 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

The utilization of spot instances can be one of the fastest and easiest ways to drastically reduce the compute costs of your Spark infrastructure when you run in the cloud. In this article, we will discuss two techniques specific to Spark on Kubernetes, Enhanced Spot Instance Selection and Executor Decommissioning, that can both remove some pitfalls of spot instances and increase the reliability of your compute – resulting in faster, cheaper applications.
What are spot instances?
Most cloud providers separate their compute offerings into two categories, on-demand and spot instances. On-demand instances work effectively like owning the instance; you retain sole possession of the compute for as long as you are paying, and the instances cannot be recalled until you choose to shut it down. Spot instances are more similar to rentals; you maintain full control of the compute instance for an undetermined amount of time, but they can be recalled by the cloud provider at any moment to be returned to the marketplace and allocated to another account. We call this recall process a spot kill. When a spot kill occurs, the cloud provider will send a message to the instance, usually 60-120 seconds prior to removal, to notify any applications or processing running on the machine so that they can properly shut down or move any pertinent data out of local storage.
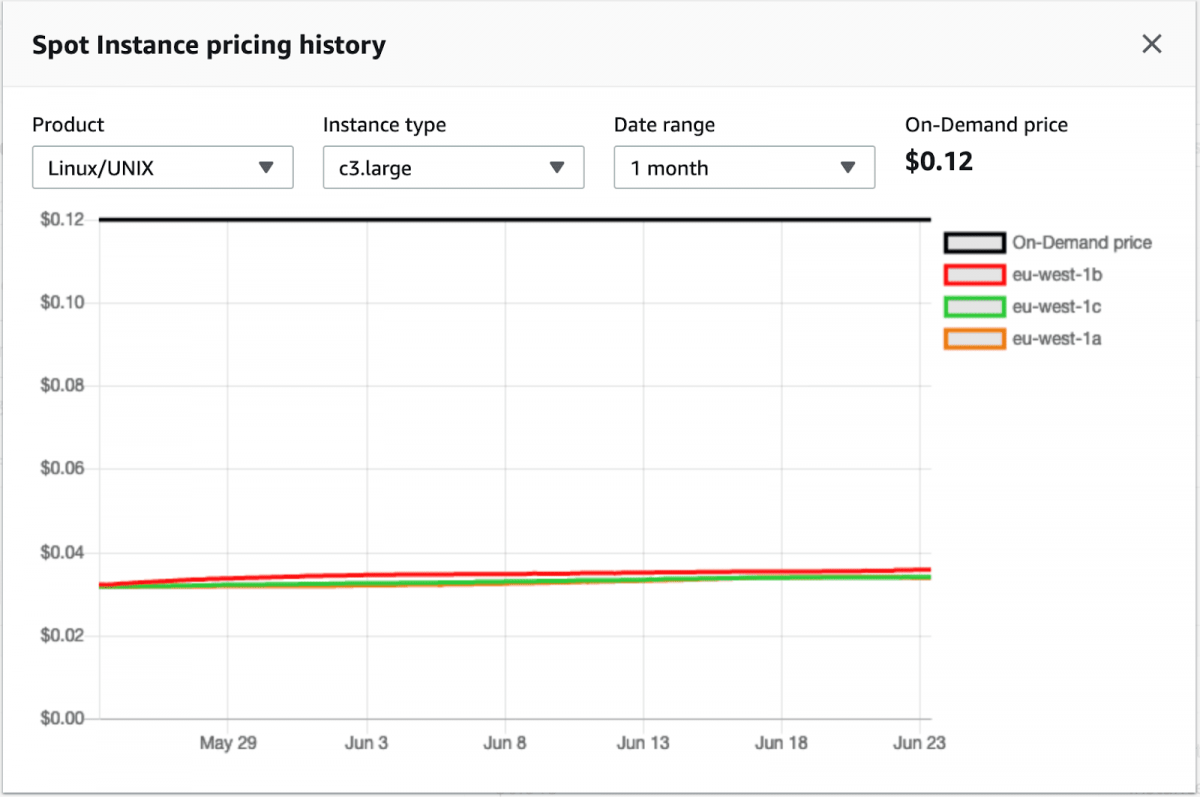
You may be wondering, “If spot instances can be recalled at any moment, why would I choose to use them?” And the answer is simple – cost. Spot instances are drastically cheaper than using on-demand instances. There are many factors that determine the price of a spot instance such as instance type, size, region, availability zone, or even time of day, but on average, spot instances will let you save 60-90% of costs compared to on-demand instances.
