 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOpsWhat is EC2 Auto Scaling?
Amazon EC2 Auto Scaling is a feature that ensures the right number of Amazon EC2 instances are available for an application’s load. It helps maintain application availability and lets you automatically add or remove EC2 instances. Auto Scaling can also detect if there is an error or failure on an instance and immediately launch another instance to maintain the required capacity. The goal is to maintain the performance of the system and reduce costs by only using the resources that are actually needed.
Amazon EC2 also lets you define dynamic auto scaling policies, based on load metrics, CloudWatch alarms, events from other Amazon services such as SQS, or a fixed schedule.
EC2 Auto Scaling is made up of three components: a launch template to know what to scale, scaling policies that define when to scale, and an Auto Scaling Group (ASG) that decides where to launch the EC2 instances. EC2 Auto Scaling is part of the AWS Auto Scaling service, which provides automatic scalability for several Amazon services.
There is no additional charge for AWS Auto Scaling. You pay only for the AWS resources needed to run your applications and Amazon CloudWatch monitoring fees.
The basic steps involved in using EC2 Auto Scaling are:
- Sign into the AWS Management Console
- Create a launch template
- Create an Auto Scaling group
- Add Elastic Load Balancers (optional)
- Configure Scaling Policies (optional)
Learn more in our quick start section below.
In this article, you will learn:
- What is EC2 Autoscaling?
- EC2 Auto Scaling Components
- How Does EC2 Auto Scaling Work?
- Getting Started with EC2 Auto Scaling
- 4 AWS EC2 Auto Scaling Best Practices
- EC2 Autoscaling with Spot.io Elastigroup
EC2 Auto Scaling Components
EC2 Auto Scaling is made up of three components: a launch template to know what to scale, an Auto Scaling Group (ASG) that decides where to launch the EC2 instances, and optional scaling policies that define when to scale.
Auto scaling groups (ASG)
Groups organize EC2 instances into logical units, used for scaling or management purposes. When creating an auto scaling group, you can specify the minimum, maximum, and preferred number of EC2 instances you need.
Learn more in our guide to EC2 auto scaling groups
Launch templates
The launch template is a new way to configure auto scaling, replacing launch configurations, which are still supported as a legacy option.
Launch templates specify configuration information for new instances created in an auto scaling group. This includes the Amazon Machine Image (AMI) to use when creating the instance, security groups, and key pair.
You can use versioning to create a subset of the set of parameters and reuse it to create additional launch templates. You can, for example, create a default template that specifies common configuration values, and programmatically insert different values that create new versions of the template.
Scaling policies and other options
EC2 Auto Scaling provides several ways to scale an instance group:
- Manual scaling—attaching or detaching instances to the auto scaling group.
- Maintaining a defined number of instances—scaled according to your specifications for minimum, maximum, and preferred or desired number of instances.
- Target tracking—enables dynamic scaling according to a specified load metric target value.
- Step scaling policies—specify several thresholds of a certain metric, and perform a scaling job when each threshold is reached.
- Simple scaling policies—decrease and increase the capacity of the group by a specific instance number or percentage.
- Scaling based on SQS—scaling up a group based on load in an SQS queue.
- Scheduled scaling—performing a scaling event during specific dates and times.
How Does EC2 Auto Scaling Work?
The EC2 instance in an autoscale group has a different lifecycle than other EC2 instances. The lifecycle begins when the auto scaling group launches instances, or an instance is manually added to a group. The lifecycle ends when an instance ends or the group removes an instance and terminates it
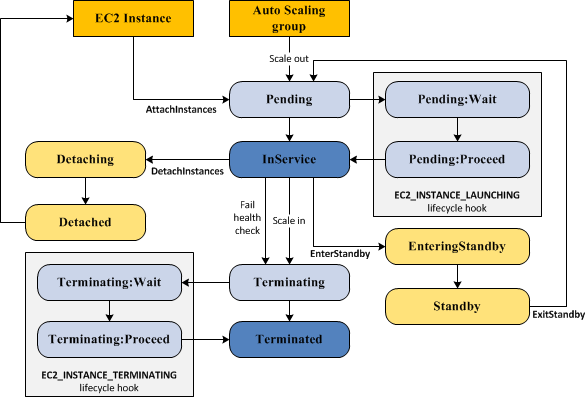
Source: AWS
Scale Out
Several events, known as “scale out events”, initiate a process that tell the auto scaling group it should launch new compute instances and add them to the group:
- Group size is manually increased
- A scaling policy is active, which automatically increases group size when a policy criterion was met
- A scheduled scaling event was set
When one of these events happens, the auto scaling group creates new instances, using the group’s launch configuration. New instances are initially launched in Pending status, and you can add lifecycle hooks to automatically perform an action when they are created.
Instances in Service
After an instance is created and any lifecycle hooks are executed, it enters the InService status. It remain in this state until any one of the below events occur:
- A “scale in” event that causes the scaling group to terminate the instance, in order to reduce its size
- A user manually puts the instance into Standby
- A user manually detaches the instance from the group
- The instance fails a health check several times and is removed from the group, destroyed, and replaced by a new instance
Scale In
The following “scale in” events cause an auto scaling group to remove an instance from the group and destroy it:
- A user reduces the size of the group
- A scaling policy automatically reduces the size of the group, when a certain criterion is met
- A scheduled event was defined to scale down the group at a given time
Be sure to define a scale-in event for every scale-out event—to prevent unchecked scaling and instance sprawl.
