 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

When running AKS clusters, ideally you want the compute infrastructure to adapt to your Kubernetes workload and not the other way around. VMs should automatically match your application requirements all the time without labor-intensive, hands-on management, and of course, your Azure bill should be as low-cost as possible. However, in trying to achieve this ideal, AKS and Kubernetes users in general, still face significant operational challenges.
Solving these challenges (more on that soon) is the raison d’etre of Spot Ocean, Spot’s serverless container solution.
With Ocean AKS Limited GA [1st May 2023], we are pleased to announce that Spot Ocean now automates and optimizes AKS clusters. For details on architecture and a deep dive on features, see Ocean AKS – Serverless Kubernetes for Azure.
Additionally, Spot and Pulumi are collaborating to deliver a first-class integration for infrastructure-as-code primitives. The Spot provider for Pulumi enables our users to provision, manage and upgrade their Ocean AKS cluster using Pulumi’s SDK while allowing full flexibility to develop in the language of their choice.
In this post we’ll discuss four cloud infrastructure challenges and how Spot Ocean addresses them:
- Mismatching between pod requirements and nodes
- Leveraging Spot VMs for production environments
- Over-provisioning for priority workloads
- Managing workloads with different resource requirements
Let’s take a look at the common operational and financial challenges that Spot Ocean addresses for AKS users.
#1 – Mismatching between pod requirements and nodes
As a Pod can only run on a single node, even if there are sufficient resources overall within a cluster, if there is no single node that has the full resources to match the Pod, the pod will end up in a pending state for longer than necessary (as shown in below animation). Without careful configuration, this kind of mismatch is not uncommon and can create delays and service interruptions.
