 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOpsScale mission-critical workloads on spot instances. Availability guaranteed.
Dramatic cost reduction with maximum efficiency for both stateless and stateful workloads running in AWS, Azure and Google Cloud.

With Elastigroup we can confidently run thousands of spot instances for our core technologies without needing to touch any aspect of our deployment.


Cost-optimized, highly available and hands-free infrastructure scaling


Use cases that fit your
infrastructure
In addition to applications that run as part of an AWS Auto Scaling Groups or Azure ScaleSet VMs, Elastigroup natively supports many other stateless and stateful workloads such as these:
STATELESS
Batch jobs
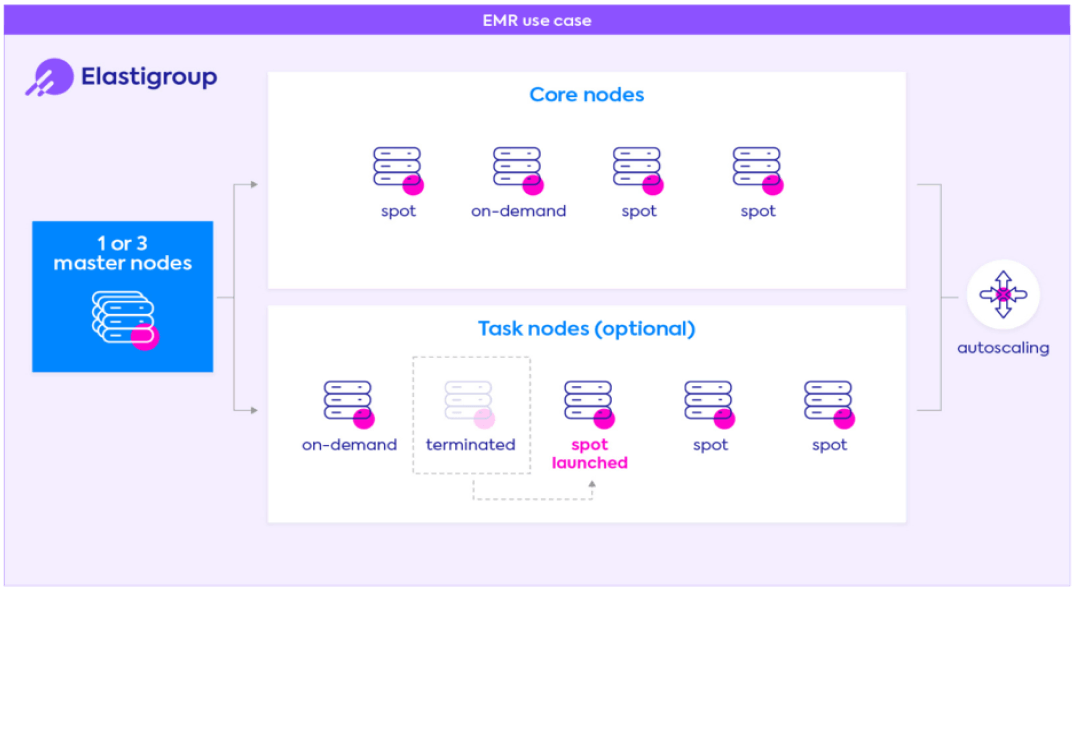
Run core and/or task nodes on spot instances for long and short running EMR clusters, ensuring zero disruption and sufficient IPs within all selected AZs.
