 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps
As the size and frequency of data pipelines scale, organizations are constantly looking for ways to reduce costs and more efficiently utilize their data infrastructure. As the leading managed platform for Spark on Kubernetes, we’ve helped several customers make the decision to move their Spark workloads to Ocean for Apache Spark, taking advantage of strategic spot instance selection, flexible pod configurations, and resource utilization tools that can correct overprovisioning.
Today, we’re excited to announce that Ocean for Apache Spark is now available to all customers within the Spot console. (Here you can find the complete guide to get started.)
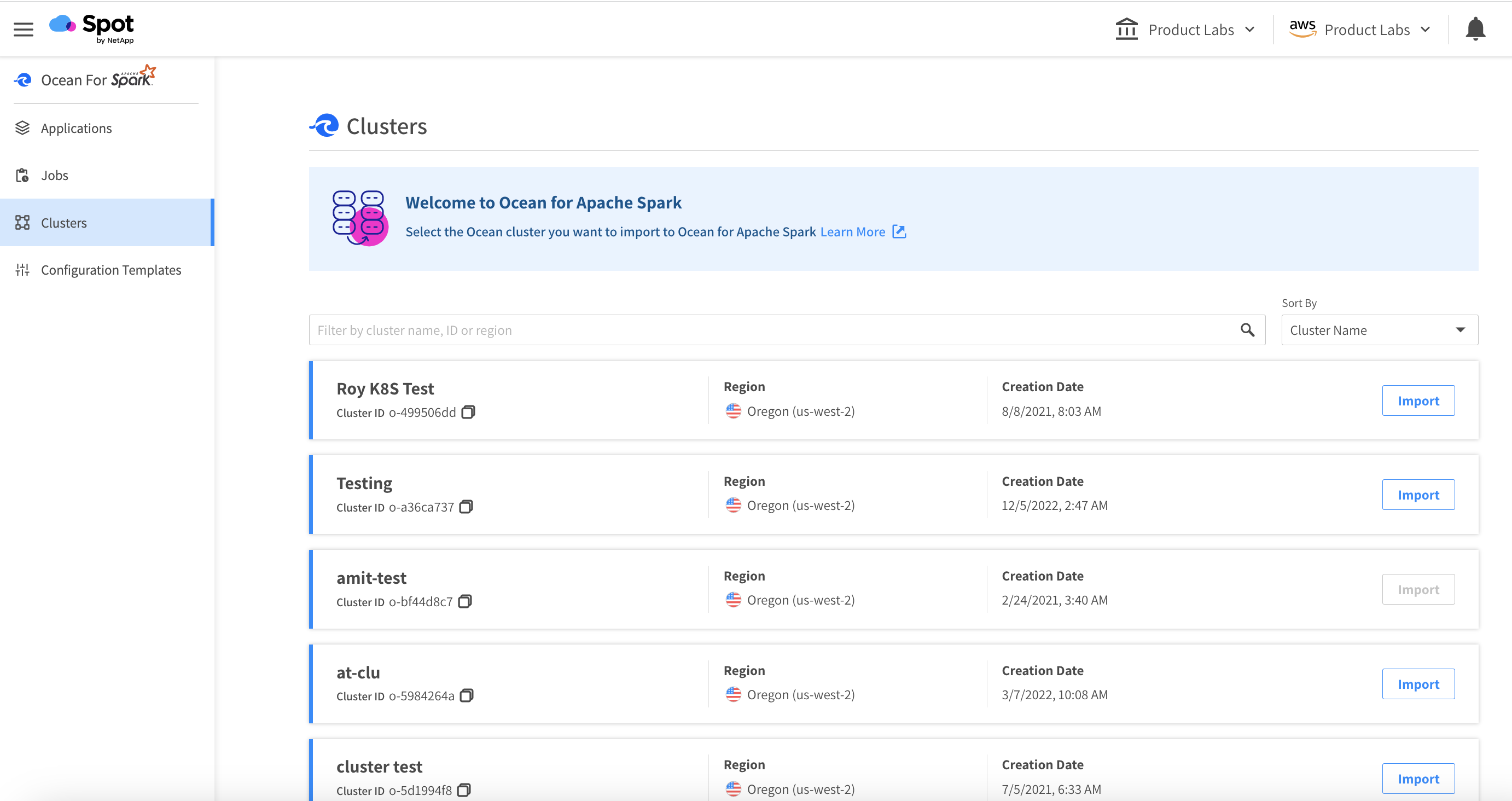
Spot by NetApp users can now easily begin their migration to Ocean for Apache Spark. You can even deploy directly into your existing Ocean cluster. Visit the Clusters tab in Ocean for Apache Spark, and you will be prompted to choose the Ocean cluster to import. You can also choose from one of our many terraform modules to find the deployment that matches your cloud provider and cluster configuration.
