 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Most Apache Spark users overlook the choice of an S3 committer (a protocol used by Spark when writing output results to S3), because it is quite complex and documentation about it is scarce. This choice has a major impact on performance whenever you write data to S3. On average, a large portion of Spark jobs are spent writing to S3, so choosing the right S3 committer is important for AWS Spark users.
With the Apache Spark 3.2 release in October 2021, a special type of S3 committer called the magic committer has been significantly improved, making it more performant, more stable, and easier to use.
At Spot by NetApp, we tested the S3 committer with real-world customer’s pipelines and it sped up Spark jobs by up to 65% for customers like Weather20/20. We now recommend the use of this committer to all AWS Spark users.
Here’s what we’ll cover in this blog post:
- What is an S3 Committer? Why should I use the magic committer?
- Which performance benefits can it enable?
- How can I turn on the magic committer?
- What happened in Spark 3.2? What to expect of future Spark releases?
What is an S3 Committer? Why should I use the magic committer?
Apache Spark, like Hadoop MapReduce before it, writes the output of its work in a filesystem. More precisely, many Spark tasks run in parallel, and each Spark task writes its output as a file. The system must produce a consistent output even if:
- Some tasks can be interrupted while they’re in progress (e.g. spot kill, executor out of memory error) and retried on another executor
- Multiple copies of a the same task can be executed in parallel on different executors (a mechanism called speculation, which helps with performance)
To solve this problem, Hadoop MapReduce uses a technique called the commit protocol, which lists intermediate output directories, and renames files to their final location. This worked well on the Hadoop Distributed File System (HDFS) because listing a directory produced consistent results, and renaming a file was a fast “O(1)” operation.
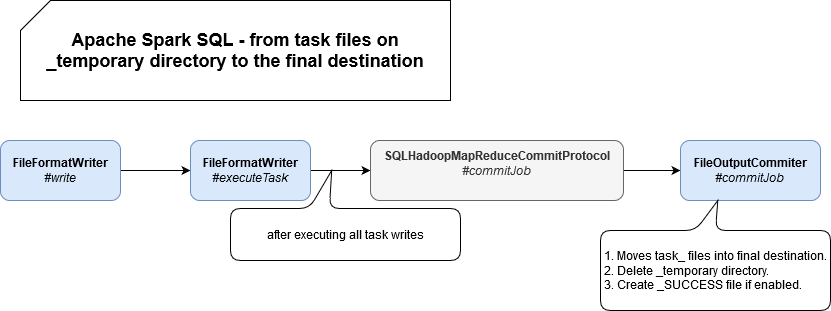
While this is true for HDFS, this is not the case for S3. Renaming a file on S3 is *not* an atomic operation, it’s implemented as a COPY and a DELETE operation, which takes about 6MB/second to run.
The default job committer for Spark (called FileOutputCommmitter) therefore is not safe to use with S3. For example, if a failure occurs while the renaming operation is in progress, the data output can be corrupted. In addition to being unsafe, it can also be very slow.
To fix this problem, the community has developed special committers for S3 called the S3A Committers:
- The staging committer, developed by Netflix. It works well but it requires having a cluster-level shared storage like HDFS or NFS to store intermediate output files, which isn’t very convenient to set up, particularly for Spark-on-Kubernetes users.
- The magic committer, which is community-led and the new Hadoop default.
Initially, the magic committer had a big drawback: it required installing a Dynamodb database to enable an S3 client mechanism called S3Guard (“guarding” you against inconsistent results).
Since December 2020, S3 delivers strong read-after-write consistency globally, meaning that you are guaranteed to see a file when you list a directory after having written the file (as you would on your laptop’s hard disk). It is therefore not necessary to install S3Guard anymore, making the magic committer much more easy to use.
To go deeper on this topic, see the official Hadoop documentation and this research paper on “zero-rename committers” by Steve Loughran and other Apache contributors.
Note: If you are using a pure-manifest table format like Delta.io, Apache Iceberg, or Apache Hudi, the S3 committers are not relevant to you as these table formats handle the commit process differently.
Which performance benefits can the S3 committer enable?
The exact performance benefits depend on the workload, but as a rule of thumb, the gains will be significant if a large portion of your Spark job is spent writing data to S3 (which is a very common situation). In addition to performance benefits, using the magic committer instead of the default FileOutputCommitter will also protect you from nasty data corruption bugs in edge-case situations (executor loss, speculation, etc).