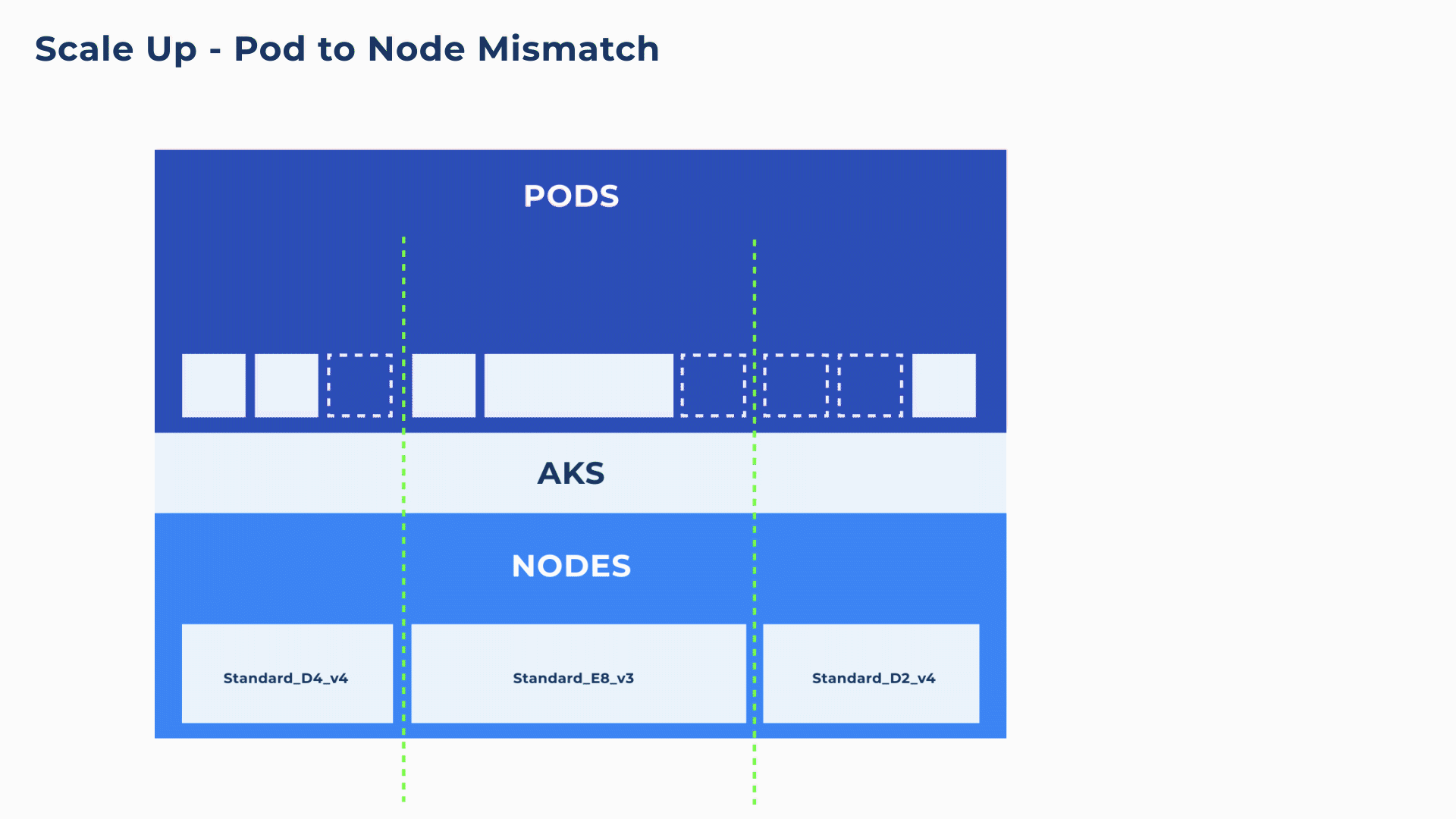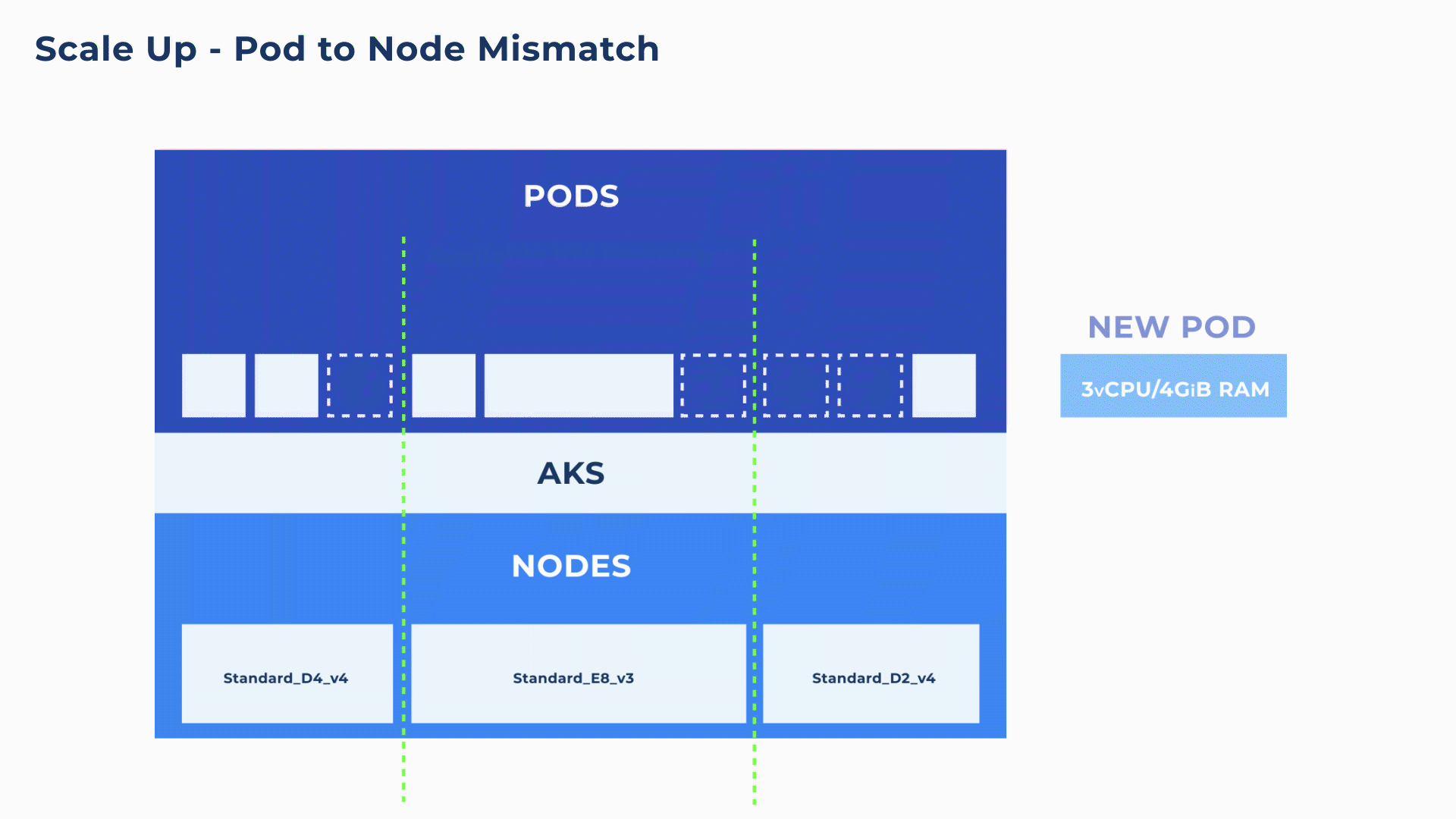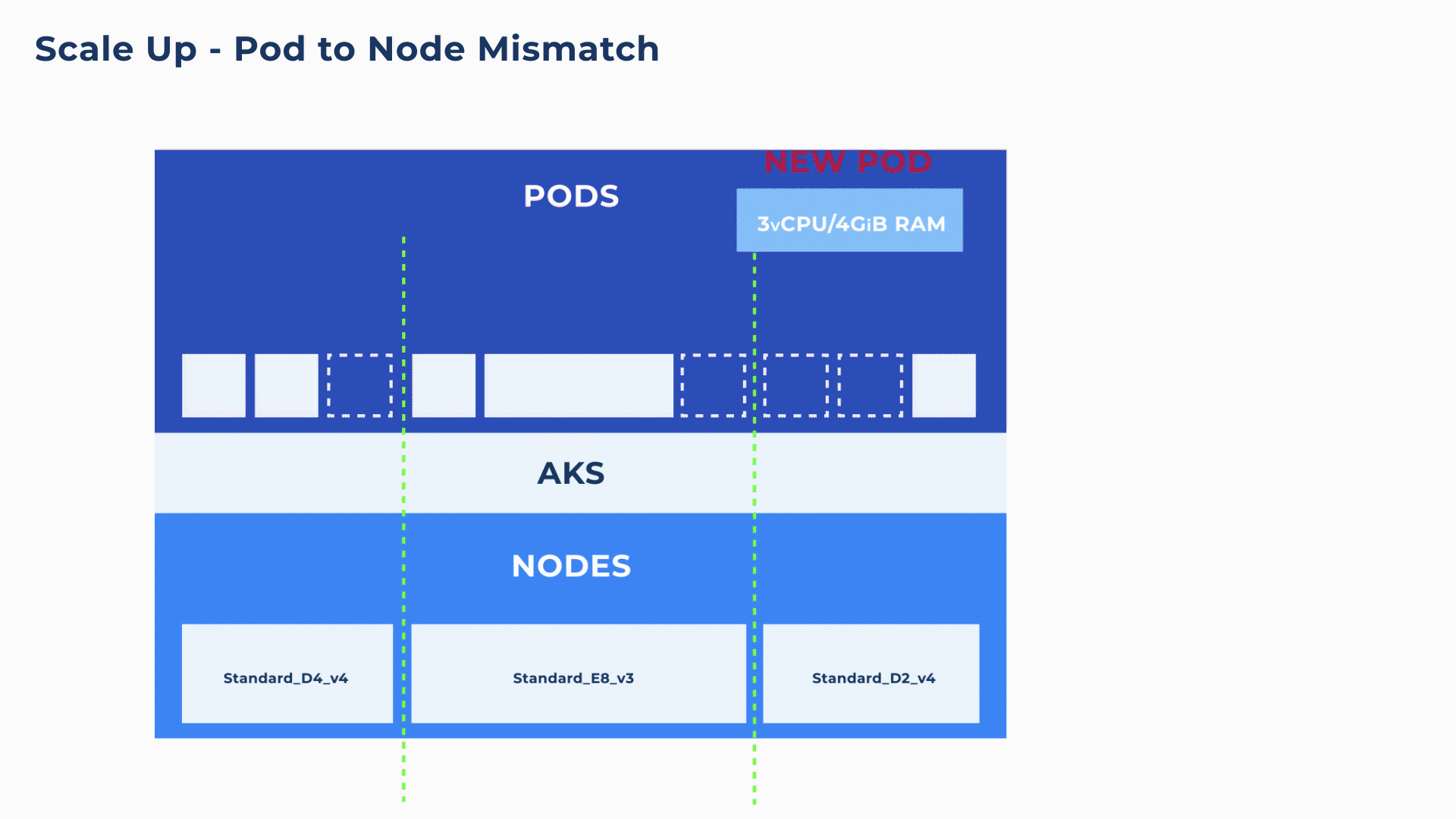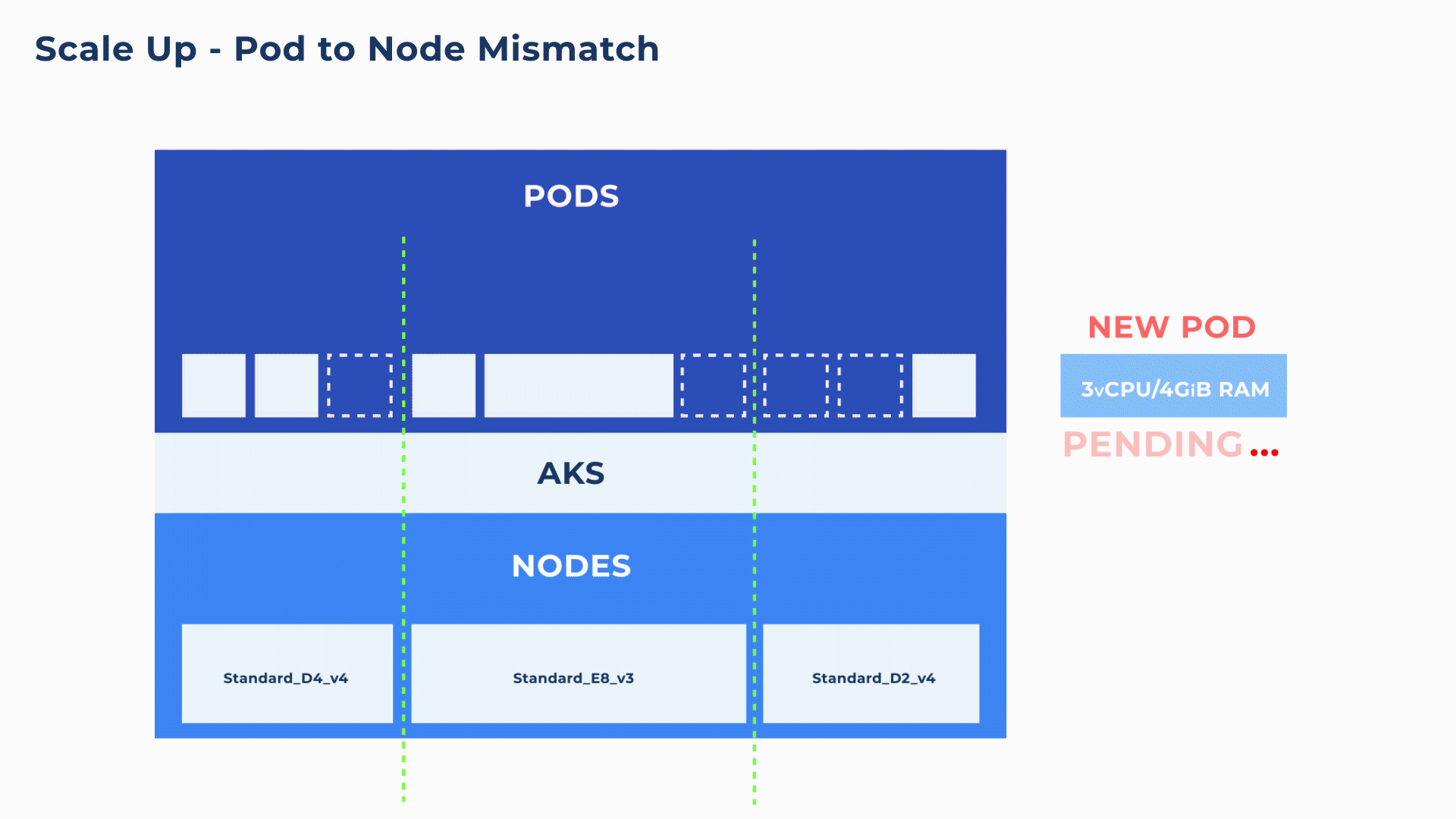
Container-driven autoscaling and bin-packing on blend of different VM sizes
To address these mismatches between pod requirements and the underlying nodes, Ocean proactively looks at the needs of each container and at every available node to make the best scaling decisions. Ocean’s pod-level assessment coupled with the ability to leverage