 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

High performing container workloads rely on infrastructure to match application demands at a moment’s notice. From scaling bursts that require instant compute availability, to traffic lulls that create infrastructure waste, it’s important to keep both availability and cost in mind during the life of a production application. Run too close to capacity and a sudden spike could take from a few minutes to as many as 30 to become stable as it waits for pods to be scheduled on infrastructure that needs to be retroactively provisioned. Overprovision for max load and you will be spending more than you have to on resources you’re not using.
Instead, cloud native workloads need a system that can adapt in both situations— understand when load is light, but be ready to deliver when demand rises. Automatic headroom, a concept pioneered by Spot, does exactly this. By understanding the history, metrics and demands of an application overtime, Ocean by Spot is able to automatically and dynamically adjust just the right amount of infrastructure so that applications can scale and you don’t pay more than you have to.
What is headroom?
Most organizations, unwilling to risk performance, prepare for application scale out by adding extra resources to clusters, which sit idle the majority of the time. This pool of extra infrastructure resources is called headroom.
Determining the appropriate amount of headroom that will be enough to handle a scaling burst is a challenge for DevOps engineers. They will often attempt to configure resource requests based on a guess, simulations with a test deployment or just trial and error. Having this buffer of spare capacity, however, is critical to ensuring that applications stay up as traffic increases.
How does headroom work in Ocean?
Ocean takes on the challenges of allocating headroom, needing zero configuration from the user, and automatically allocates appropriate headroom to meet specific workload requirements. Ocean reacts to pending workloads by simulating it on different possible infrastructure types, and then provisions the new cloud infrastructure according to the best match. Since Ocean has proactively saved compute resources, Kubernetes (or any other container orchestrator) can use these nodes and schedule pods on them instantaneously. This headroom is automatically maintained as it is used, without any intervention from the user, and more infrastructure is provisioned to prepare for the next scale up services. Users have the ability to set automatic headroom or define configurations manually.