How does Apache Spark work with spot instances?
While it is certainly advantageous from a cost perspective to incorporate spot instances, it doesn’t come without added work. Utilizing spot instances requires a slightly different design to how your applications handle state or intermediary calculations that are stored on the device’s local storage. Additional thought must be given to data recovery and persistence, so that when a spot kill occurs, your applications can quickly pick up where they left off, without losing any work or data in the process.
An Apache Spark application is made of:
- A Spark Driver, which is the brain of the application. The driver is not resilient to spot kills, so it’s critical to run it on an on-demand instance.
- A (usually large) number of Spark executors, on which Spark tasks are executed in parallel (distributed programming).
Spark was designed to be resilient to losing executors, which make them suitable to run on spot instances. When Spark receives a spot kill notification from the cloud provider, it quickly stops the departing Executor from completing any future tasks and updates the event log so that other Executors can pick up where the previous Executor left off, without duplicating any previously finished work. Effectively, your application continues to work asynchronously while the lost executors scheduled tasks are reorganized.
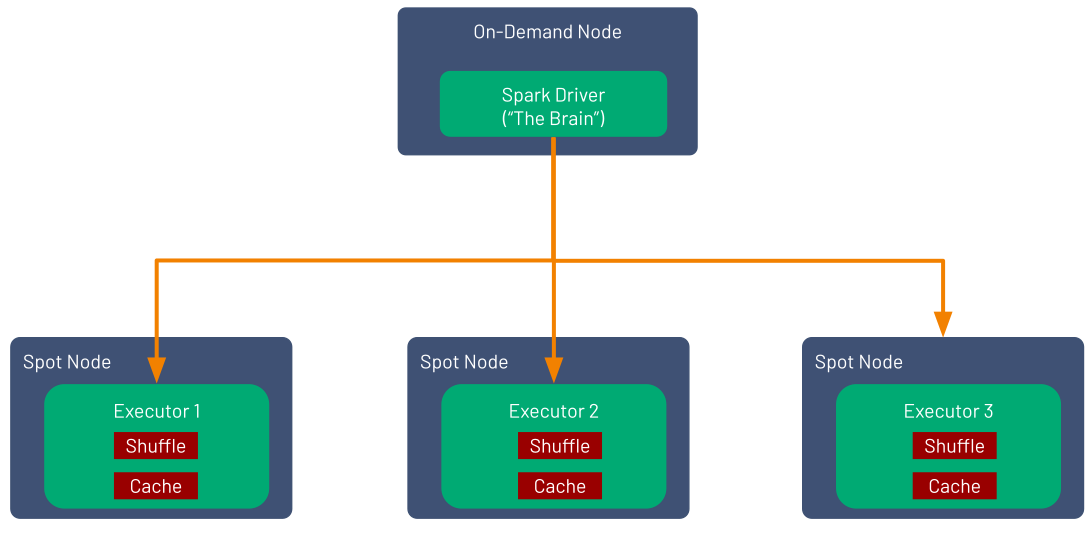
While Spark may efficiently reallocate executor tasks, this isn’t the case for data or intermediate results that are stored on disk. If there are intermediate DataFrames or cached results that Spark requires for future tasks or stages in the application, Spark will have to re-execute the previously completed work so that it can recompute the necessary data. Depending on the complexity of the tasks that need to be computed, this process can add significantly to your application’s runtime.
So we’ve determined that spot kills are bad and should be avoided as much as possible to fully realize the value of spot instances. How can we do this?
Enhanced spot instance selection
Ocean for Apache Spark is a fully managed, continuously optimized, Spark-on-Kubernetes service that can be deployed in your cloud account. Ocean for Apache Spark is built on top of Ocean, the serverless containers engine from Spot.io which optimizes the autoscaling of Kubernetes clusters and aid in spot instance selection.