Why Ocean for Apache Spark?
Lower application costs, while improving reliability, availability
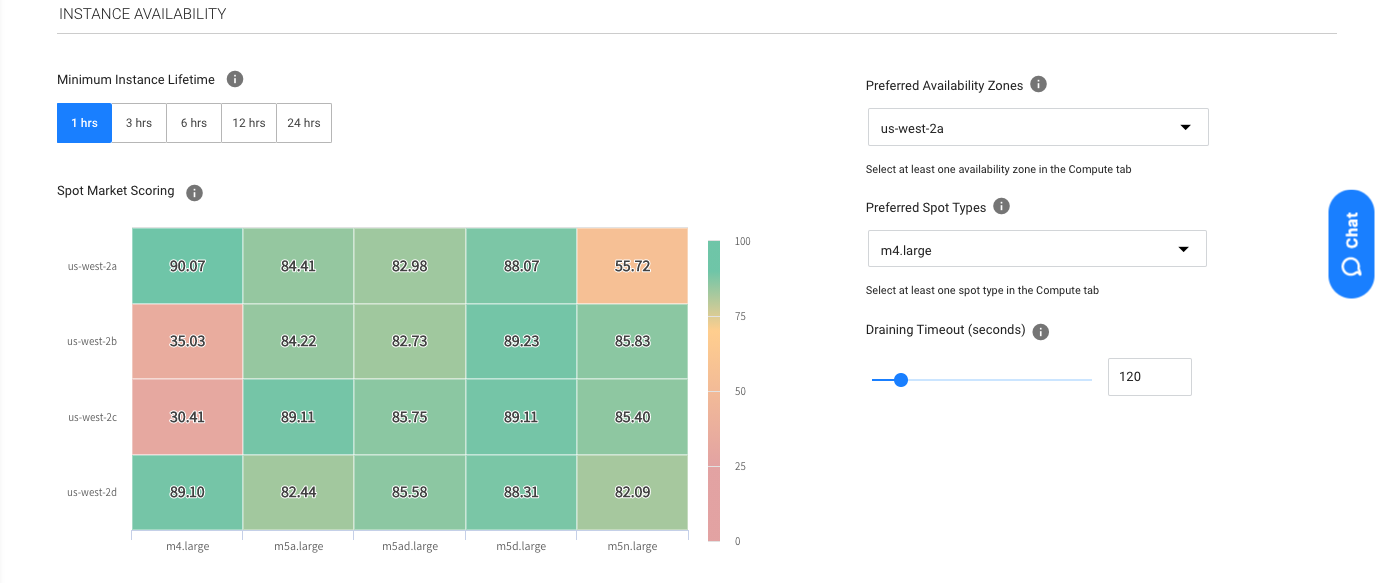
Leveraging Ocean’s intelligent spot instance selection, Ocean for Apache Spark removes the need to pair applications with specific instance types, allowing Ocean to choose at runtime the spot instance type that has the highest availability, lowest price, and lowest likelihood of a spot kill. This flexibility can improve application duration and reduce spot kills by up to 79%.