Automatic headroom
Ocean calculates the total amount of resources (CPU, memory and GPU) allocated in the cluster. By default, 5% (configurable by the end user) of that is set aside as spare capacity. To prepare for the workload scale out, Ocean:
- Monitors and analyzes workload behavior, both historical trends and real-time, and sorts the cluster workloads according to the probability and scope of scale out
- Provisions infrastructure based on these workloads’ resource requests, and with respect to their scheduling constraints
- Continuously maintains headroom to match the percentage of defined resources configured by the user
Manual headroom
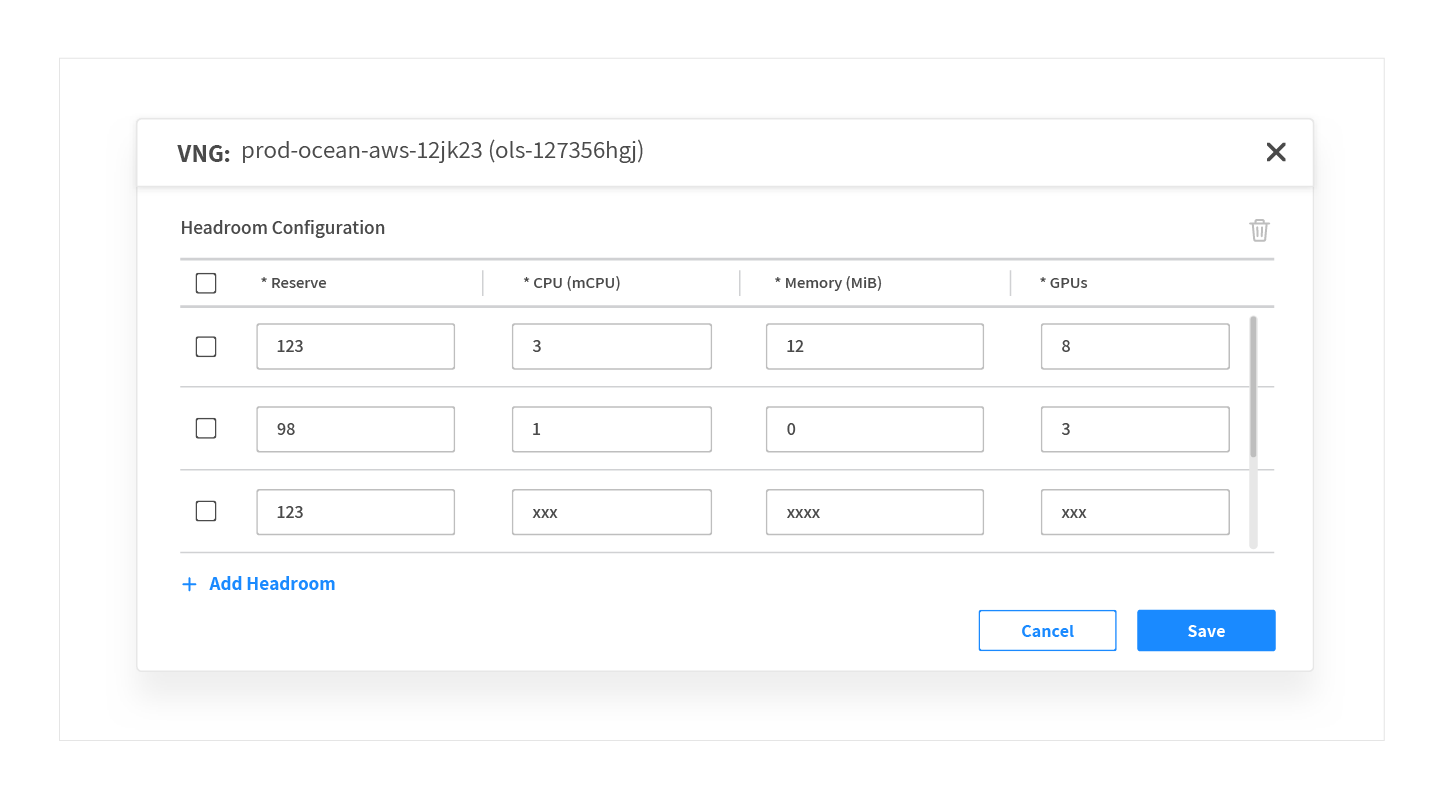
Alternatively, headroom can be configured manually. This approach is effective for cluster administrators who are familiar with their workload’s scaling behavior and want to save a fixed amount of headroom. When manual headroom is set instead of automatic headroom, it is possible to define a specific amount of headroom for each Virtual Node Group (VNG).
The definition is very flexible and allows users to set values where each can contain a different amount of resources (CPU, memory, GPU). This is so headroom can be configured to be used by workloads designed to run on the VNG.
Current Ocean users that want to switch to manual mode, should use the Actions menu and select Customize Scaling.
What does headroom look like in Ocean?
Ocean users will now see a new headroom composition chart in the Ocean dashboard, giving complete visibility and understanding of headroom across the cluster. For ease of management, this feature consolidates headroom visibility and configuration options directly in a new visualization in the Ocean dashboard.
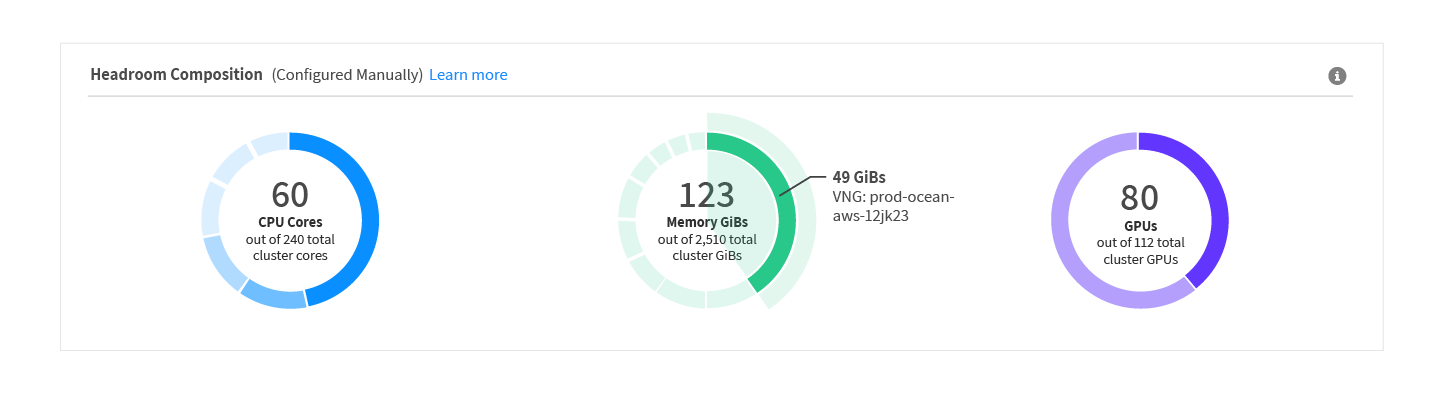
Users will see the overall amount of existing headroom in the cluster by resource type (CPU, memory, and GPU), and get a granular view into headroom spread across different VNGs.