One feature that’s particularly useful is Spot Market Scoring. With Spot Market Scoring, Ocean uses a variety of data points such as availability, price, and spot kill likeliness to create a range of scores across different instance types and availability zones. Spot then selects the best instance type for your application’s workload depending on the resources, generally memory and cpu, that you request from Ocean.
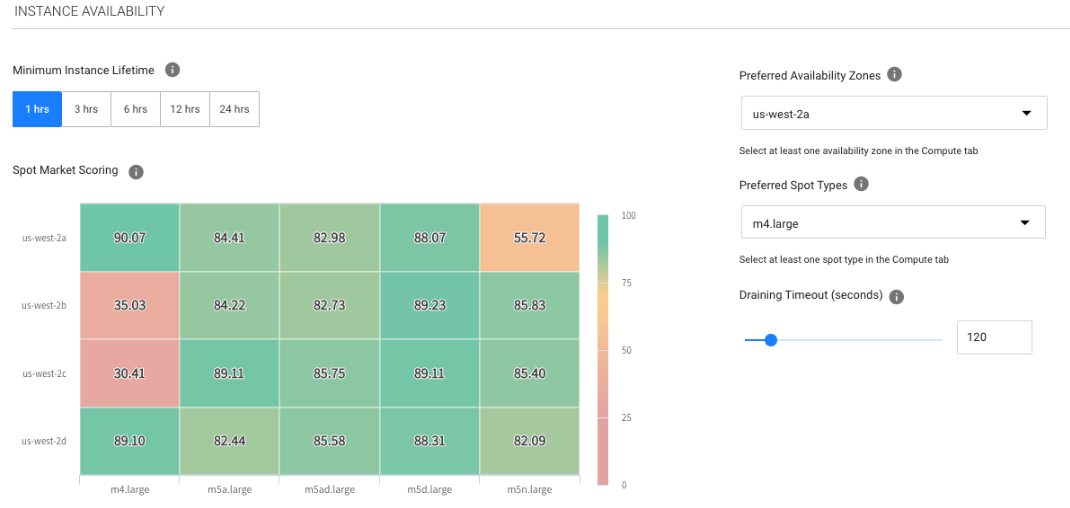
Ocean for Apache Spark has incorporated this Spot selection flexibility directly in our platform.
The example Spark application below requests:
- A Driver with 2 CPU cores, running on an on-demand instance.
- 10 Executors with 4 CPU cores each, running on spot instances from one of the r5, r5d, r4 or i3 instance families.
App spec
{
“driver”: {
“cores”: 1,
“spot”: false
},
“executor”: {
“instanceAllowList”: [“r5”, “r5d”, “r4”, “i3”]
“cores”: 4,
“instances”: 10,
“spot”: true
}}
This configuration gives Ocean a degree of freedom to pick the best availability zone and the best instance types that satisfy your workload requirements and have the highest availability, cheapest price, and lowest likelihood of a spot kill – thanks to its predictive Spot Market scoring algorithms.
For example, the configuration above – which is requesting 40 cores on spot instances in total, could be satisfied by:
- 1 i3.4x large instance (with 16 cores)
- 1 r5.2xlarge instances (with 8 cores)
- 2 r5.xlarge instances (with 2 cores each or 8 cores total)
- 2 r4.xlarge (with 2 cores each or 8 cores total)
There’s an additional benefit of mixing multiple instance types: it follows the “Don’t put all your eggs in one basket” principle. Even if spot kills happen on one specific spot market, with this configuration, you are unlikely to lose many of your executors at once.
To put this functionality to the test, we ran an experiment to test the effectiveness of the Spot Instance selection. We ran a batch ETL application running in approximately 1 hour, every hour, for two weeks under two separate configurations: a static configuration where the only allowed instance type was m5.xlarge, and an optimized configuration where instanceAllowList accepted the entire m5 family. Both applications had the following config:
- 1 driver (1 core, on-demand), 10 executors (4 cores each, spot)
- Spark executor task consist of sleeping for 55 minutes, such that the application runs in about one hour, if no spot interruption occurs.