Gain insight into Spark application performance
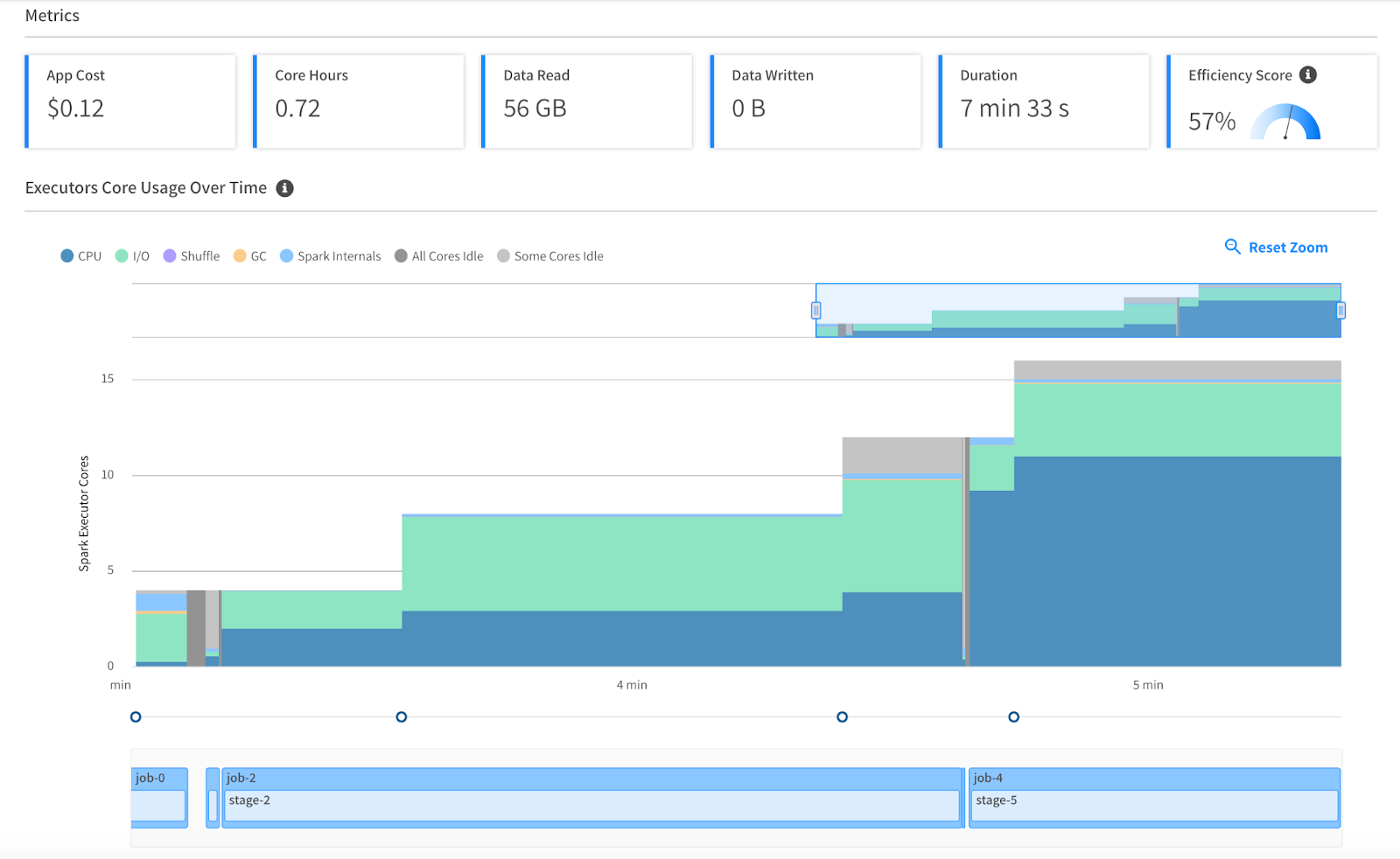
We recognize that Spark development and debugging can be challenging, and we’re here to help! With our resource utilization tools, you can understand exactly how your Spark application is performing, identify which resource (I/O, memory, CPU, garbage collection) is affecting application execution and resolve the bottleneck more efficiently. Additionally, we organize your application logs — driver, Kubernetes and executor — as well as maintain the Spark history server so you can always access the Spark UI.
Integrate your existing data tools
Ocean for Apache Spark supports the execution of Jupyter notebooks (including JupyterHub and JupyterLab), and integrates with schedulers like Airflow, AWS StepFunction, and Azure Data Factory. We have a robust REST API that not only makes it easy to submit Spark applications from anywhere, but also provides application-level metrics like data read/written, shuffle data, CPU utilization, and cost that can enable meaningful monitoring and alerting.
By building on top of open-source, cloud-native technology, Ocean for Apache Spark also natively interfaces with the popular tools from the Kubernetes ecosystem — observability, networking, security, cluster-management, and more.
Cost Transparency
It’s too often the case that the only awareness and insight into the cost of Spark applications comes with the monthly bill; you shouldn’t need to build a complicated ETL pipeline to extract the data from your cloud provider. Luckily, we’ve done most of the hard work for you! Our cluster cost analysis dashboard provides historical cost data at the job and application level, so you can understand exactly how much your Spark workloads cost. This data can be viewed in the Ocean for Apache Spark console, downloaded as a CSV, or extracted from the API.