Let’s evaluate the performance benefits on a real-world Spark pipeline by one of our customers Weather20/20, a weather analytics platform. Before using the magic committer, their pipeline would run many Spark jobs and tasks for an hour, then take a “break” for almost an hour, during which it appears that Spark is idle as no task is executed, and then finally exiting.
This problem was very obvious by looking at Delight, our free Spark monitoring tool:
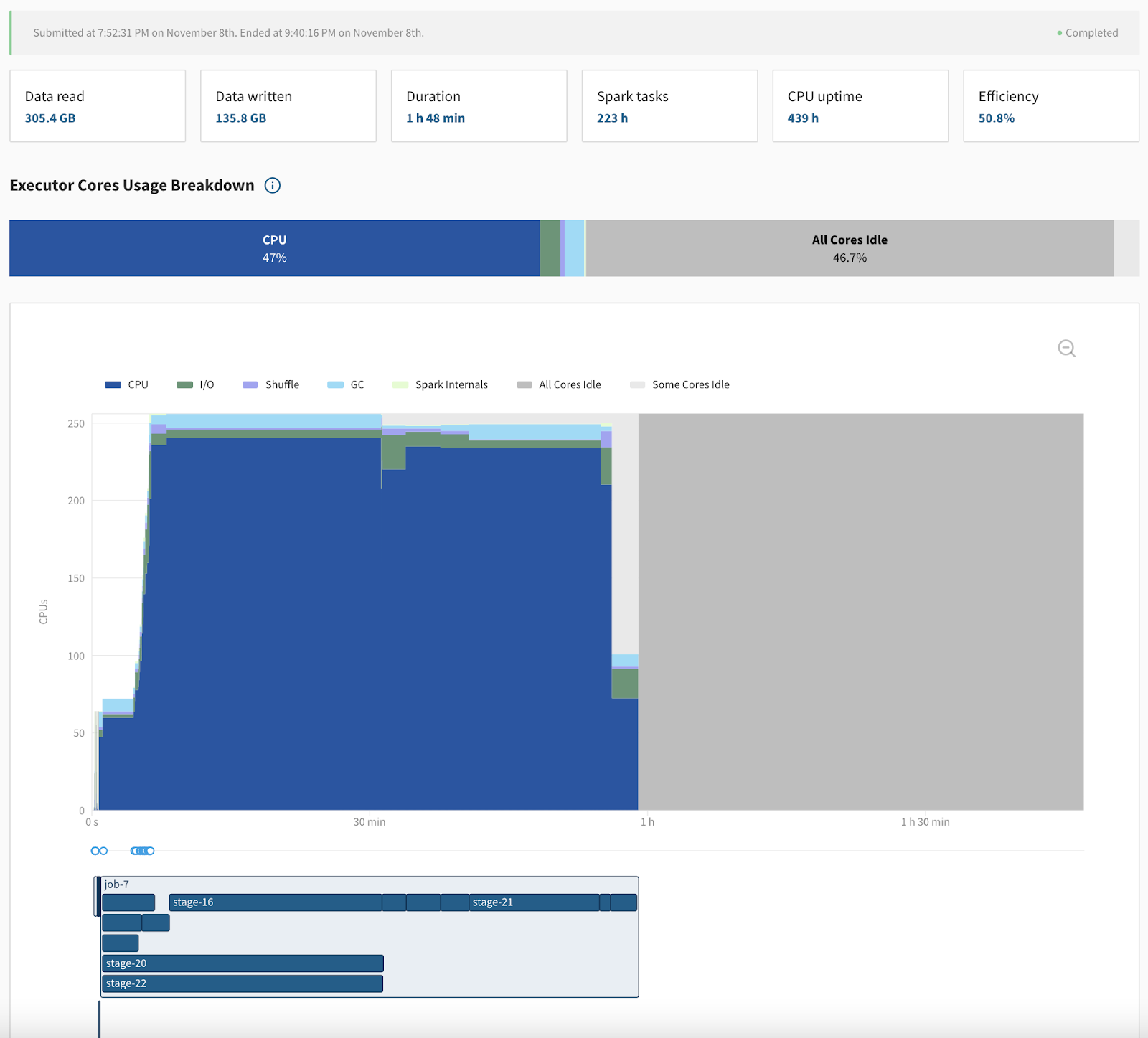
The 48-min break at the end of the Spark application is also clearly visible in the Spark driver logs:
21/11/08 20:52:11 INFO DAGScheduler: Job 7 finished: insertInto at NativeMethodAccessorImpl.java:0, took 3495.605049 s
21/11/08 21:40:13 INFO FileFormatWriter: Write Job 13ca8cb6-5fc0-4fe9-9fd0-bba5cf9e2f7f committed.