Here were the results:
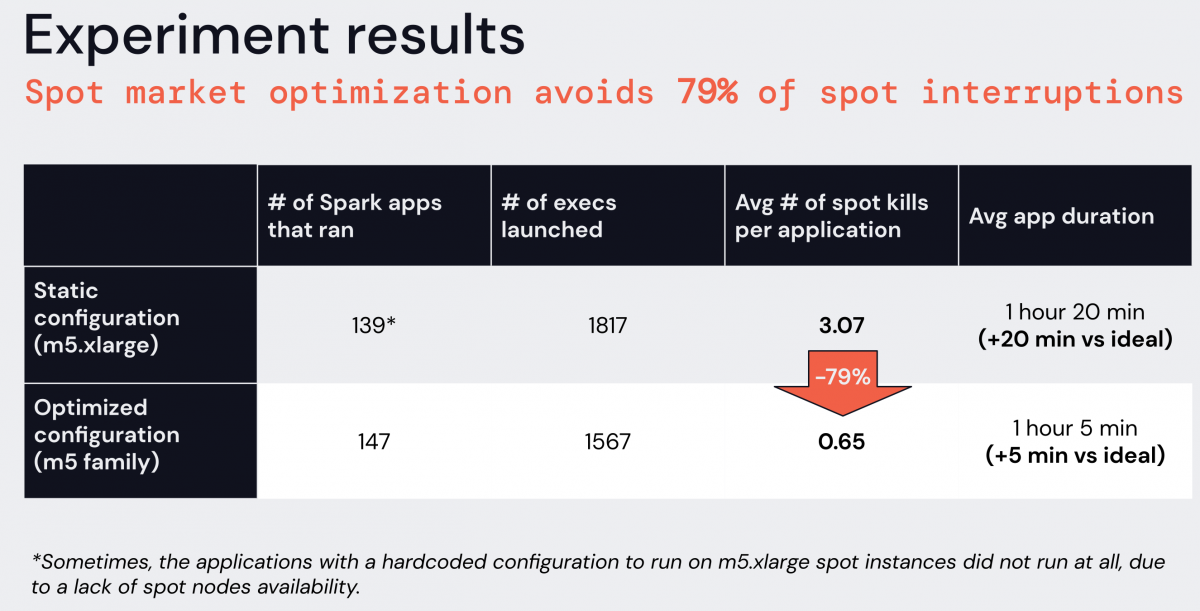
The application configured to use the instance family selector received 79% less spot kills than the one hardcoding a specific instance type. This finding confirmed that the use of multiple instance types and availability zones significantly increased the reliability of spot instances. In addition, as a result of fewer spot kills, we also observed reductions in repeated Spark tasks and stages, S3 calls, application runtime, and overall application costs.
Graceful executor decommissioning
As mentioned earlier, when executors are recalled as a result of a spot kill, tasks logs are transferred from the departing executors to the remaining executors, but any data that is persisted in local storage, such as shuffle data or persisted DataFrames, will be lost, which will result in the re-execution of tasks if this data is a requirement for downstream tasks. This data loss would result in longer instance recovery time and slower application performance.
Thanks to Graceful Executor Decommissioning, released only for Spark-on-Kubernetes in 2021 with Spark versions 3.1, we now have a better solution. With Decommissioning enabled, when Spark receives the spot kill notification from the cloud provider, it will attempt to move any data that is stored or persisted on the recalled node, and distribute it to another executor(s) within the application. Once the executor and node are officially removed, Spark will determine if the data transferred from the decommissioning process is sufficient or continue, or it will reprocess any data that was not able to be transferred.
