 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

“Spot instances are too transient for persistent workloads,” or so most think.
Even DevOps pros who are running production workloads on spot instances don’t believe they can be a fit for databases or stateful applications. Or at least not without reworking their architecture to a large degree.
Spot, however, enables users to run any workload without a single point of failure on spot instances with an SLA guaranteeing high-availability.
Here’s how to run 4 workloads that demand consistency and data integrity on spot instances:
1. Stateful applications on spot instances
As long as your stateful application can tolerate a maintenance window (i.e night hours/ weekends), you can run it on spot instances using Elastigroup. In case of a spot instance interruption, Spot will try to restart or launch your spot instance on a different Availability Zone, Instance Type or even on a different pricing model such as on-demand to maintain your application availability.
Check out our guide for running Elasticsearch on Kubernetes
2. Running persistent NoSQL DBs
From MongoDB to Cassandra, running databases on spot instances is not the most obvious solution. But with Spotinst, it is possible to run persistent databases on spot instances. Today, we have dozens and dozens of customers running persistent databases on spot instances.
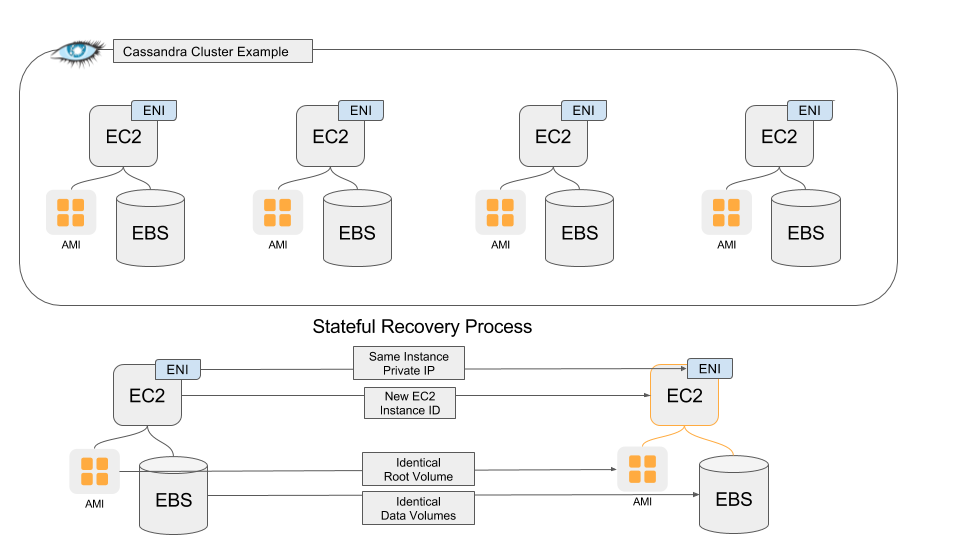
In the case of Cassandra, for example, it works as follows: If a Cassandra node is replaced, we automatically clones the instance and data to reboot it as a new instance before there is a spot instance interruption. At the same time, the cloning of the previous instance ensures that cluster IOPs are not wasted on bringing a new instance up.
For MongoDB, you can utilize their replica sets to run MongoDB workloads with 100% availability and data persistence on spot instances. In order to provide fault tolerance, MongoDB allows creating replica sets which are, essentially clusters of MongoDB servers that implement master-slave replication and automated failover. By configuring this feature and running your MongoDB workloads on Spotinst, you can utilize the “detach + re-attach EBS” feature for Stateful apps to maintain availability and data integrity for your MongoDB workloads while running them on spot instances.
Note that you should run at least 1 On-Demand Instance as the primary Instance in your MongoDB replica set while setting its priority for primary election to 1000. This ensures that the replica will always accept requests.