Within each VNG, users can see a breakdown of how resources are being utilized, if any are sitting idle (which Ocean minimizes as much as possible), and the rationale for how headroom was calculated. In the images below, you can see how CPU and memory resources are being consumed as workload cores, headroom or sitting idle.
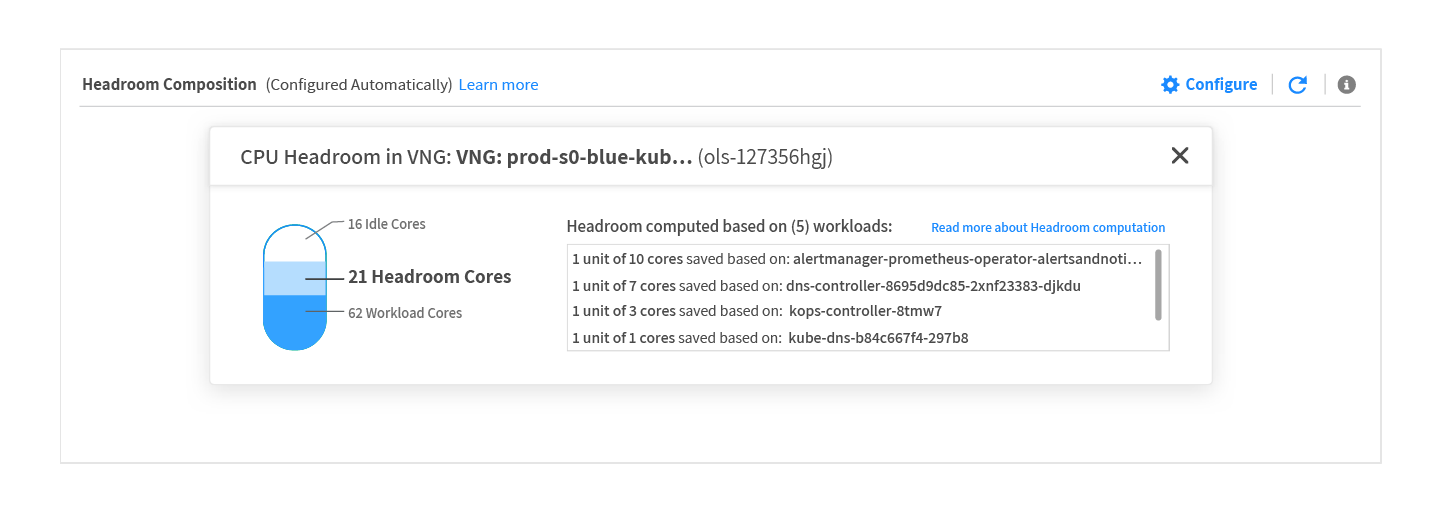

*Please note that the above views of CPU and memory headroom utilization will be available in Ocean dashboard in the coming weeks.
Users can continue to configure headroom settings manually when needed.
With these advanced and automated headroom capabilities, users can rest assured that their workloads always have the infrastructure they need for instantaneous scheduling without risk of overprovisioning and wasted resources.
Ocean headroom is in GA for Ocean K8s on AWS and GKE, with Azure coming soon. You can get started using it immediately in your Ocean console. Check it out today!