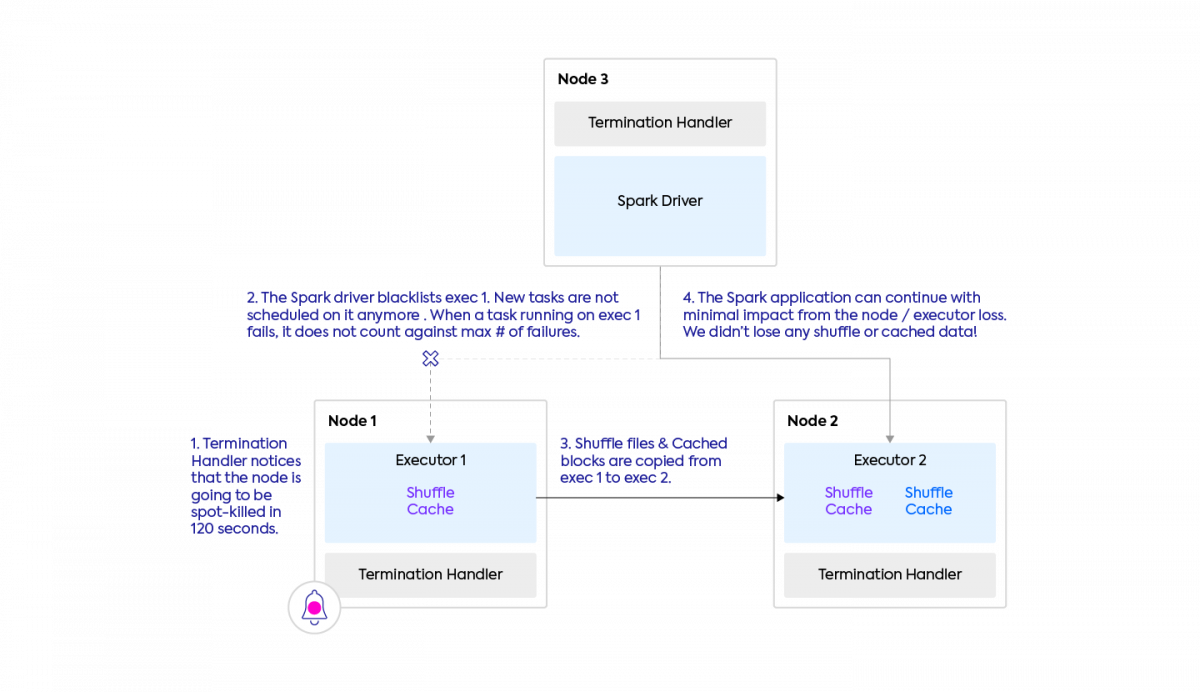 To get a better understanding of the capabilities of Graceful Executor Decommissioning, we ran a series of experiments to load test the transfer process. We ran several applications using 4 core executors, testing out different instance types, memory ratios, and executor numbers. The following process was followed:
To get a better understanding of the capabilities of Graceful Executor Decommissioning, we ran a series of experiments to load test the transfer process. We ran several applications using 4 core executors, testing out different instance types, memory ratios, and executor numbers. The following process was followed:
- We created a Spark application that generated a significant amount of shuffle files
- We simulated the process of receiving a spot kill by detaching the nodes containing the executor pods from the cluster, with a grace period of 120 seconds (same as AWS)
- Using the Storage tab in the Spark UI and parsing information from the driver and executor logs, we could measure
- The data stored on the executors prior to detachment
- The data moved from one executor to another during decommissioning
- The time Spark spent moving files
On average, Graceful Executor Decommissioning moved ~15GB/minute of shuffle data on regular instances, and 35-40GB of data/minute on SSD-backed instances.
Conclusion
Ocean for Apache Spark makes Spark-on-k8s run reliably on spot instances in 3 ways:
- Running the Spark driver on on-demand nodes, and the executors on spot. This can be controlled by a boolean flag that you can set on each application.
- Optimizing the availability zone and instance types on which to run your Spark workloads, according to a predictive algorithm scoring spot markets. Our experiments proved that 79% of spot kills could be avoided this way.
- Enabling the Executor Decommissioning feature out of the box for Spark 3.1+, to mitigate the impact of a spot kill by proactively saving shuffle files and cached data, during the 2 min notice before a spot kill occurs.
To learn more about Ocean for Apache Spark, schedule a time to meet our team of Spark-on-Kubernetes experts – we look forward to learning more about your use case and needs, and build solutions to address them together.