 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Apache Spark support for running on Kubernetes was made Generally Available and production-ready as of Spark version 3.1. Many companies have since then chosen to ditch their old Hadoop YARN clusters and standardize on Kubernetes as their infrastructure layer throughout their entire stack. Big data teams can benefit from native containerization, effective resource sharing, and a rich ecosystem of tools provided by Kubernetes. Read our article on The Pros and Cons of Running Spark on Kubernetes to learn more.
But mastering Kubernetes is an uphill climb. At Spot, we’ve seen first-hand the challenges of operating large scale Kubernetes applications. This is why we’ve built Ocean – to bring a serverless, continuously optimized infrastructure for containerized applications. And this is why we’ve built Ocean for Apache Spark, a fully-managed, continuously optimized Spark platform, deployed on a Kubernetes cluster inside your cloud account.
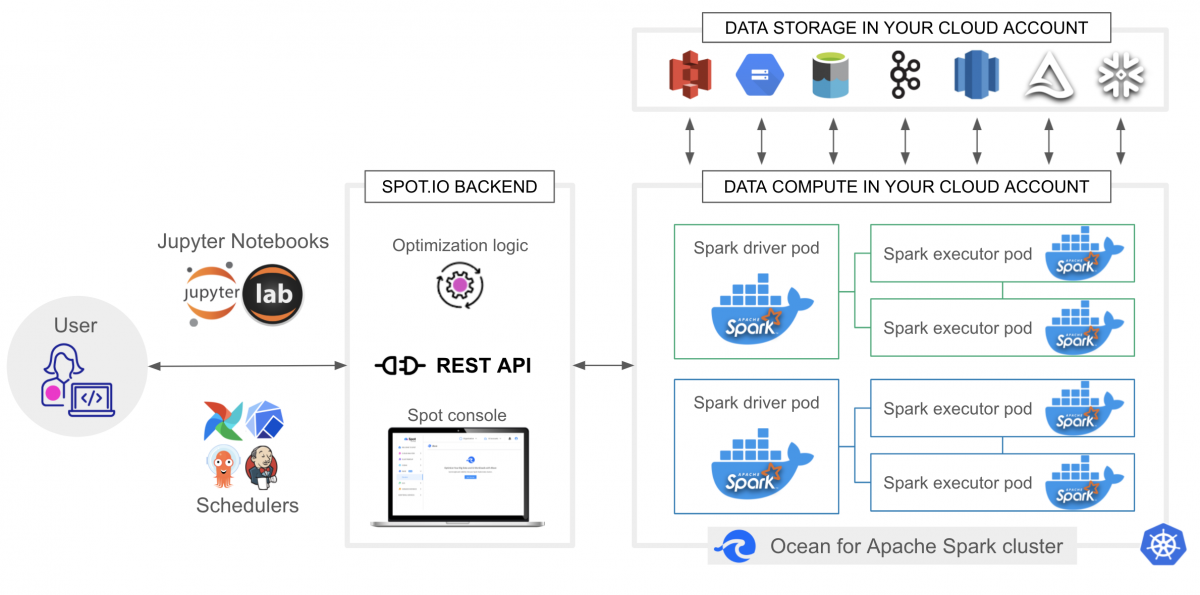
Ocean for Apache Spark was made generally available to AWS customers in March 2022, and we’re now proud to make it available to our GCP customers. Ocean for Apache Spark can now be deployed on top of a Google Kubernetes Engine cluster, in your GCP account, and in your VPC (Virtual Private Cloud).
