 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

When Apache Spark introduced native support for Kubernetes it was a game changer for big data. Speed, scale and flexibility are now at the fingertips of data teams—-if they can master Kubernetes. It’s an uphill climb for even experienced DevOps teams.
At Spot, we’ve seen first-hand the challenges that companies are facing as they navigate the complexities of operating large-scale Kubernetes applications. Spot Ocean, the first solution of our Kubernetes suite, brought serverless, optimized infrastructure to containerized workloads. Now, the Ocean suite has expanded to address the specific needs of big data applications with Ocean for Apache Spark.
After announcing its private preview at AWS re:Invent 2021, Ocean Spark is now officially generally available for AWS customers. Ocean Spark is a serverless solution that eliminates the complexities of Spark-on-Kubernetes, and enables data teams to leverage the container orchestrator for all its benefits without the headache. With Ocean for Apache Spark enables data engineering teams to:
Run applications on the lowest costs, highest performing infrastructure possible
Sitting on top of the Ocean serverless engine, applications automatically run on the most optimized mix of spot, on-demand and reserved instances. With an enterprise-level SLA, workloads run reliably on spot instances for up to 90% savings.
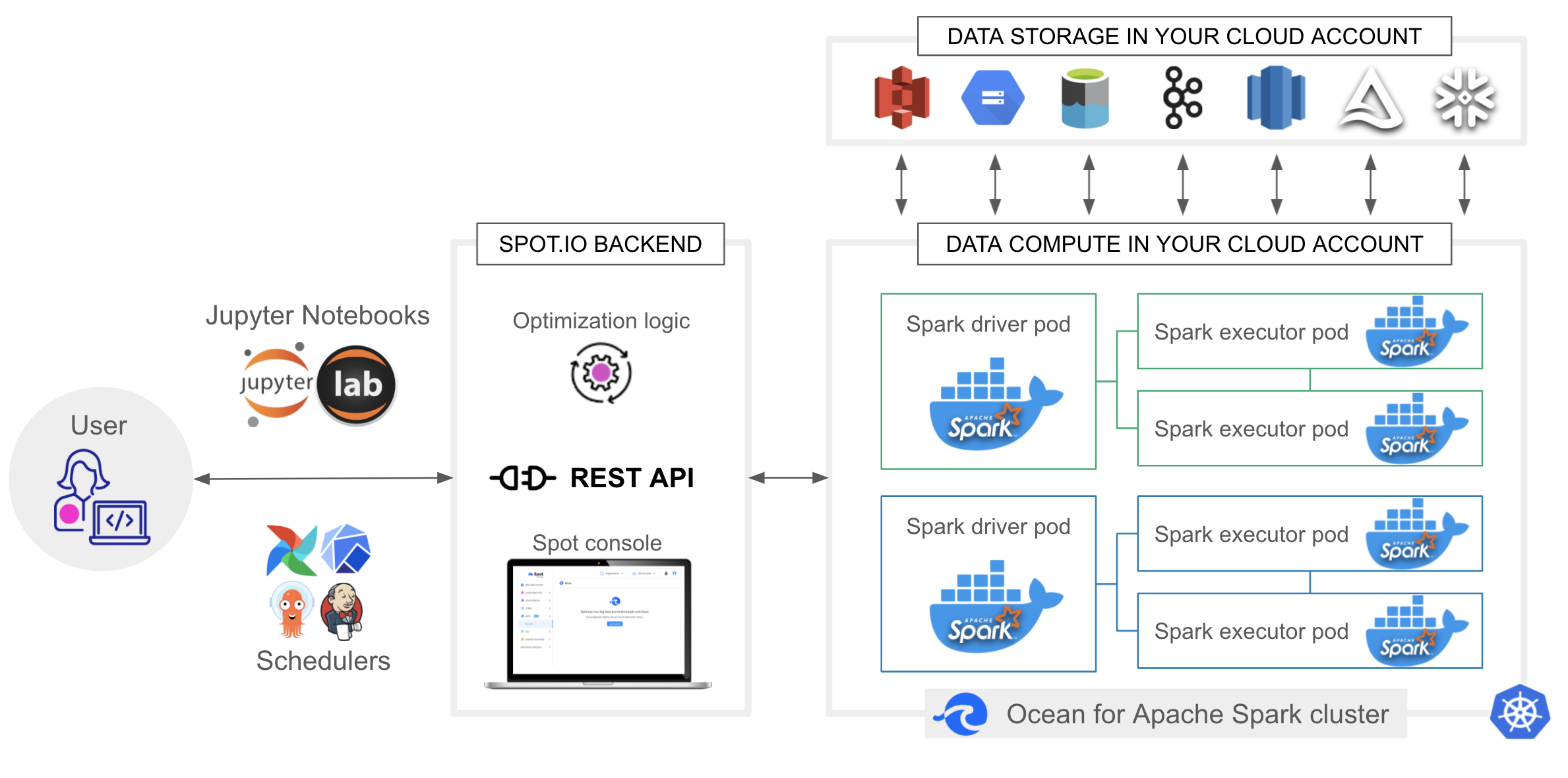
Focus on applications, not on cloud infrastructure
Ocean Spark automatically tunes Spark configurations, and with automated infrastructure management and optimization, data engineers don’t have to worry about scaling infrastructure. Ocean Spark monitors events at the container-level and automatically scales infrastructure according to a Spark job’s specific requirements.