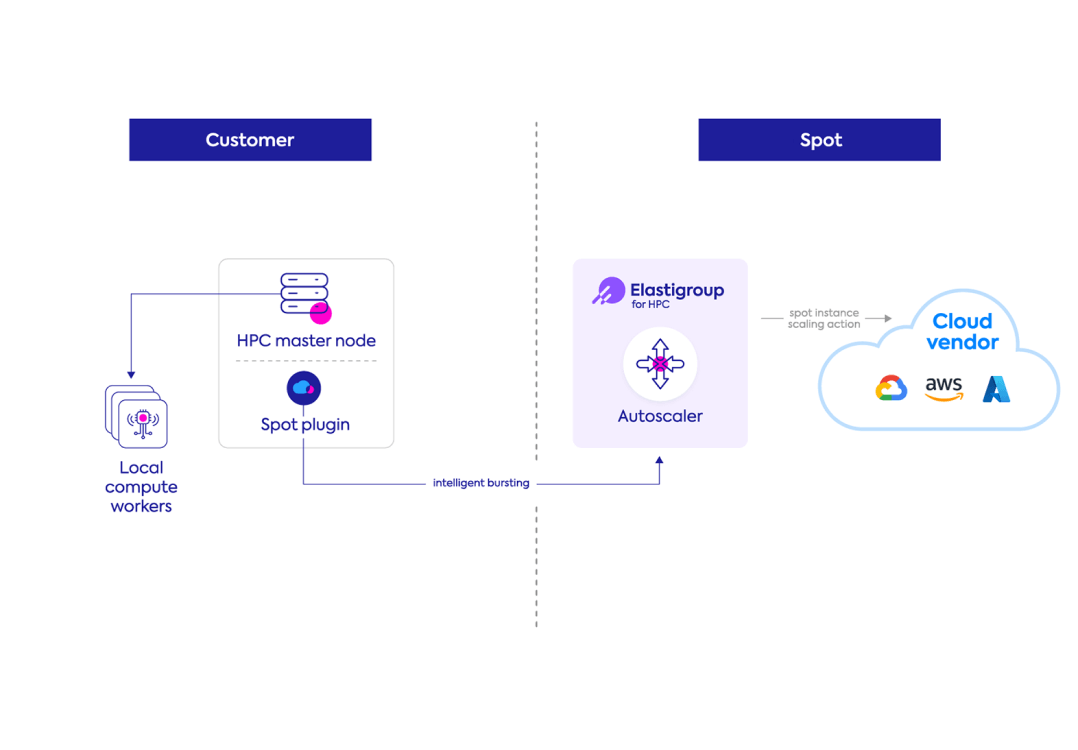
HPC workloads
Burst onto highly available spot instances with specific simple/target policies and HPC cluster scaling requests. Run pre/post scripts to automatically register newly created spot instances and gracefully deregister old ones.
Cloud native load balancers
Elastigroup supports Amazon ELB/ALB and Azure Application Gateway, adding an application-aware auto scaling and prediction layer to mitigate spot interruptions while running on the most optimal compute price and size.
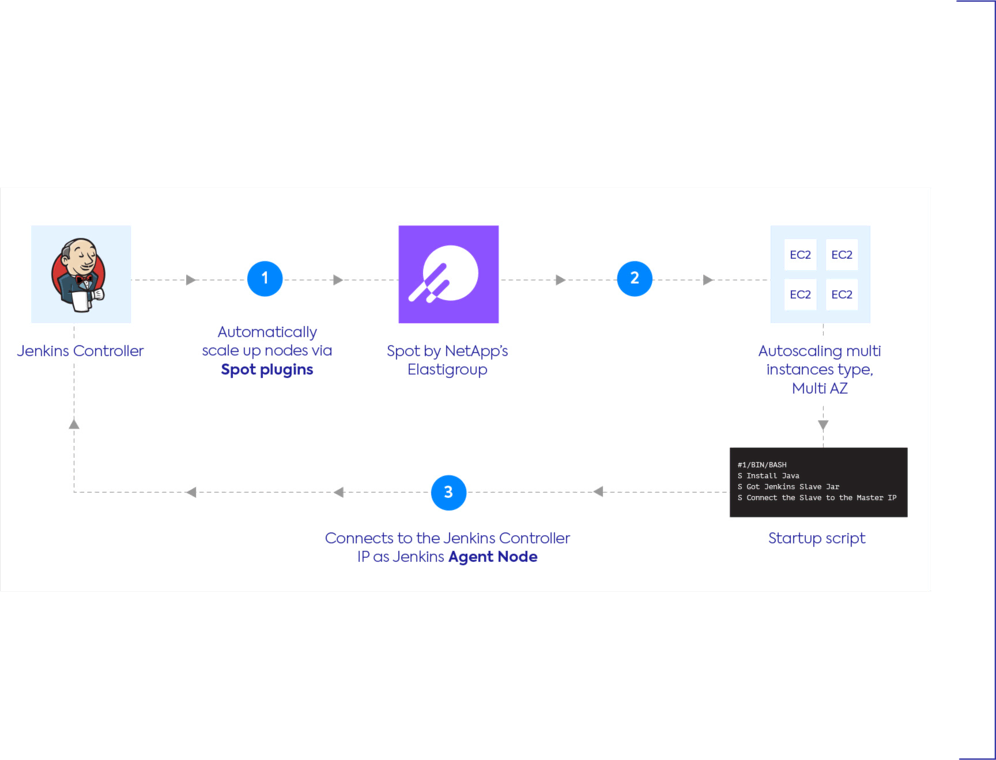
CI/CD integration
With Spot’s Jenkins plugin, easy Websocket configuration and streamlined connection enables reliable provisioning of the exact number of spot instances needed all with optimized utilization.