With Ocean for Apache Spark, data teams benefit from:
An intuitive monitoring and control interface to be more successful with Apache Spark
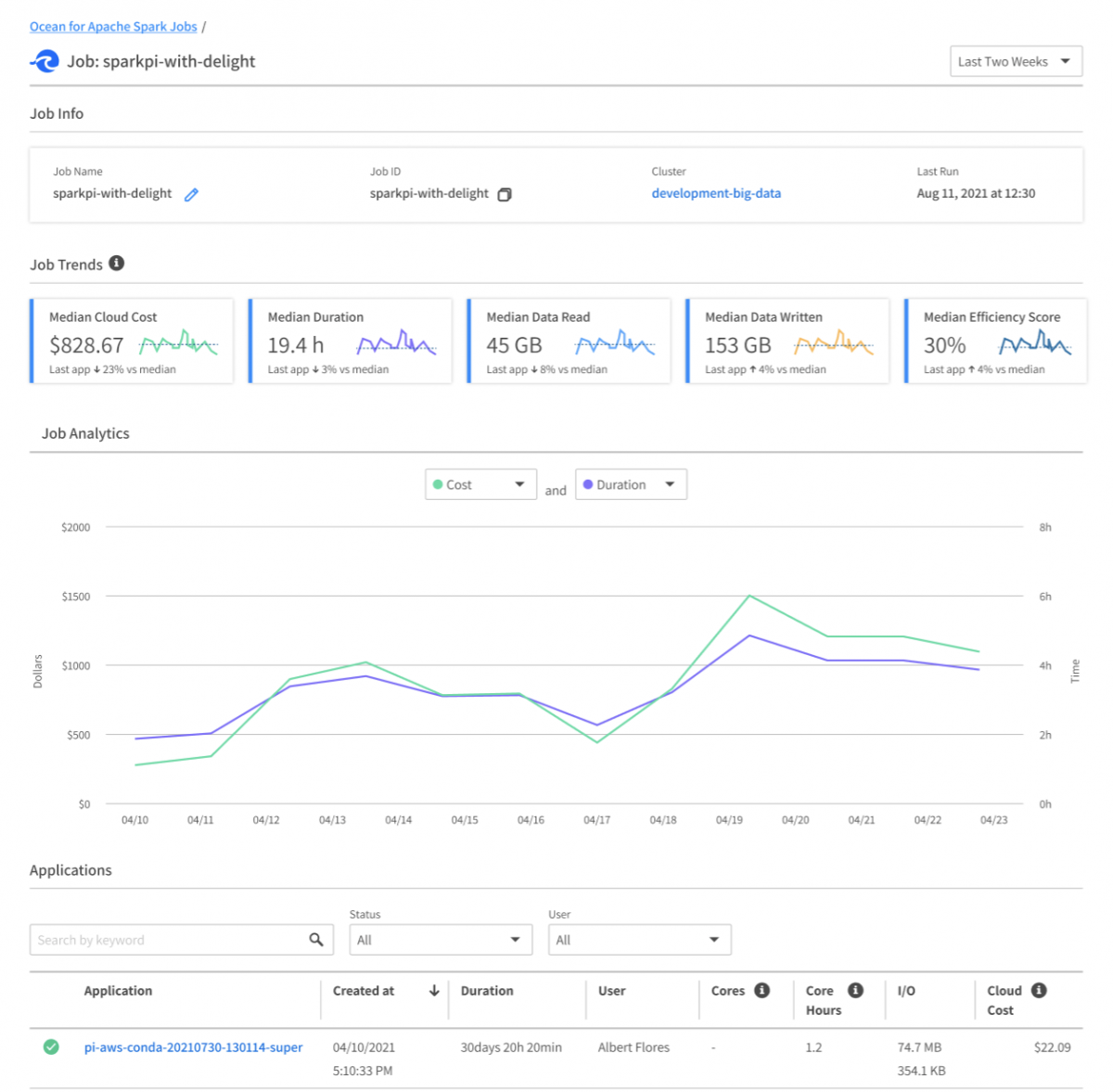
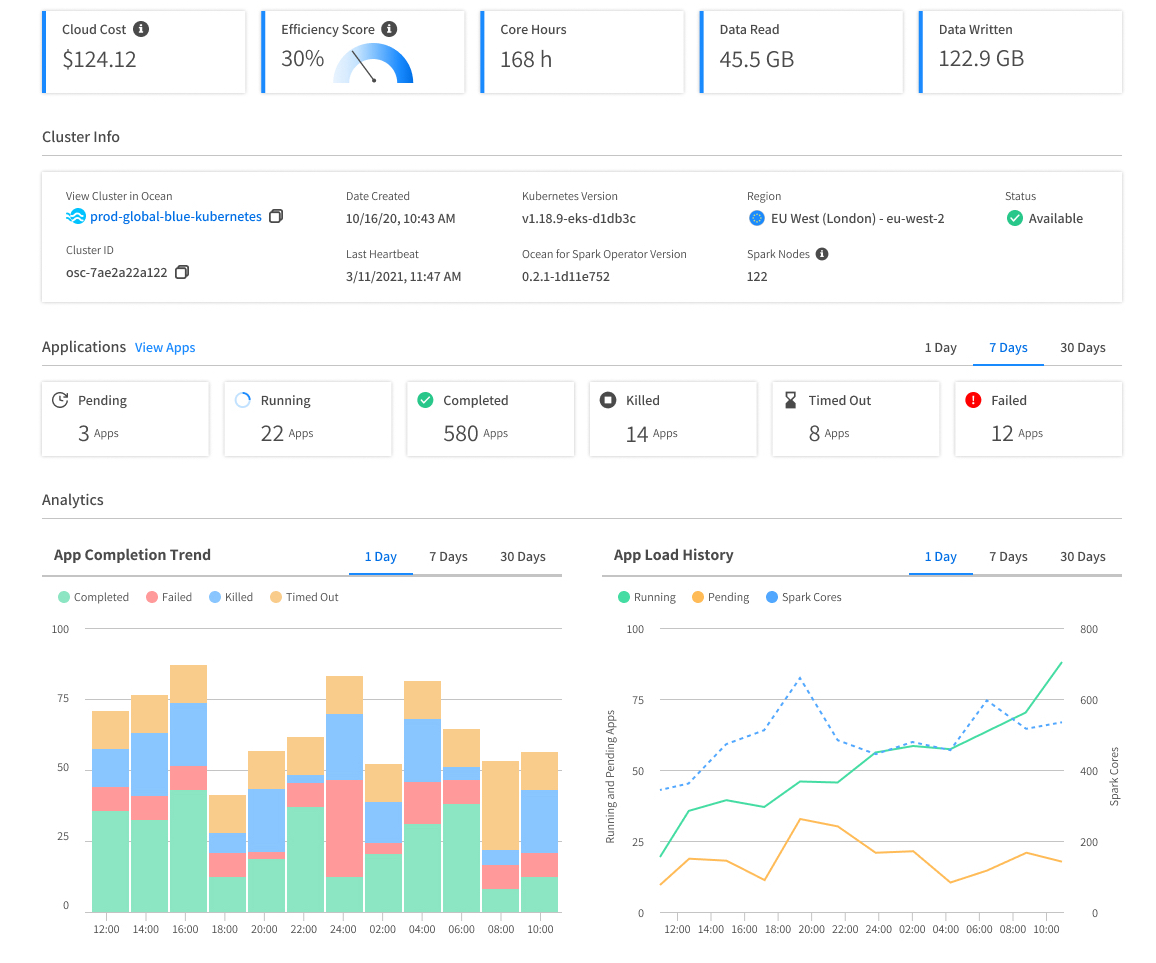
For any application that you run, you can see its logs (Spark application / container logs, Kubernetes logs), its Spark UI, and its key metrics (I/O, Memory, CPU, Shuffle, Efficiency Score) on an intuitive dashboard designed to help you understand and improve the performance bottleneck of your pipelines. Cloud provider costs (like GCP costs) are also visible in real-time at the most granular level of each application, or can be aggregated and broken down by cluster, user, and job.
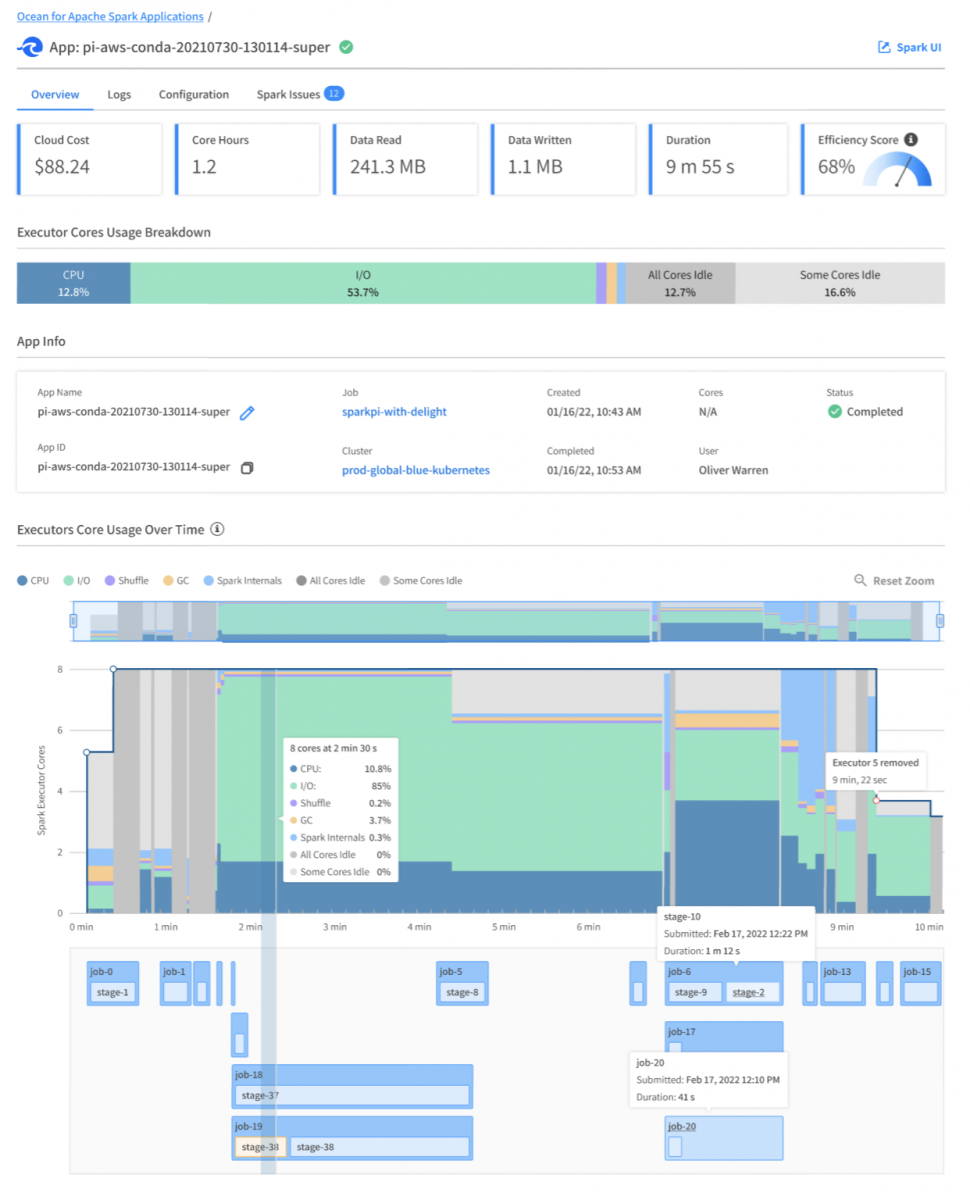
You can then modify your application configurations – such as the Spark version and Docker image to use, the Spark configurations, the amount of memory and CPU resources to allocate to your applications, and more – directly in the UI by using our Configuration Templates, or in your API calls.
Continuous scaling and optimizations at the Kubernetes layer and the Spark layer
Google Cloud Platform recently announced a partnership with Spot to help their users make the most of their Spot instances – the evolution of preemptible instances which are now in public preview. Ocean for Apache Spark transparently leverages the optimizations of Spot to continuously scale the GKE cluster to run your Apache Spark workloads on the lowest-cost, most-reliable VMs. The Spark driver pods will go to on-demand VMs by default, while the Spark executor pods will go to Spot instances to deliver up to 90% savings.
