 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Running Apache Spark applications on Kubernetes has a lot of benefits, but operating and managing Kubernetes at scale has significant challenges for data teams. With the recent addition of Ocean for Apache Spark to Spot’s suite of Kubernetes solutions, data teams have the power and flexibility of Kubernetes without the complexities. A cloud-native managed service, Ocean Spark automates cloud infrastructure and application management for Spark-on-Kubernetes.
Designed to be developer-friendly, Ocean Spark comes with built-in integrations with popular data tools, including scheduling solutions like Airflow and Jupyter notebooks. There are multiple ways to run a Spark application on Ocean for Apache Spark :
- You can connect Jupyter Notebooks to work with Spark interactively
- You can submit Spark applications using schedulers like Airflow, Azure Data Factory, Kubeflow, Argo, Prefect, or just a simple CRON job.
- You can also directly call the Ocean Spark REST API to submit Spark applications from anywhere, thereby enabling custom integrations with your infrastructure, CI/CD tools, and more.
In this tutorial, we’re going to show you how to connect the orchestration service most popular among enterprise customers, Apache Airflow, and illustrate how you can schedule and monitor your workflows and pipelines on Ocean for Apache Spark.
We’re going to use the AWS service Managed Workflows for Apache Airflow (MWAA) as our main example, because it is easy to set up and handles the management of the underlying infrastructure for scalability, availability and security. But these instructions are easy to adapt to alternative ways of running Airflow.
(Optional) Set up Amazon Managed Workflows for Apache Airflow (MWAA)
An Amazon S3 bucket is used to store Apache Airflow Directed Acyclic Graphs (DAGs), custom plugins in a plugins.zip file, and Python dependencies in a requirements.txt file. Please make sure that the S3 bucket is configured to Block all public access, with Bucket Versioning enabled and located in the same AWS Region as the Amazon MWAA environment.
The following image shows how to setup the locations on S3 to store different artifacts.
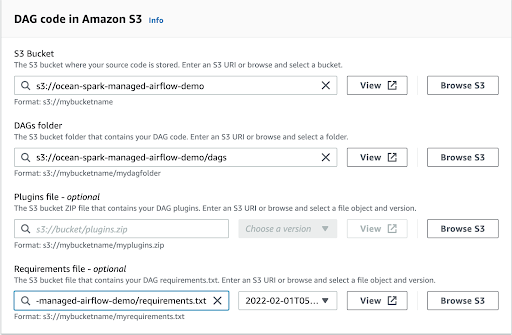
Please follow the instructions here to sync the files between your git repository and S3
Install and Configure the Ocean Spark Airflow Provider
In MWAA, you can provide a requirements.txt file listing all the python packages you want to install. You should include the ocean-spark-airflow-provider package, which is available here. On other distributions of Airflow, you can simply install this package by running pip install ocean-spark-airflow-provider.
This open-source package (see github repository) provides an OceanSparkOperator that we will show you later, and a connection to configure how to talk to Ocean Spark.
Please enter the connection details as shown below. You may access it from Admin -> Connections -> Add a new record (+ sign) and select Ocean For Apache Spark from Connection Type dropdown.
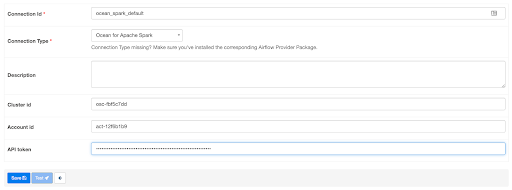
Enter the following details in the connection window, and then click Save.
- Connection Id: Use ocean_spark_default by default. You may use a different name.
- Connection Type: Select “Ocean For Apache Spark” from the dropdown
- Description: Enter any optional text to describe the connection.
- Cluster Id: The ID of your Ocean Spark cluster
- Account Id: The Spot Account ID the cluster belongs to, which corresponds to a cloud provider account.
- API token: Your Spot by NetApp API token (see How to create an API token)
Using the Ocean Spark Operator in your Airflow DAGs
In Airflow, a DAG – or a Directed Acyclic Graph – is a collection of the tasks that you want to run, organized in a way that reflects their relationships and dependencies as a graph. Airflow will only start running a task, once all its upstream tasks are finished.