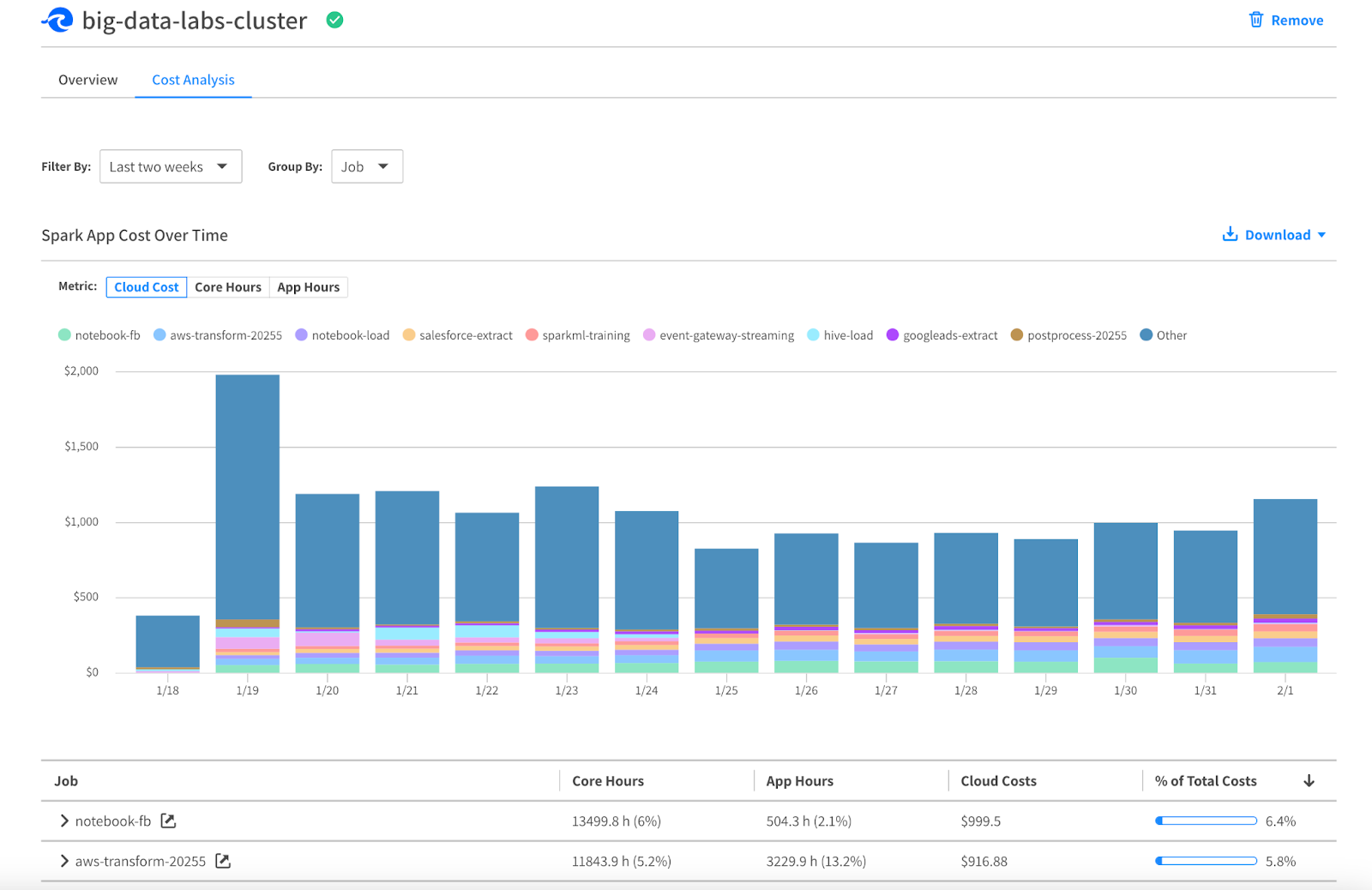
Get started with Ocean for Apache Spark
We’ve helped many customers migrate their Spark workloads to Spark on Kubernetes and take full advantage of all that Ocean for Apache Spark has to offer.
Don’t just take our word for it. Statisticians around the world from the United Nations Global Big Data Platform leverage Ocean for Apache Spark to simplify their work and reduce their costs. And the data integration product Lingk.io migrated from EMR to Ocean for Apache Spark and achieved high savings while improving their end-users’ experience.
If you or your team are interested in learning more, please schedule a time with our team of Spark experts to discuss your use case and determine if Ocean for Apache Spark is right for you.