Apache Spark can now leverage the termination notice given by the cloud provider to preventively save shuffle and cache data before the Spot node goes down. This feature works out of the box on Ocean for Apache Spark, and will be explained in more detail by our Spark experts at the upcoming Data + AI Summit (session: How To Make Apache Spark on Kubernetes Run Reliably on Spot Instances).
Ocean for Apache Spark provides additional automated, history-based optimizations at the Spark layer such as automatically sizing your Spark pods to bin-pack them efficiently on virtual machines, automatically deciding of the optimal number of Spark executors to use to run your pipelines within a target duration while minimizing your costs, optimizing the performance of shuffle-heavy workloads and tuning the number of Spark partitions to use.
A flexible, open, and forward-looking data architecture
The automations and optimizations of Ocean for Apache Spark are designed to give you the benefits of Spark-on-Kubernetes, without its complexities. But it builds on top of flexible, open-source technology, which is easy to customize to your needs.
It is deployed on a Kubernetes cluster, in your cloud account and in your VPC, that you control directly and can deploy with Infrastructure as Code tools like Terraform. The full ecosystem of cloud-native tools is available to you, making it easy to build your custom CI/CD workflows, plug-in external monitoring, networking or security tools, and manage data access control at a fine granularity. You can now use Kubernetes as a standard, cloud-agnostic infrastructure layer, throughout your entire stack.
Ocean for Apache Spark also provides ready-to-use integrations with the popular data tools like Jupyter Notebooks (including JupyterHub), and schedulers like Airflow. All popular data storage options are supported, including manifest table format like Delta Lake or Apache Iceberg. All Spark versions posterior to Spark 2.4 are supported, and thanks to containerization you can now run Spark applications using different Spark versions concurrently on the same cluster, thereby significantly reducing costs compared to the “Transient Cluster” architecture.
50 to 80% reduction on your Total Costs of Ownership
Customers migrating to Ocean for Apache Spark reduce their total costs (compute costs + managed service provider fee) by 50 to 80%. These savings come from:
- The Kubernetes architecture enabling high resource utilization
- Continuous scaling of the cluster
- Using spot VMs and making them reliable thanks to Spot predictive technology
- The automated tuning of Spark configurations and other Spark optimization
- Our fair and transparent pricing, which is lower than alternatives
Join customers like the United Nations or Lingk.io who have migrated to our serverless Spark-on-Kubernetes offering to benefit from a more developer-friendly way to run Apache Spark, and reduce their costs significantly at the same time. To get started, schedule a time to get a live demo from our team of Spark experts and discuss your use case and needs.