When you define an Airflow task using the Ocean Spark Operator, the task consists of running a Spark application on Ocean Spark. For example, you can run multiple independent Spark pipelines in parallel, and only run a final Spark (or non-Spark) application once the parallel pipelines have completed.
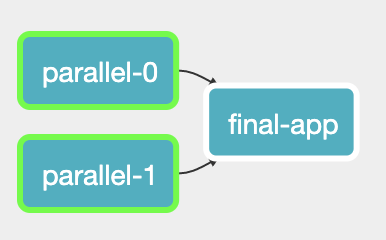
The final Spark job in this DAG will be executed once the two parallel jobs are finished.
A DAG is defined in a Python script, which represents the DAGs structure (tasks and their dependencies) as code. When using MWAA, you should upload the DAG python script into the S3 DAGs folder. Here’s an example DAG consisting of a single Spark job.

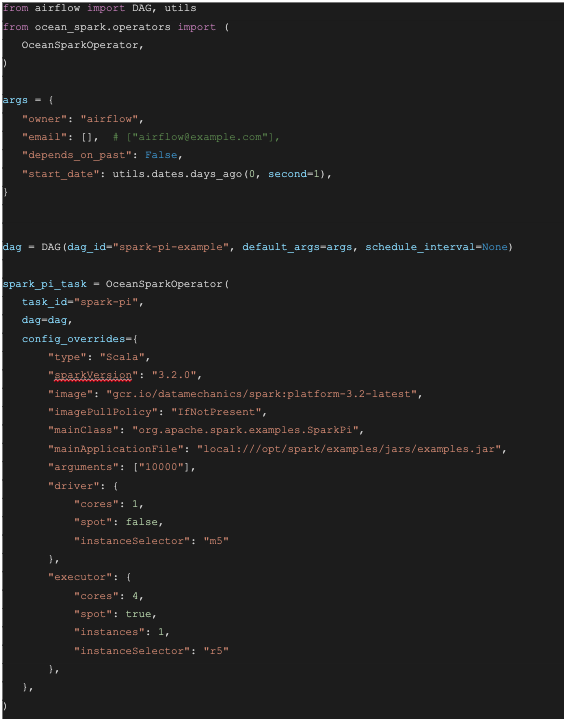
Once the file is uploaded into the S3 DAGs folder, the DAG will appear in the MWAA environment within a few minutes
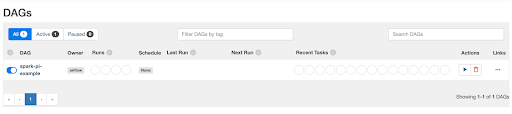
Click on Run to run the DAG. The Spark application will start running in your Spot environment in a couple of minutes (Note: you can reduce this startup time by configuring headroom).
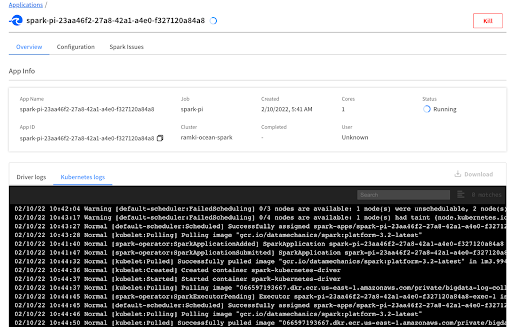
Once the application is completed, you should see the DAG completed successfully in the MWAA environment.
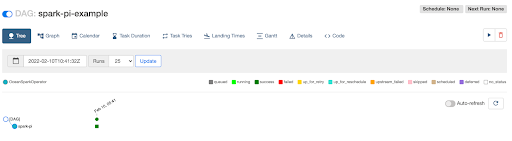
Note: If you want to give a different name to the connection other than the default name (ocean_spark_default), please use the conn_id parameter of OceanSparkOperator.

Start using Ocean for Apache Spark
Airflow is just one of several built-in integrations that Ocean for Apache Spark supports to help data teams run their Spark applications with Kubernetes. Learn how you can easily set up, configure and scale Spark applications and Kubernetes clusters with Ocean Spark. Schedule an initial meeting with our team of Apache Spark Solutions Architects, so we can discuss your use case and help you with a successful onboarding of our platform.