specific CPU or memory requests are set initially. This example uses a basic NGINX deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
annotations:
scheduler.alpha.kubernetes.io/node-selector: "NODE NAME"
spec:
containers:
- name: nginx
image: nginx:1.7.8
ports:
- containerPort: 80
Step 2: Define a VPA for the Deployment
Here’s how you define the VPA for the deployment. Note that this configuration does not apply the recommendations automatically, because the update mode is set to Off.
apiVersion: autoscaling.k8s.io/v1beta1
kind: VerticalPodAutoscaler
metadata:
name: my-nginx-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-nginx
updatePolicy:
updateMode: "Off"
Step 3: Check VPA Recommendations
Once you have applied the above configurations, you can check the VPA recommendations using the following command:
kubectl describe vpa nginx-deployment-vpa
The output will include recommended resource requests similar to this:
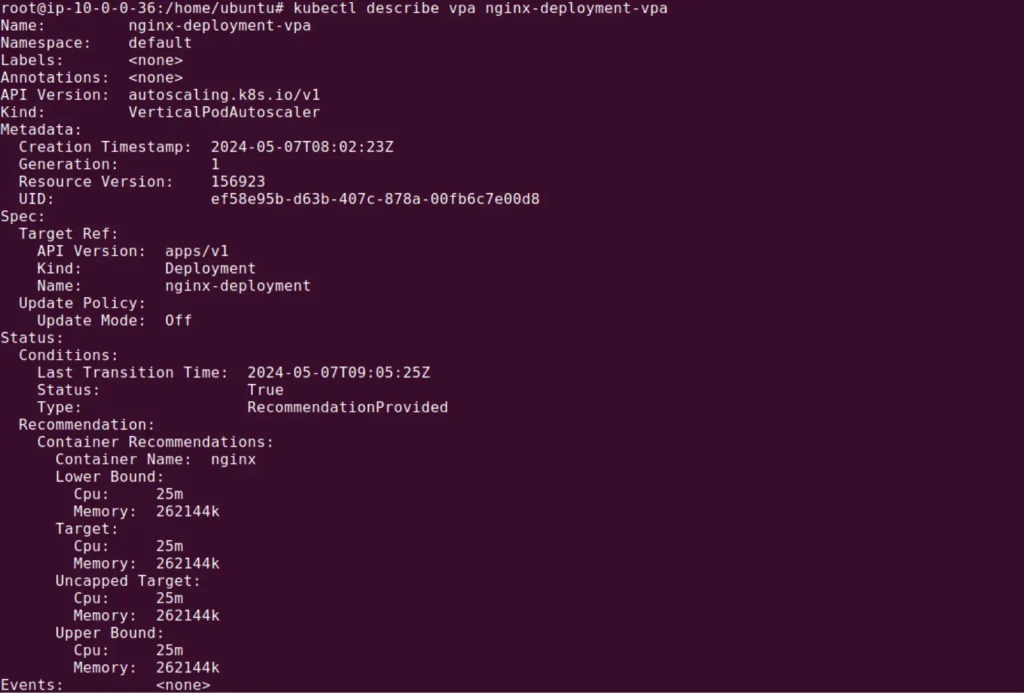
You can manually apply the VPA recommendations by updating the pod manifest with the appropriate requests and/or limits.
For non-production environments, or after carefully testing the functionality, you can choose to set the UpdateMode to Auto. This will allow VPA to automatically update the resource requests based on current usage. This setting makes the pods restart with updated resource values, reflecting the new requirements:
spec:
updatePolicy:
updatedMode: "Auto"
Kubernetes VPA Best Practices
Here are some tips for making the most of VPA in Kubernetes.
Enable VPA for Critical Workloads
For workloads that are crucial to your business operations, enabling VPA can ensure that these applications always have the necessary resources to perform optimally. Critical applications that experience variable loads benefit from VPA’s dynamic allocation, helping maintain performance without manual tuning.
By analyzing real-time metrics, VPA adjusts resource allocations, keeping crucial applications responsive under different load conditions. This automatic adjustment helps maintain service quality and avoid downtime or degraded performance, especially during unexpected spikes in demand.
Use Predefined Policies and User-Defined Thresholds
Using custom scaling policies allows for finer control over how resources are allocated. User-defined thresholds also help in maintaining a balance between performance and resource utilization, ensuring that pods use optimum resources without wastage. This helps in anticipating scaling needs based on historical usage patterns and planned traffic increases.
Combine with Other Kubernetes Components
Integrating VPA with other Kubernetes tools such as Cluster Autoscaler and Pod Disruption Budgets can enhance overall resource management. While VPA adjusts resources at the pod level, Cluster Autoscaler can add or remove nodes based on overall cluster needs, and Pod Disruption Budgets can ensure minimum availability during disruptions.
Automate the Capacity Optimization Process
VPA can be used to automate the optimization of capacity in your Kubernetes environment. By setting VPA to automatically adjust resource allocations based on actual usage, you can ensure optimal deployment of your infrastructure resources. Automation in VPA also removes the need for constant manual tuning and monitoring.
Related content: Read our guide to Kubernetes monitoring
Automating Kubernetes Infrastructure with Spot
Spot Ocean from Spot frees DevOps teams from the tedious management of their cluster’s worker nodes while helping reduce cost by up to 90%. Spot Ocean’s automated optimization delivers the following benefits:
- Container-driven autoscaling for the fastest matching of pods with appropriate nodes
- Easy management of workloads with different resource requirements in a single cluster
- Intelligent bin-packing for highly utilized nodes and greater cost-efficiency
- Cost allocation by namespaces, resources, annotation and labels
- Reliable usage of the optimal blend of spot, reserved and on-demand compute pricing models
- Automated infrastructure headroom ensuring high availability
- Right-sizing based on actual pod resource consumption
Learn more about Spot Ocean today!