The last line gives a hint that between 20:52 and 21:40, Spark was running the job commit step of the FileOutputCommitter protocol. As explained earlier, the S3 rename operation is very slow (for large datasets). In addition to slow S3 calls, the committer is making hundreds of thousands of S3 calls, which in some cases can be throttled by S3 (you can confirm this by enabling S3 logs and looking for 503 API responses).
By switching to the magic committer, here’s what the application Delight graph looked like.

This pipeline now runs in 40 minutes, versus 1 hour and 48 minutes previously. This is a 63% improvement! This pipeline may be a particularly extreme example of an improvement, but we regularly see improvements in the 15-50% range for pipelines writing a lot of data to S3. You should try this for yourself.
How can I turn on the magic committer?
You can turn it on by inserting a single configuration flag in your sparkConf: “spark.hadoop.fs.s3a.bucket.all.committer.magic.enabled”: “true”
Note: It was previously necessary to provide the bucket name in your spark configuration key spark.hadoop.fs.s3a.bucket.<bucket>.committer.magic.enabled. This is because originally you had to install S3Guard on a per-bucket basis. Now that S3 is strongly consistent, this isn’t necessary anymore. If you pass the flag spark.hadoop.fs.s3a.bucket.all.committer.magic.enabled, the magic committer will be used on all buckets.
You also need to include the spark-hadoop-cloud library in your docker image or as a dependency, since it provides classes used by the S3A committers. If you’re missing this dependency, you will get an error like: java.lang.ClassNotFoundException: org.apache.spark.internal.io.cloud.PathOutputCommitProtocol
To verify whether the magic committer is used, the simplest way is to look for the word “committer” in the Spark Driver logs.
If you see logs like this:
21/11/08 19:53:54 INFO ParquetFileFormat: Using user defined output committer for Parquet: org.apache.spark.internal.io.cloud.BindingParquetOutputCommitter
21/11/08 19:53:54 WARN AbstractS3ACommitterFactory: Using standard FileOutputCommitter to commit work. This is slow and potentially unsafe.
21/11/08 19:53:54 INFO FileOutputCommitter: File Output Committer Algorithm version is 1
Then there is an issue – the standard FileOutputCommitter is being used. And as the warning says, it is slow and potentially unsafe.
If you see the log below however, then you know the magic committer is correctly being used:
21/11/14 00:05:11 INFO AbstractS3ACommitterFactory: Using committer magic to output data to s3a://…
What happened in Spark 3.2? What to expect of future Spark releases?
Spark 3.2 makes the magic committer more easy to use (SPARK-35383), as you can turn it on by inserting a single configuration flag (previously you had to pass 4 distinct flags). Spark 3.2 also builds on top of Hadoop 3.3.1, which included bug fixes and performance improvements for the magic committer. Read our article on Spark 3.2 to learn more about the main features and improvements of this release.
Note: Another unrelated Hadoop 3.3 improvement. If you pass the configuration flag “spark.hadoop.fs.s3a.directory.marker.retention”: “keep”, Hadoop will stop needlessly deleting directory markers. You need to opt-in for this behavior (you need to pass the flag) because it’s not backwards compatible. You should only pass this flag if all your Spark applications use Hadoop 3.3+.
There is ongoing work by Steve Loughran (an Apache Software Foundation Member since 2000) to build similar task-manifest commit algorithms for the object stores of Azure and GCP (MAPREDUCE-7341), and to improve the performance of the magic committer (HADOOP-17833). This is a huge amount of work (thank you Steve!) which will first need to be contributed to Hadoop, and then picked up by a new Spark release.
Conclusion
Starting with Spark 3.2, we highly recommend the magic committer for AWS Spark users who write data to S3 in their pipelines (unless they’re already using a table format like Delta, Hudi, or Iceberg). By switching a single configuration flag, you may achieve up to 60% performance improvement on your pipelines, as well as avoid nasty data corruption bugs caused by the default FileOutputCommitter.