3. Container orchestrators (Kubernetes, Amazon ECS, Docker Swarm, and more…)
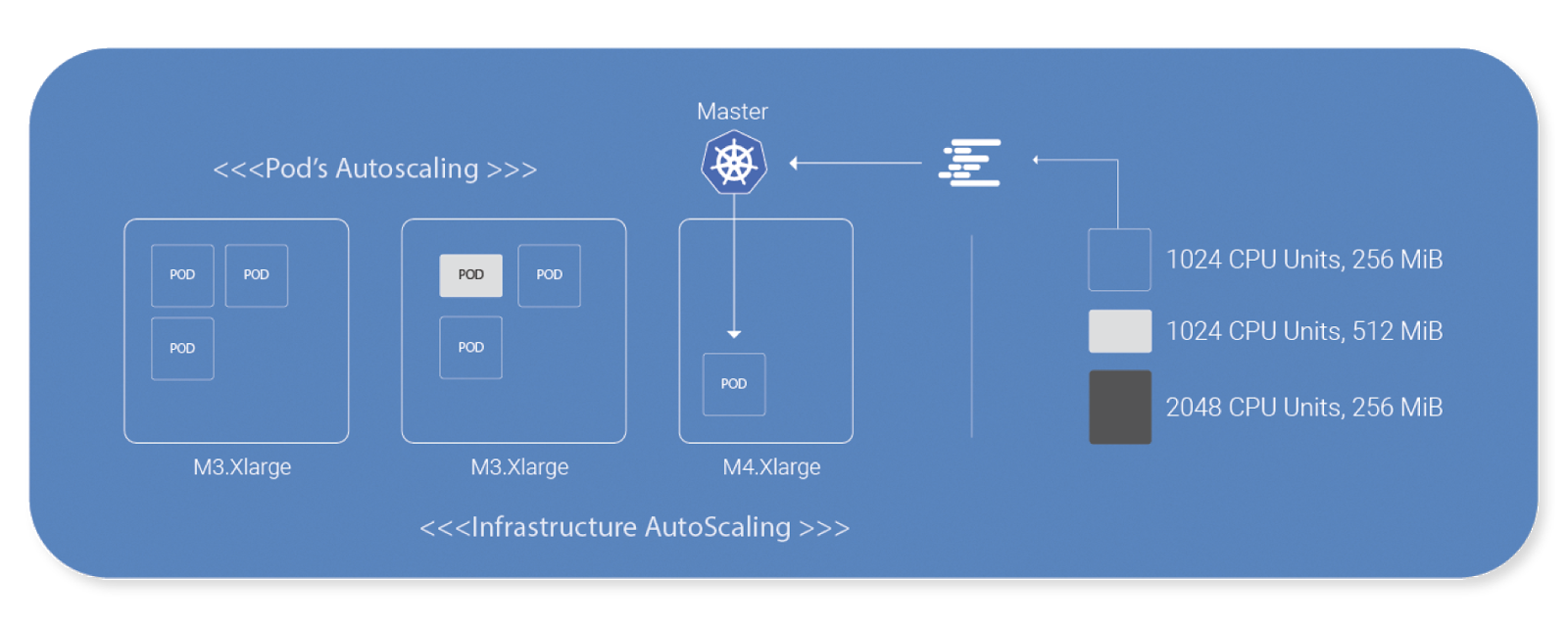
Not only does Spot enable you to run Kubernetes or other Container Orchestration platforms (Docker Swarm, ECS, Mesosphere, etc.) on spot instances, but it actually does, even more, by efficiently autoscaling your workloads on containers.
Spot is constantly calculating your costs for scaling up and down not only to spot, reserved, or on-demand instances but to differently-sized machines (2 x m3.large v. 1 x m3.xlarge, for example).
This helps ensure maximum efficiency not only by running on spot instances but by playing the Tetris game of running container workloads on different machines with optimal utilization.
4. CI/CD Workloads
Using Jenkins, Chef, or CodeDeploy to automate your CI/CD pipeline?
Sometimes, it may be a challenge to run these workloads on spot instances. Trying to manage all of your CI/CD automation while dealing with some inevitable spot instance interruptions can be highly error-prone and slow you down from getting things done. With Chef, for example, it can cause a ‘Zombie’ scenario, as Chef will be unaware of spot instance interruptions. With Jenkins or CodeDeploy, the complexity of managing updates and configurations across spot instances can be a massive headache if there is an interruption.
Spot, however, enables you to easily integrate with all three. You can pre-define parameters for scale-up and scale-down to run your CI/CD pipeline at minimal cost. This integration ensures that your configurations are set across spot instances even during terminations and replacements that are managed by Spot.