Develop new Spark-on-Kubernetes in a simple way
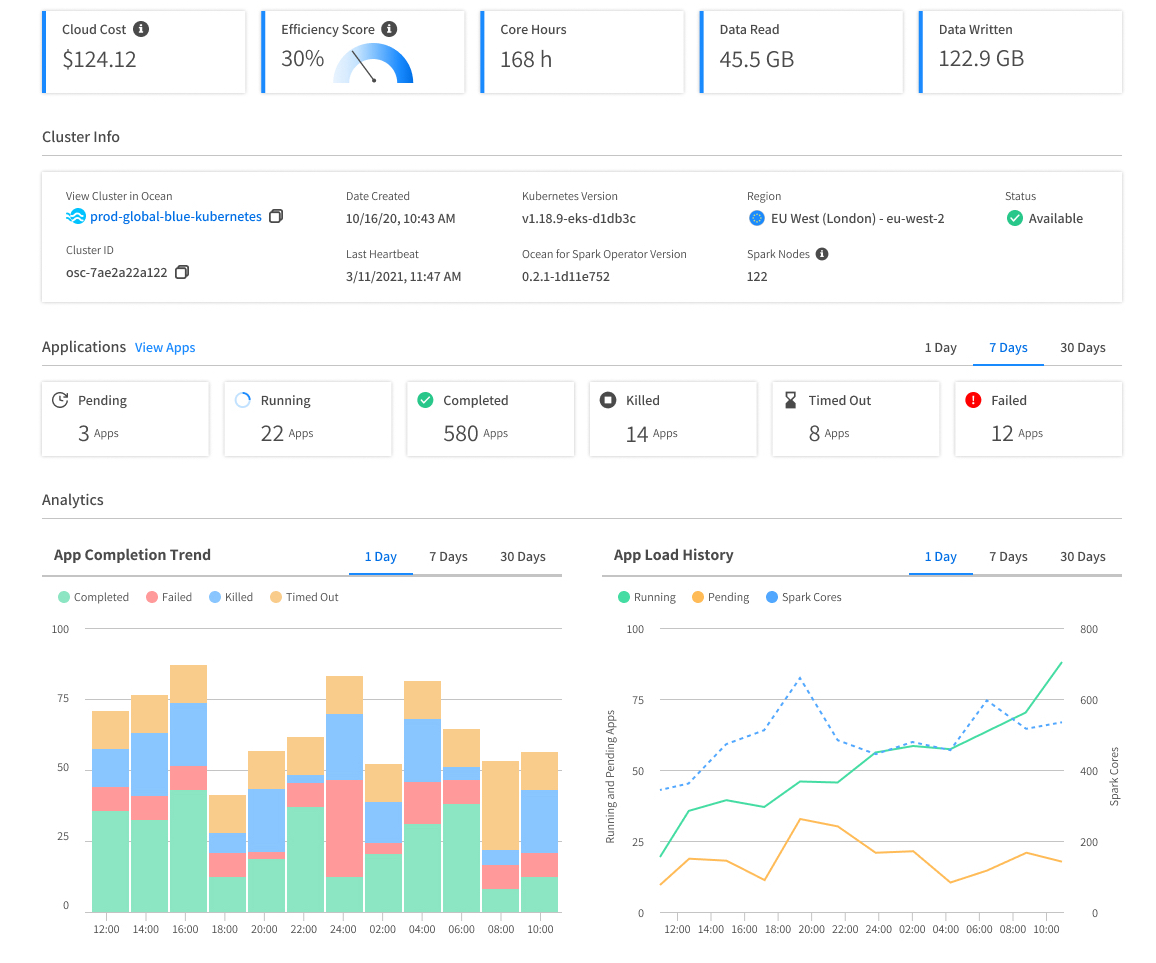
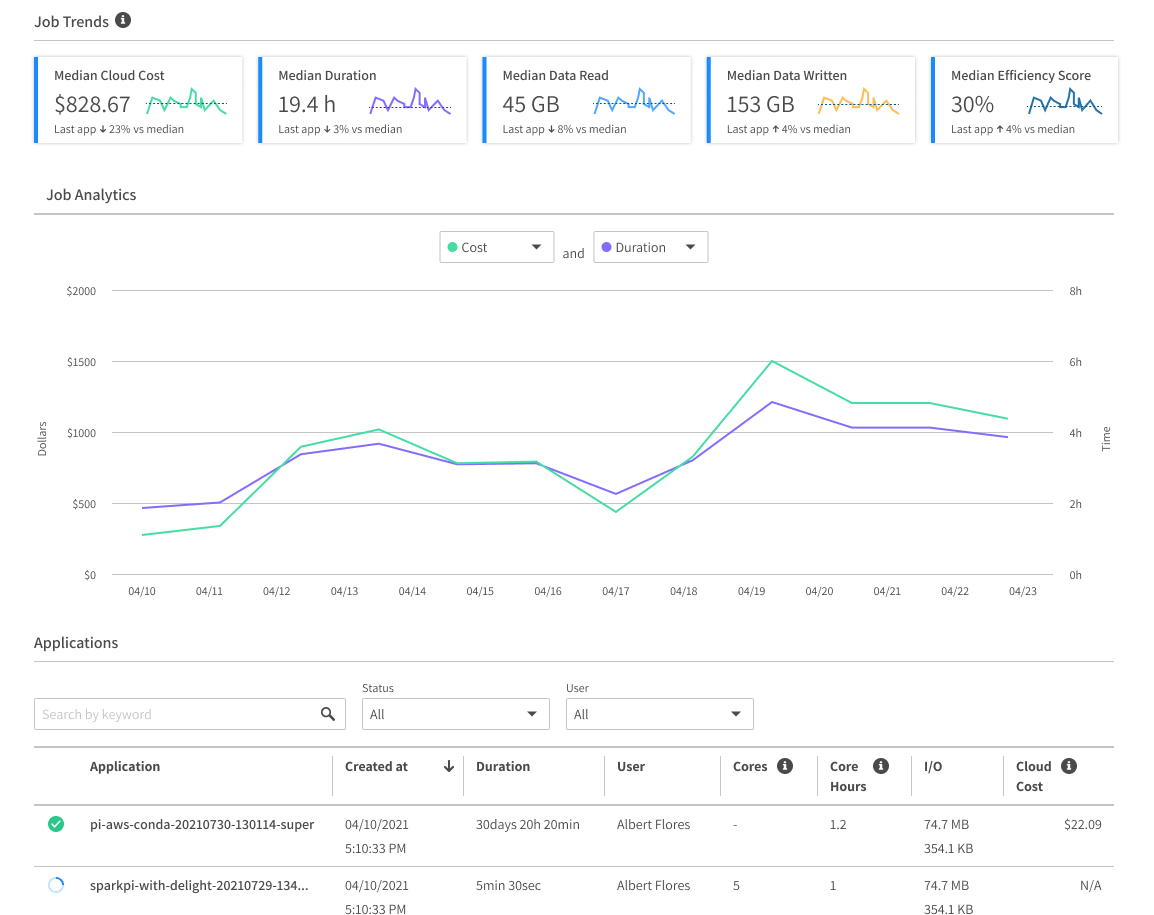
We provide Spark developers with a Spark-centric observability layer showing Spark applications logs, Spark UI, key metrics (I/O, CPU Usage, Memory usage), both in real-time and for historical analysis. Powerful automations and optimizations such as pod sizing, Spark and cluster-level scaling, AZ selection, volume mounting, improve the stability and performance of Spark pipelines, and reduce the maintenance and operations work on data teams.
Integrate your existing data tools
Ocean for Apache Spark features ready-to-use integrations with Jupyter notebooks (including JupyterHub and JupyterLab), and orchestrators like Airflow, AWS StepFunction, and Azure Data Factory, the Hive Metastore, . A REST API makes it possible to submit Spark applications from anywhere and build custom integrations and CI/CD workflows. By building on top of open-source, cloud-native technology, Ocean for Apache Spark also natively interfaces with the popular tools from the Kubernetes ecosystem – monitoring, networking, security, cluster-management, and more.
Many customers have already chosen to benefit from the serverless experience of Ocean for Apache Spark, giving them an optimal mix between ease-of-use, flexibility, and low cloud costs. See for example how statisticians around the world from the United Nations Global Big Data Platform leverage Ocean for Apache Spark to simplify their work and reduce their costs, or how the data integration product Lingk.io migrated from EMR to Ocean for Apache Spark and achieved high savings while improving their end-users experience. Schedule a time with our team of Apache Spark and experts to discuss your use case and get started with Ocean for Apache Spark.