 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOpsGet the most out of your cloud investment
Our solutions combine machine learning and analytics with decades of operations expertise to simplify, automate and optimize operations for your cloud infrastructure, freeing teams to focus on delivering impactful applications without being overburdened by operations and infrastructure.


I think of Spot not just as a cost optimization platform, but as our container experts.


How our products can help

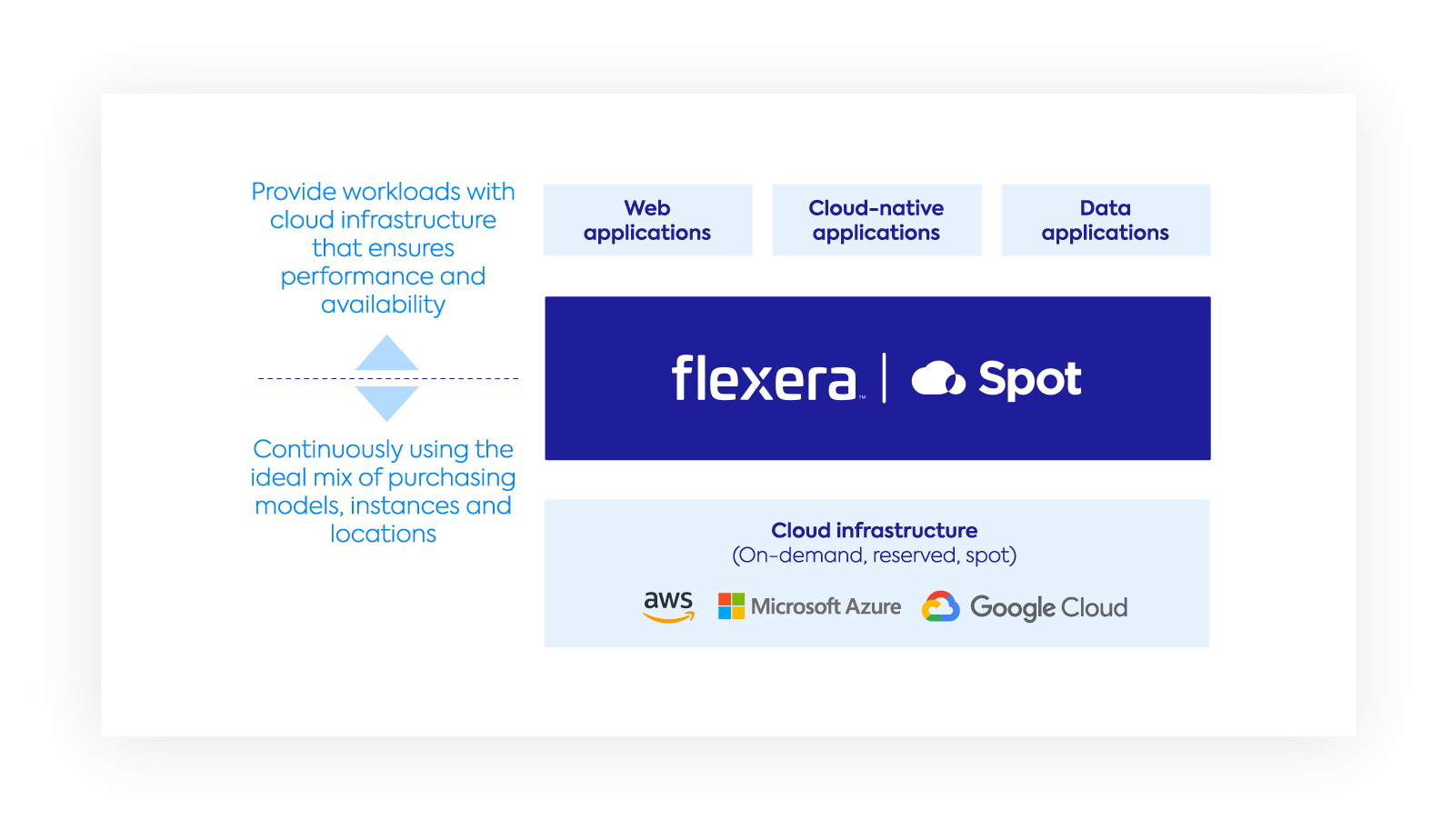
Avoid service disruption while utilizing a balanced blend of spot, reserved and on-demand instances without compromising availability and reliability. Spot delivers availability and performance across all types of cloud compute resources using sophisticated machine learning and analytics to predict interruptions and auto-replace instances.

