 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

The dynamic nature of cloud native applications is both a blessing and a curse. The ability to use compute, storage, and network resources without managing physical hardware is a real blessing. Your applications can take advantage of the seemingly limitless resources available in the public cloud. Unfortunately, the curse becomes clear when the bill arrives! It is a significant CloudOps challenge to find the balance between providing optimal application performance and minimizing cost.
Kubernetes services can scale up and down according to the current demands of the applications. Successful scaling requires the underlying infrastructure is ready to accept the increased workload. If sufficient resources are not available, a new node will need to be provisioned. The delay associated with adding a new node to the cluster degrades application performance and adversely impacts user experience. How can you avoid this situation? Overprovision resources in your cluster.
Having extra resources available enables rapid scheduling of new pods. Overprovisioned cluster resources are referred to by Ocean as Headroom. When using spot instances for headroom you can improve user experience without dramatically increasing costs. You can save even more by moving primary workloads to spot instances. In addition, maintaining headroom in your cluster allows for faster rescheduling of any pods that are evicted due to a spot instance termination.
Let’s look at the details involved in adding headroom to a cluster.
The DIY Approach
Kubernetes provides a built-in priority system. Each pod can have a priority level set which indicates its relative importance. The scheduler will evict lower priority pods to free up resources needed to schedule higher priority pods.
You can define a new priority class and run low priority deployments that will be evicted once higher priority pods are deployed. These low priority deployments reserve the headroom, and absorb the delay related to provisioning new cluster nodes.
A recommended way to implement this is using the cluster-overprovisioner. It leverages the priority concept and works with the cluster-autoscaler to overprovision resources.
A potential downside of this setup is that it is static. What if your cluster’s resource usage grows or shrinks significantly over time? You could end up with an inappropriately large or small amount of headroom available.
In addition, users:
- Need to learn, understand, deploy, manage, upgrade, and downgrade cluster-overprovisioner.
- Own the burden to determine which pods have the most scaling activity and constantly align appropriate units of low priority pause pods to each cluster based on usage patterns during day/night, week/month.
- Get no SLA.
- If there are issues, you are on your own.
Introducing Ocean Headroom
Spot by NetApp’s Ocean provides two easy ways to manage headroom. Headroom can be configured manually with specific values or automatically as a percentage of the cluster’s resource usage. It is even possible to combine manual and automatic headroom settings to best meet the workload requirements.
Automatic Headroom
Automatic headroom is configured as a percentage of the cluster’s resource usage. The Ocean Autoscaler continually works to maintain the specified headroom percentage. Therefore, automatic headroom is a dynamic solution. It makes headroom responsive to changes in cluster resource usage over time.
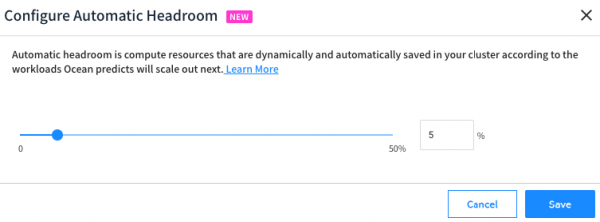
How is it calculated?
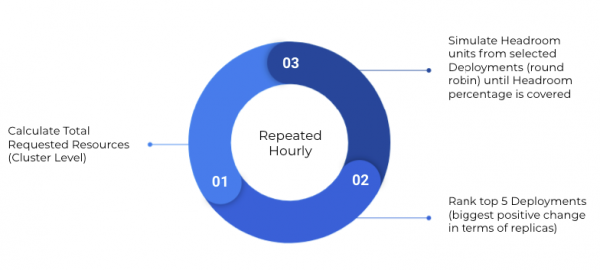
Every hour Ocean will examine the total resources (CPU, Memory, and GPU) requested in the cluster. Let’s look at an example when the automatic headroom percentage is configured as 5%. For a cluster with 100 vCPUs and 200GB of memory requested, the overall headroom amount will be calculated as 5 vCPUs and 10GB of memory.
Then Ocean will rank the top five deployments based on their positive change replica-wise. For example, a deployment that went from 2 to 10 replicas (+8) will be ranked higher than a deployment that went from 9 to 10 replicas (+1).
Next Ocean will verify the availability of headroom units for the identified deployments in a round-robin manner. Ocean will then scale up new nodes until the calculated headroom level is reached.
What drives Ocean to consider replica changes for headroom computation?
Headroom allows for fast scheduling when scaling out an application. By identifying the most dynamic applications (aka the ones with the most frequent replica count changes), headroom is reserved in blocks that match the most likely future requests. In working with 100s of Ocean customers, we have determined that the top 5 dynamic applications (in that computation hour) are the best predictor of future needs (within that hour).
Manual Headroom
Configured in headroom units, each unit consists of values for vCPU, memory, and GPU resources. These can be defined at the Ocean Cluster and/or Virtual Node Group (VNG) levels.
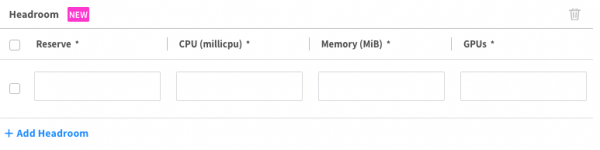
Ocean makes it easy to configure via GUI or API and does not require setting up any additional tools in the cluster. This option allows for granular resource control and allows the user extra flexibility (when needed).
Manual headroom can be useful in the following situations:
- The user is fully familiar with the applications trends.
- There is a big application that requires the infrastructure to wait for it and it does not fall under the automatic headroom calculations.
Please note – We’ve recently added the ability to specify scheduled manual headroom at the VNG level. This allows you to set various headroom specifications that will be relevant in specific timeframes using cron expressions.
Tip – Ocean now supports having both automatic and manual headroom working concurrently in the same cluster. You can find more details in this blog post (one on top of the other).
Summary
Overprovisioning resources in your cluster is an important key to providing the best application performance and user experience without runaway costs. Spot by NetApp’s Ocean provides dynamic headroom and simplifies management of overprovisioned resources.
Learn more about Ocean Headroom.