It is important to note that there is no additional charge for AWS Auto Scaling. You pay only for the AWS resources needed to run your applications and Amazon CloudWatch monitoring fees. However, in some cases EC2 Auto Scaling can result in high charges due to high load on applications. You can define scaling policies or use cost control options such as Usage Budgets to limit your costs.
Related content: Learn more in our guide to AWS autoscaling pricing
Getting Started with EC2 Autoscaling
Here are the basic steps involved in using EC2 autoscaling for your applications.
Step 1: Log into the AWS Management Console
Get started by creating an account and signing into the AWS Management Console. If this is your first time using AWS, you might be eligible to use EC2 at no cost, with certain limits, according to the terms and conditions of the AWS Free Tier.
Step 2: Draft a Launch Template
Navigate to the Amazon EC2 Console and click Launch Templates. Provide a name for the new launch template, the Amazon Machine Image (AMI) to run, instance types, and other options. You can also define a security group, which allows you to set up a virtual firewall for your instances.
When setting up your first launch template, in order to be eligible for the free tier, you can select the Amazon Linux 2 AMI and T2.micro instance.
Step 3: Create an ASG
Use the Auto Scaling wizard to create an Auto Scaling group. Follow the wizard steps to select the name, size, and network of the ASG.
Step 4: Integrate Elastic Load Balancers (Optional)
You can use Auto Scaling with Amazon Elastic Load Balancing (ELB), to evenly distribute incoming traffic among Amazon EC2 instances within your Auto Scaling groups. This can provide fault tolerance for your application. To do this, set up ELB for your application and connect it to your Auto Scaling group. ELB will distribute traffic between instances as they scale up and down.
Note that the primary step is to create the load balancer.
Step 5: Set Up Scaling Policies (Optional)
Configuring scaling policies for your Amazon EC2 Auto Scaling group allows you to determine around how and when the ASG should scale up or down.
You can set up scaling policies to initiate scaling events when CloudWatch alarms get triggered. For instance, you can specify that if the average CPU utilization of your instances goes beyond 80%, an additional instance should be launched (scale-out event). Conversely, if the utilization drops below 20%, an instance can be removed (scale-in event).
The three main types of scaling policies you can apply are target tracking scaling, simple scaling, and step scaling. Learn more about scaling policies in the official documentation.
4 AWS EC2 Auto Scaling Best Practices
Here are several best practices that can help you manage EC2 scaling more effectively.
EC2 Instance Frequency
Ensure Amazon EC2 Auto Scaling is defined on load metrics that have a frequency of one minute. This enables a faster response to changes in application usage. Using a scaling metric with frequency of five minutes slows response time, and can result in scaling events based on old data.
By default, EC2 provides basic monitoring, which tracks metrics every 5 minutes. For Auto Scaling based on EC2 metrics, it is recommended to enable detailed monitoring, which updates metrics every minute. Note this incurs an additional charge.
Auto Scaling Group Health Check
Make sure that the health check feature is configured correctly to detect that EC2 instances registered with an auto scaling group are functioning normally. Otherwise an auto scaling group cannot perform basic functions like removing and replacing failed instances.
If you are using Amazon Elastic Load Balancer (ELB) to distribute traffic between instances in an auto scaling group, make sure that ELB health checks are enabled (this works at the hypervisor and application level).
Predictive Scaling Forecast
Predictive scaling uses workload forecasting to plan future capacity. Predictions will be of higher quality if workloads have a cyclical performance pattern. Try running predictive scaling in “forecast only” mode, to evaluate the quality of the predictions and scaling actions the policy generates. If you are satisfied with the predictions, set the policy to “forecast and scale”.
Auto Scaling Group Notifications
If you don’t have any other monitoring mechanism for auto scaling, make sure your auto scaling group is configured to send email notifications upon scale out or scale in events. When notifications are enabled, an AWS SNS topic associated with the auto scaling group receives scaling events and sends notifications of scaling events to the email address you specified during the setup process.
EC2 Autoscaling with Spot.io Elastigroup
Elastigroup provides AI-driven prediction of spot instance interruptions, and automated workload rebalancing with an optimal blend of spot, reserved and on-demand instances. It lets you leverage spot instances to reduce costs in AWS, even for production and mission-critical workloads, with low management overhead.
Key features of Elastigroup include:
- Predictive rebalancing—identifies spot instance interruptions up to an hour in advance, allowing for graceful draining and workload placement on new instances, whether spot, reserved or on-demand.
- Advanced auto scaling—simplifies the process of defining scaling policies, identifying peak times, automatically scaling to ensure the right capacity in advance.
- Optimized cost and performance—keeps your cluster running at the best possible performance while using the optimal mix of on-demand, spot and reserved instances.
- Enterprise-grade SLAs—constantly monitors and predicts spot instance behavior, capacity trends, pricing, and interruption rates. Acts in advance to add capacity whenever there is a risk of interruption.
- Intelligent utilization of AWS Savings Plans and RIs—ensures that whenever there are unused reserved capacity resources, these will be used before spinning up new spot instances, driving maximum cost-efficiency.
- Visibility—lets you visualize cluster activity and costs, with live views of potential and actual costs, resource utilization, and running instances. You can set budgets per cluster and receive notification alerts about budget deviations.
- Application aware—matches scaling behavior to the type of workload, can add or remove servers from load balancers, use health checks to monitor health, and provide excess capacity for stateful applications without risking data integrity.