all VM types and sizes, ensures that compute infrastructure is rapidly provisioned as well as perfectly matched to the Pod requests and constraints (e.g. node/pod affinity, VM sizes, GPU specifications, etc.).
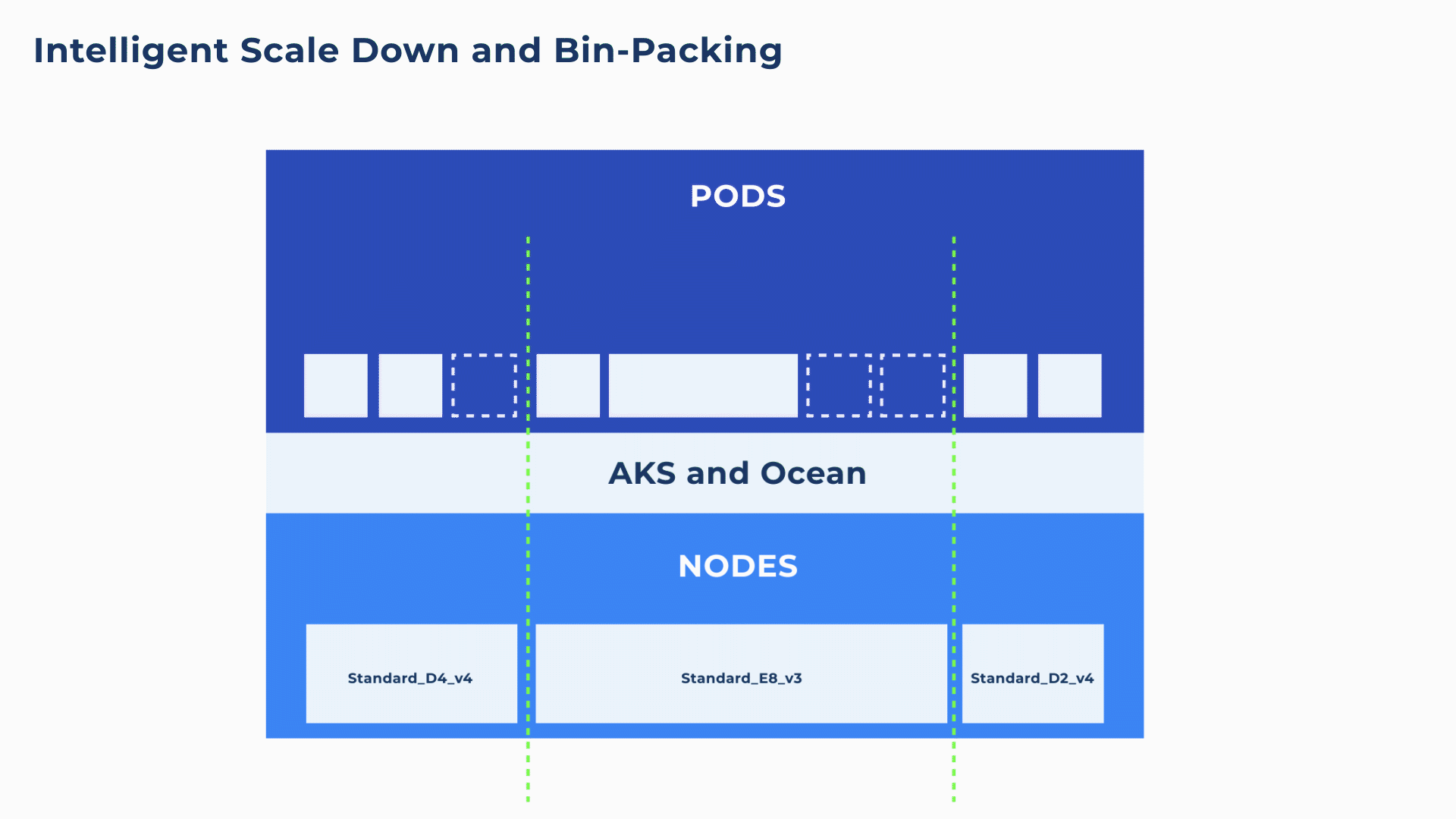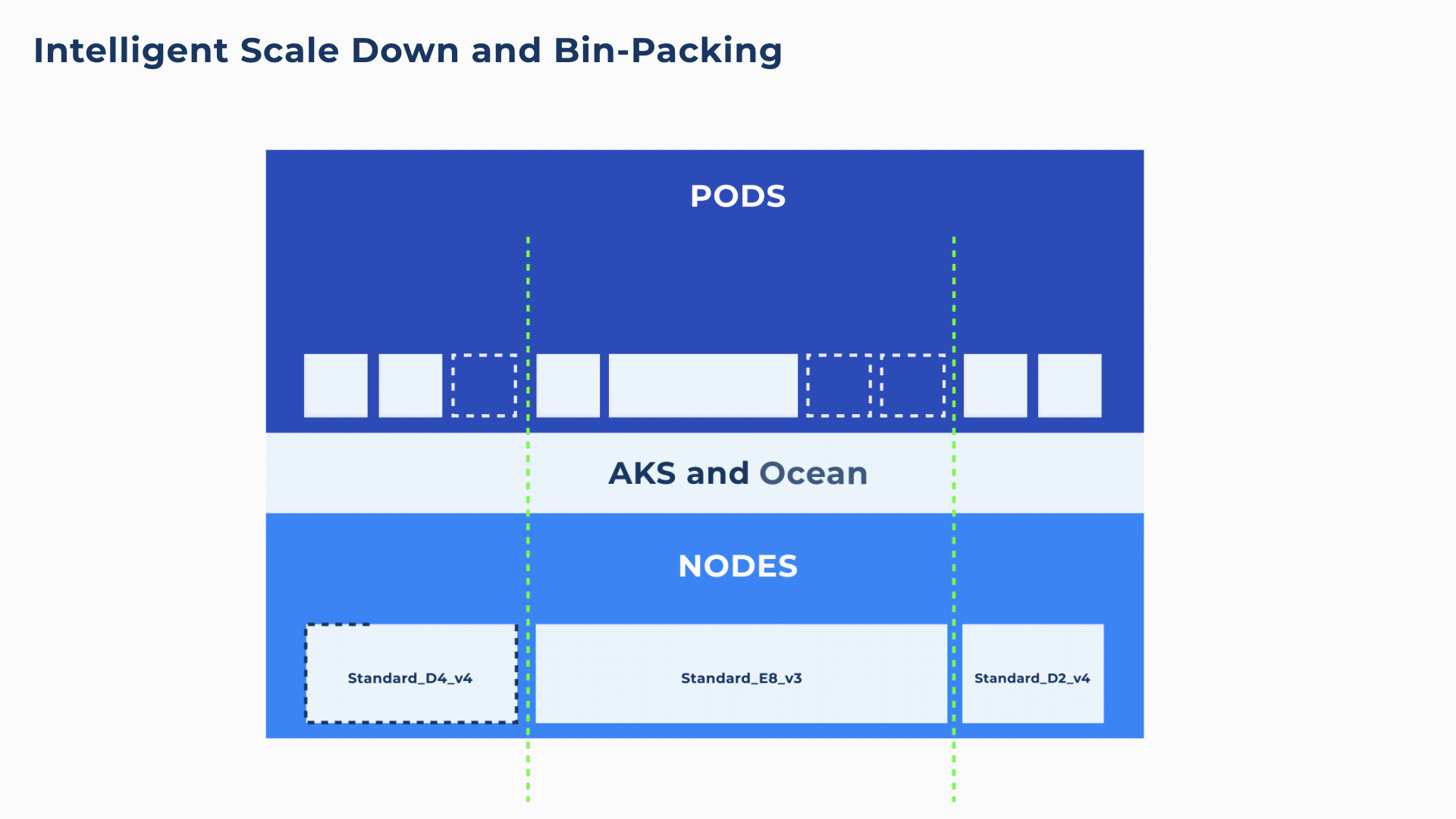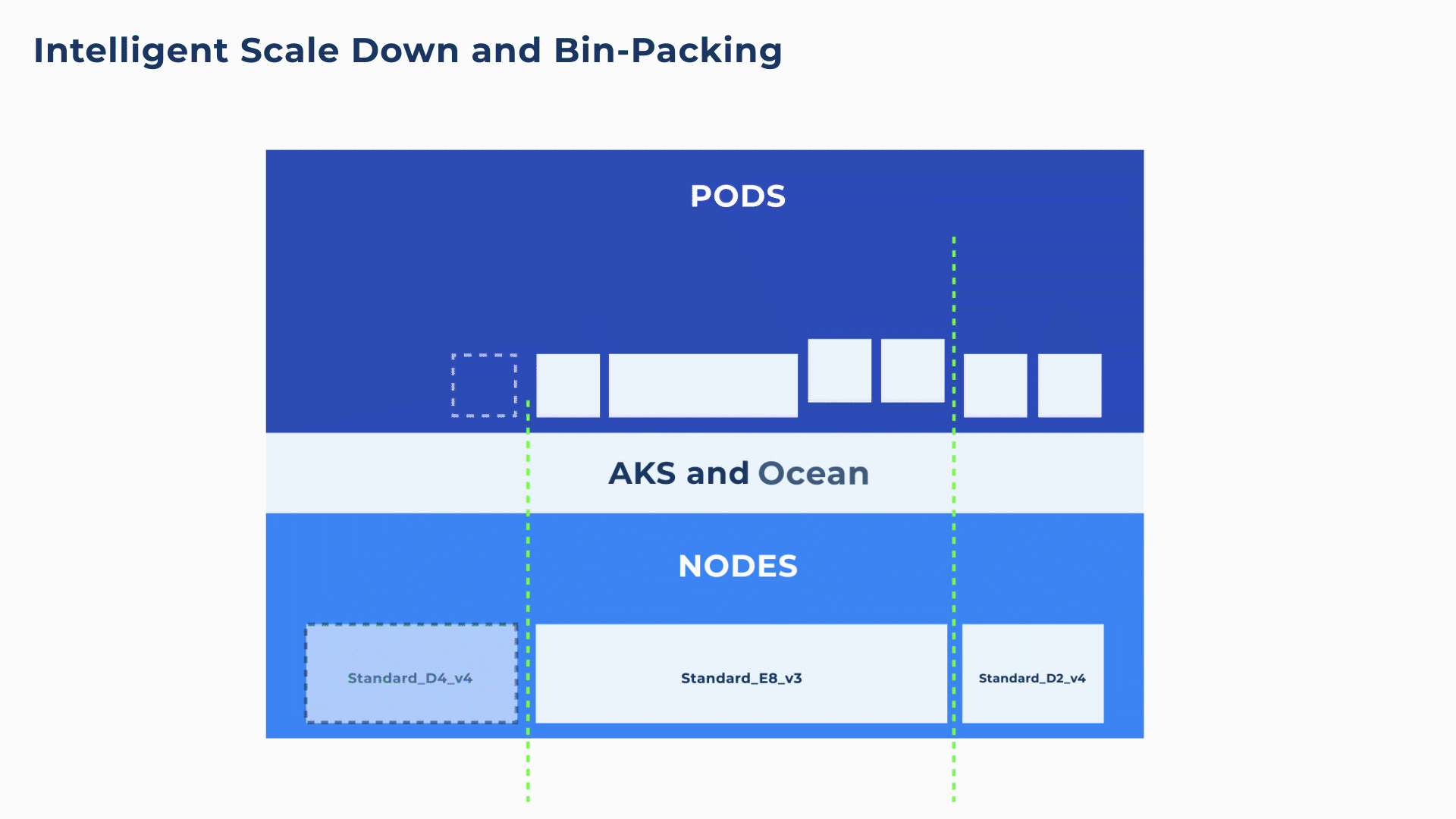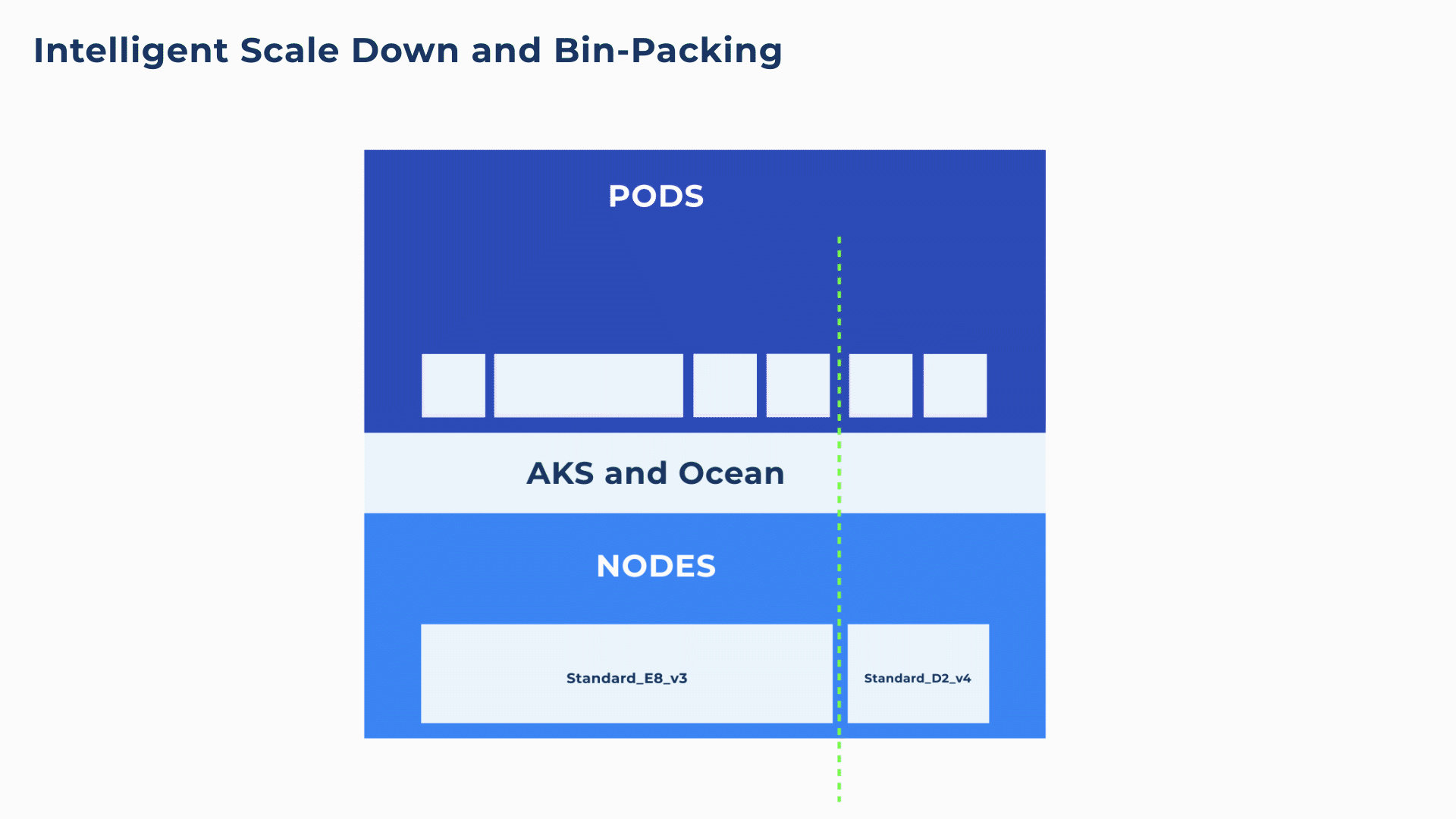
Additionally, Ocean will continuously and proactively scale down excess resources whenever it is possible to reschedule or bin-pack the remaining pods onto other nodes. For example, in the below animation, both the Standard_D4_v4 and Standard_E8_vs3 are ~33% underutilized. Ocean will intelligently deregister and drain the Standard_D4_v4, placing its pods on the Standard_E8_v3 for 100% utilization.
This kind of infrastructure optimization is simply not possible with manual DIY scaling solutions. Even Cluster Autoscaler with its automated DIY bin-packing simulations will only scale down a node when it is more than 50% underutilized.