STATEFUL
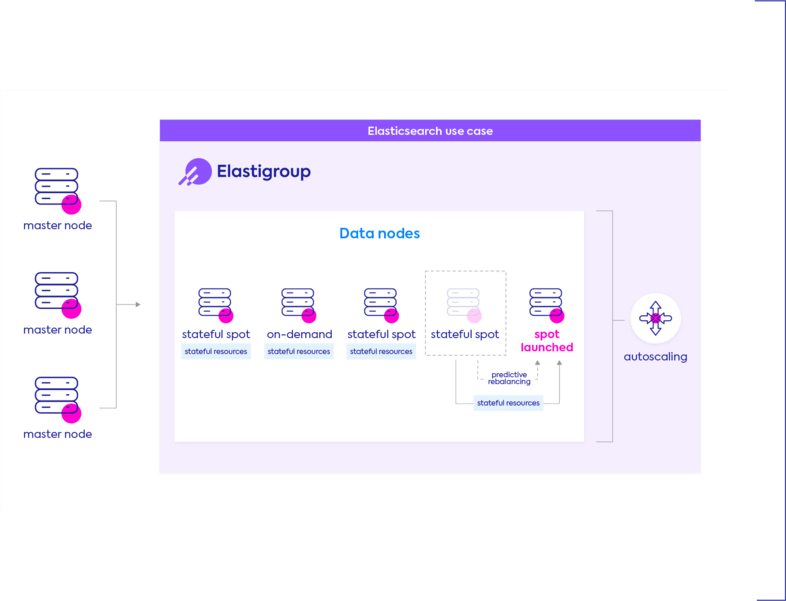
Big data
With data and IP persistence, instance auto-recovery, automated data, cross-AZ multiple shard environments and more, reliably utilize spot instances for highly cost-optimized big data clusters.
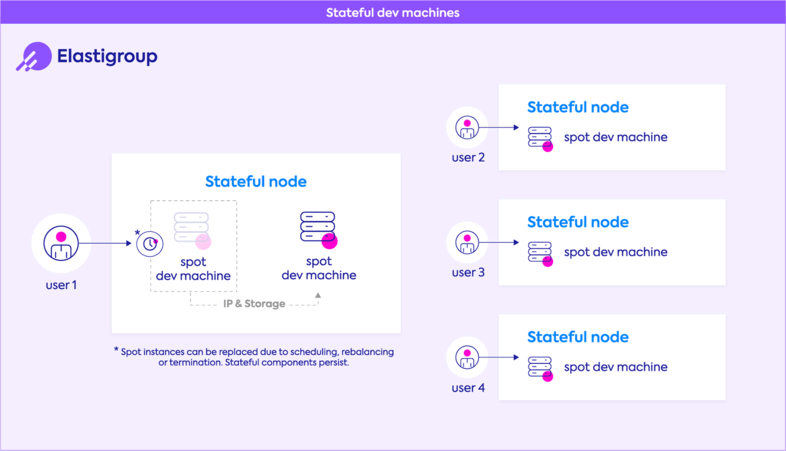
Dev machines
Elastigroup drives innovation by allowing unfettered usage of personal development machines with data and IP persistence even on spot instances. Built-in scheduling helps further reduce cost with full control over when instances run.
Key features





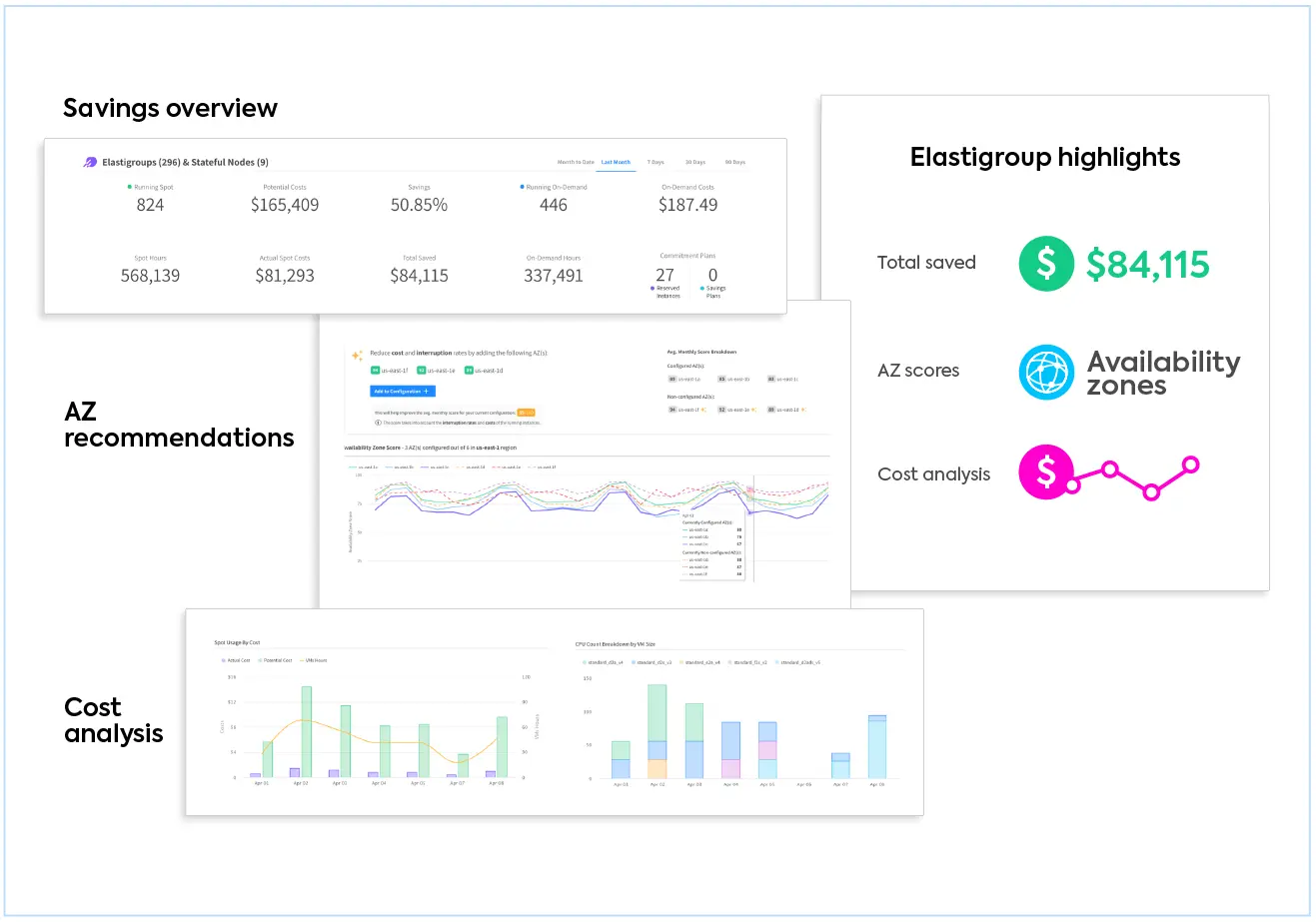
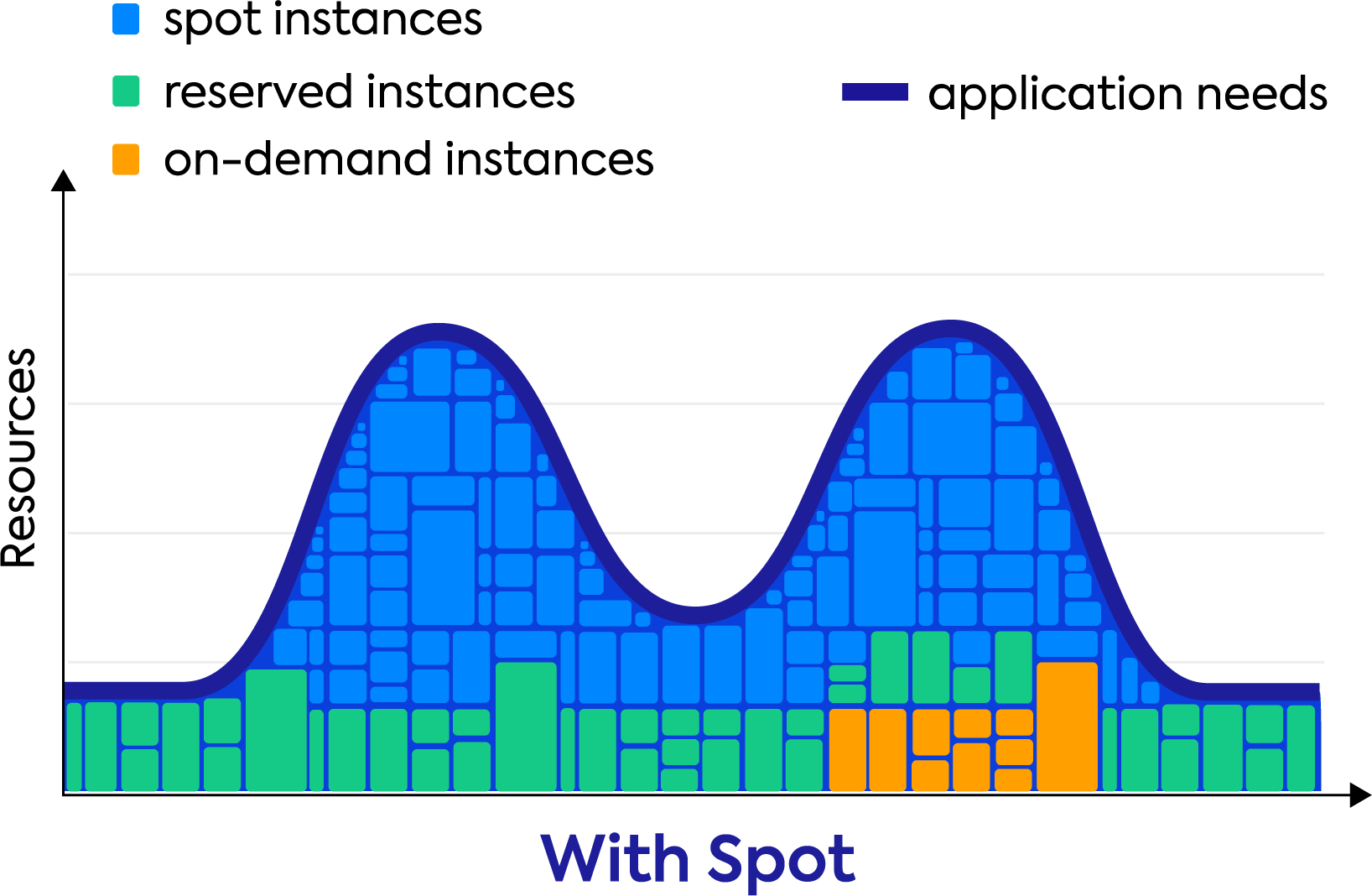
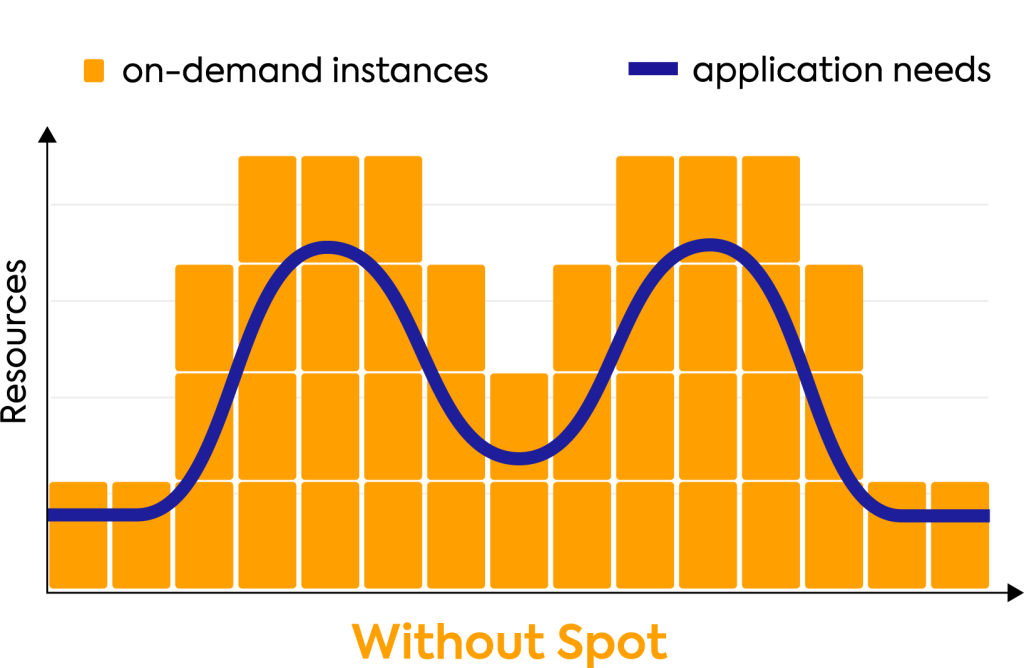
Optimize compute costs by up to 90% cost with the optimal balance of spot, reserved and on-demand pricing, providing the most