#2 – Leveraging Azure Spot VMs for production environments
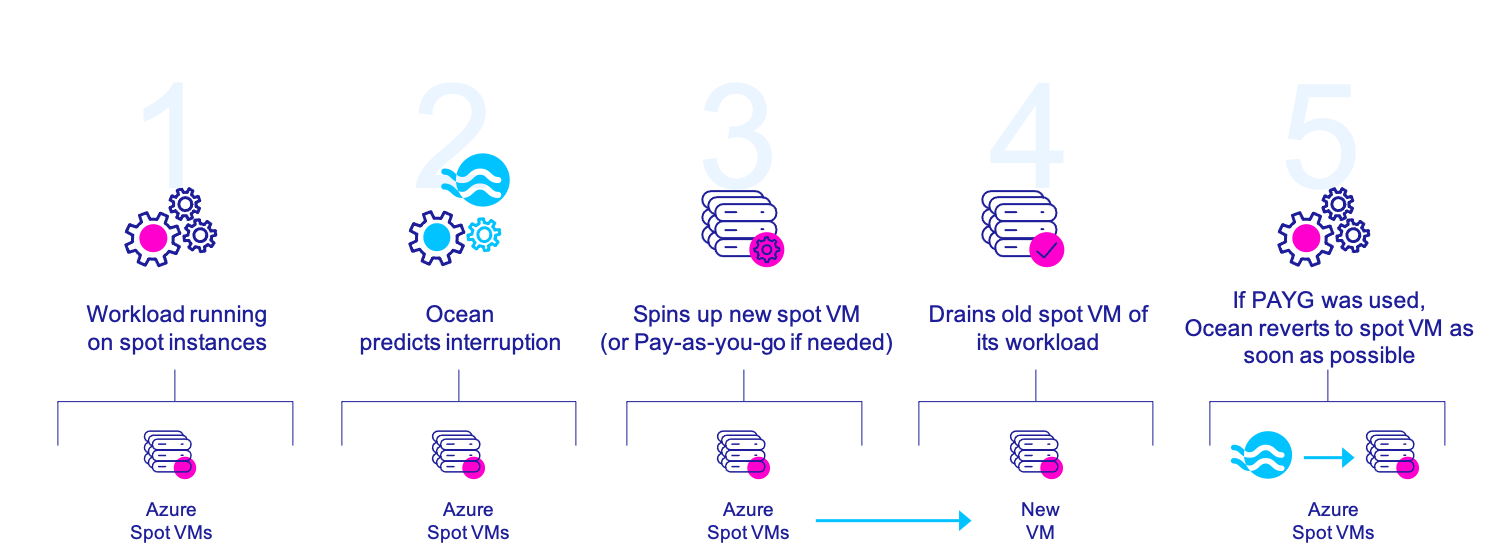
With many organizations looking to optimize their cloud spend, Azure Spot VMs offer an affordable option with discounts of up to 90% in comparison to pay-as-you-go pricing. However, the drawback of these spot instances is that pricing and availability fluctuates based on supply and demand. This can result in AKS workloads being evicted at any time with just a 30 second notification, not exactly ideal for production or mission-critical workloads.
Gracefully manage interruptions on Azure Spot VMs
With Ocean, leveraging Azure Spot VMs for production environments is completely feasible and reliable. Even though Azure can and does evict workloads from spot VMs (either when Azure no longer has available compute capacity or when the current price exceeds the maximum price specified by the user), Ocean is able to gracefully drain workloads and move them to another spot or pay-as-you-go VM, thereby minimizing downtime for workloads and ensuring a 99.99% uptime SLA. In this way, Azure customers can enjoy dramatic cost savings for even mission-critical AKS clusters.
#3 – Over-provisioning for priority workloads
High performing container workloads rely on compute infrastructure to match application demands at a moment’s notice. However, finding the right balance between running close to capacity versus over-provisioning for any potential spikes in demand is not easy and often companies will end up with inflated cloud bills for compute resources that are rarely utilized.
Automated provisioning of infrastructure headroom
To avoid over-provisioning for any compute workloads, Ocean has pioneered “headroom” a built-in feature that adapts and reflects current and potential capacity loads. By understanding the history, metrics and demands of an application, Ocean automatically and dynamically adjusts compute headroom, adding just the right amount of extra compute resources so that applications can scale, and you don’t pay more than you must.
Learn more about Ocean’s automatic and manual headroom.
#4 – Managing workloads with different resource requirements
Managing multiple applications with different requirements for vCPU, RAM, disk type and size, OS and similar, requires significant time and effort. AKS users must create new Node Pools for each application that have a unique set of resource requirements.
Virtual Node Groups for managing different resource requirements in a single cluster
With Spot Ocean, all VM types can be used in a single node group to match every application’s needs. Additionally, VNGs (Virtual Node Groups), a key feature of Spot Ocean, enable users to manage different types of workloads all on the same AKS cluster. VNGs define workload properties, VM types/sizes, and offer a wider feature set for governance mechanisms, scaling attributes and networking definitions. VNGs also give users more visibility into resource utilization with a new layer of monitoring and with more flexibility to manage settings like headroom, block device mapping, tags and governance via maximum number of nodes.
Get started with Ocean for AKS
Whether you are a CIO or a DevOps engineer, automating AKS infrastructure management while dramatically reducing cost can be a real challenge. Fortunately, Spot Ocean from Spot is the easiest, most cost-efficient and flexible way to scale your mission-critical applications in the cloud.