cost-effective and highly available cloud compute on earth.
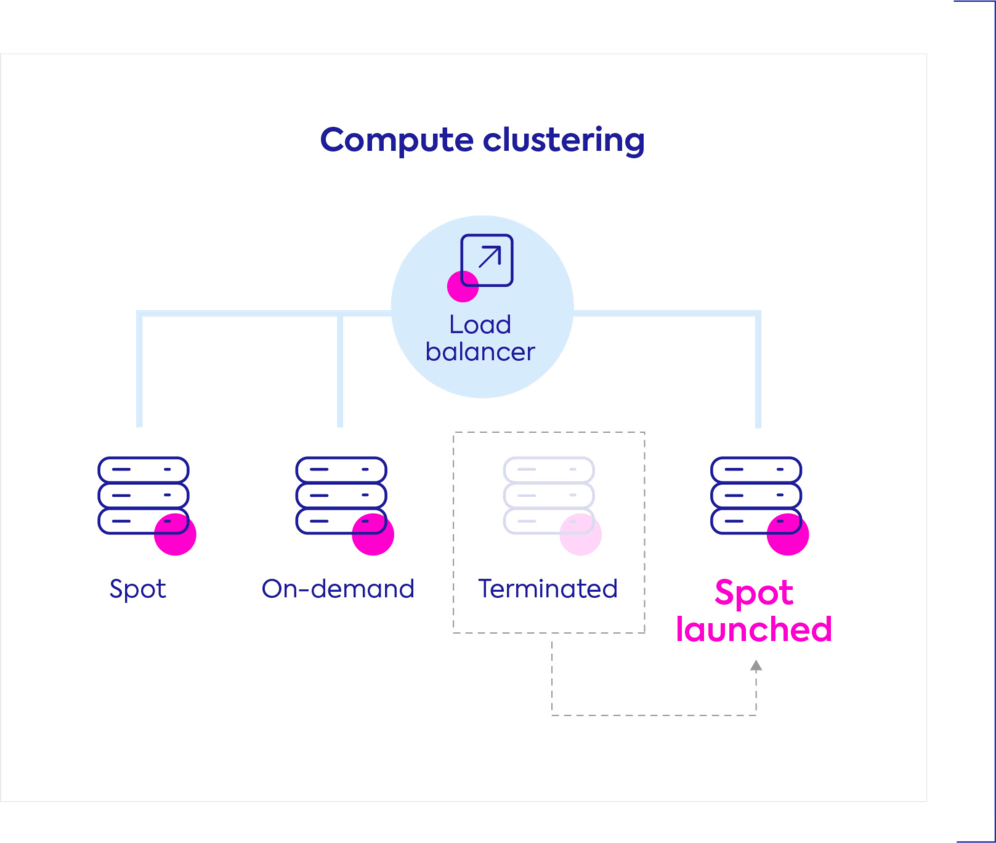
Enhanced abilities to optimize clusters by intelligently distributing incoming traffic across cloud resources to maximize instance utilization and achieve high performance. Select as many instance types and sizes while traffic is automatically balanced across the cluster without manual intervention

Risk-free provisioning with AI-driven autoscaling and proactive replacement of at-risk spot instance ensuring enterprise-level SLAs and SLOs.
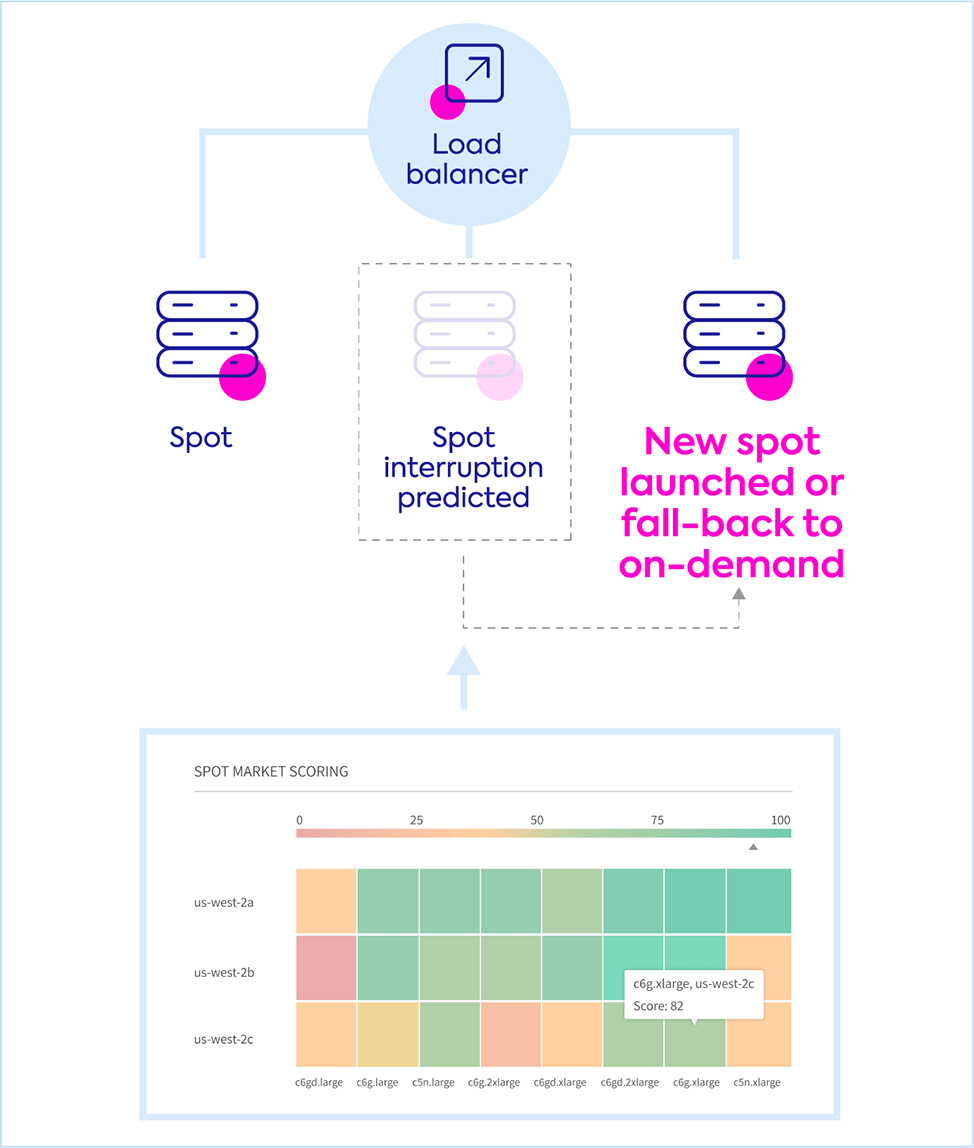
Avoid over provisioning while your workloads benefit from application-driven infrastructure management that leverages cloud compute pricing models and automated cluster scaling based on your workload’s requirements.
Built-in integration with broad range of cloud solutions allows you to continue working as usual with the most popular CI/CD, configuration management, IaC and other DevOps tools available.
Up to 90% cost savings
Intelligent traffic flow
High availability by design
Application-aware infrastructure scaling
Plug and play, bring your own software