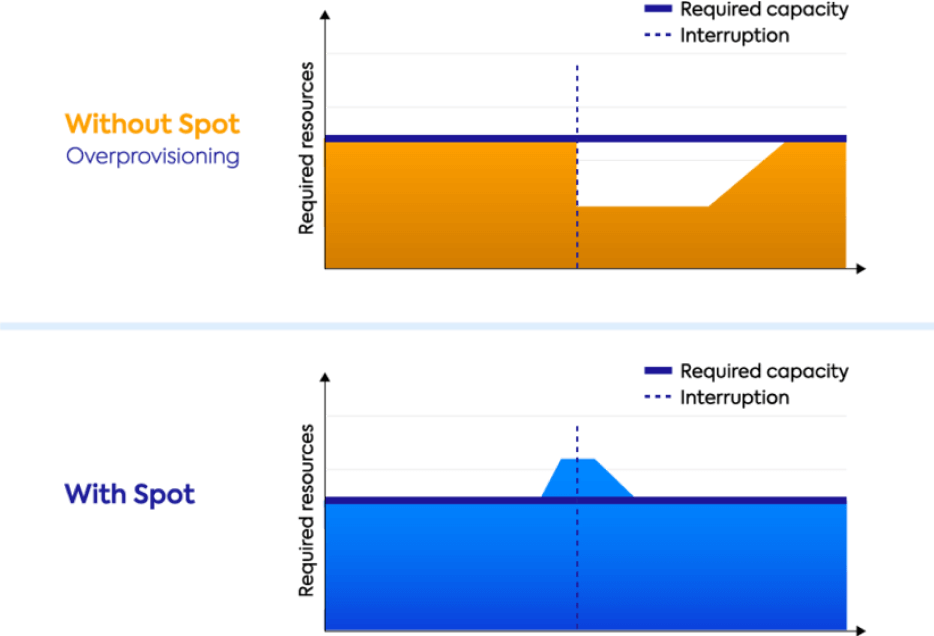
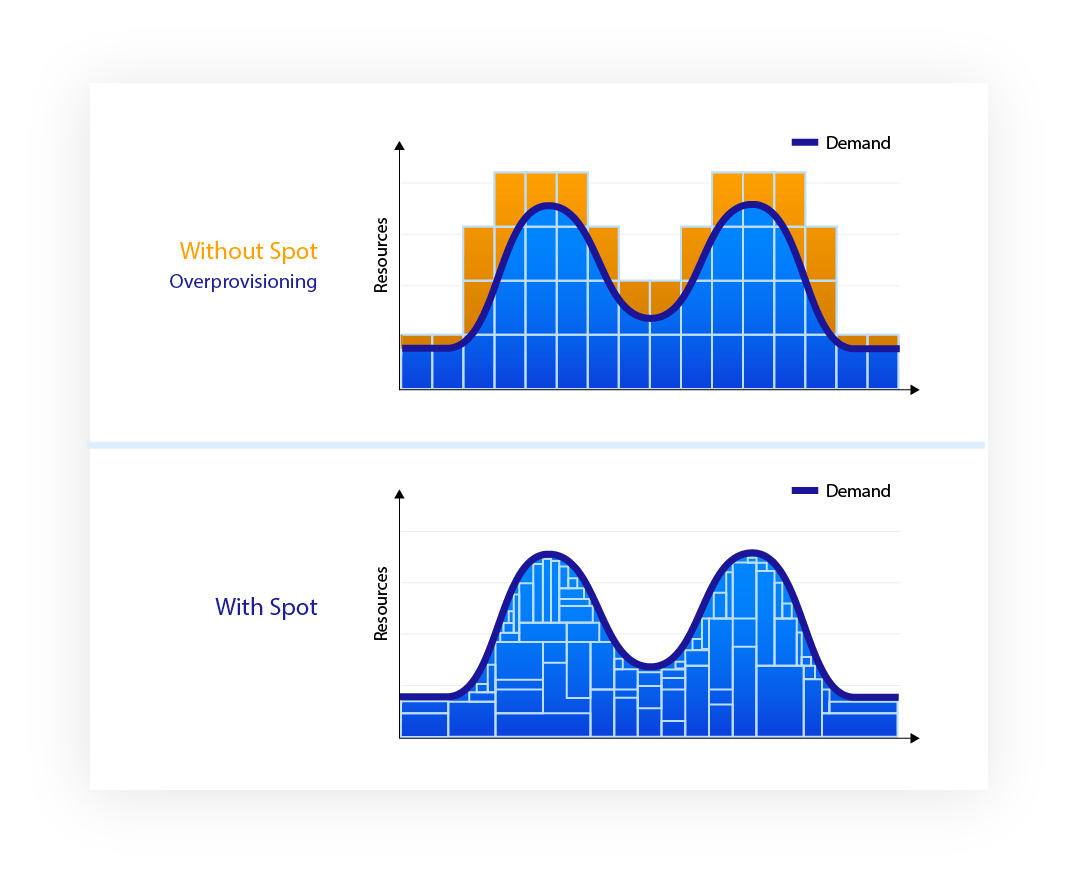
Workloads get exactly the resources they need, when they need them, avoiding overprovisioning and reducing wasted resources. Spot’s technology assesses and predicts resource requirements and autoscales your infrastructure in the most efficient way possible.

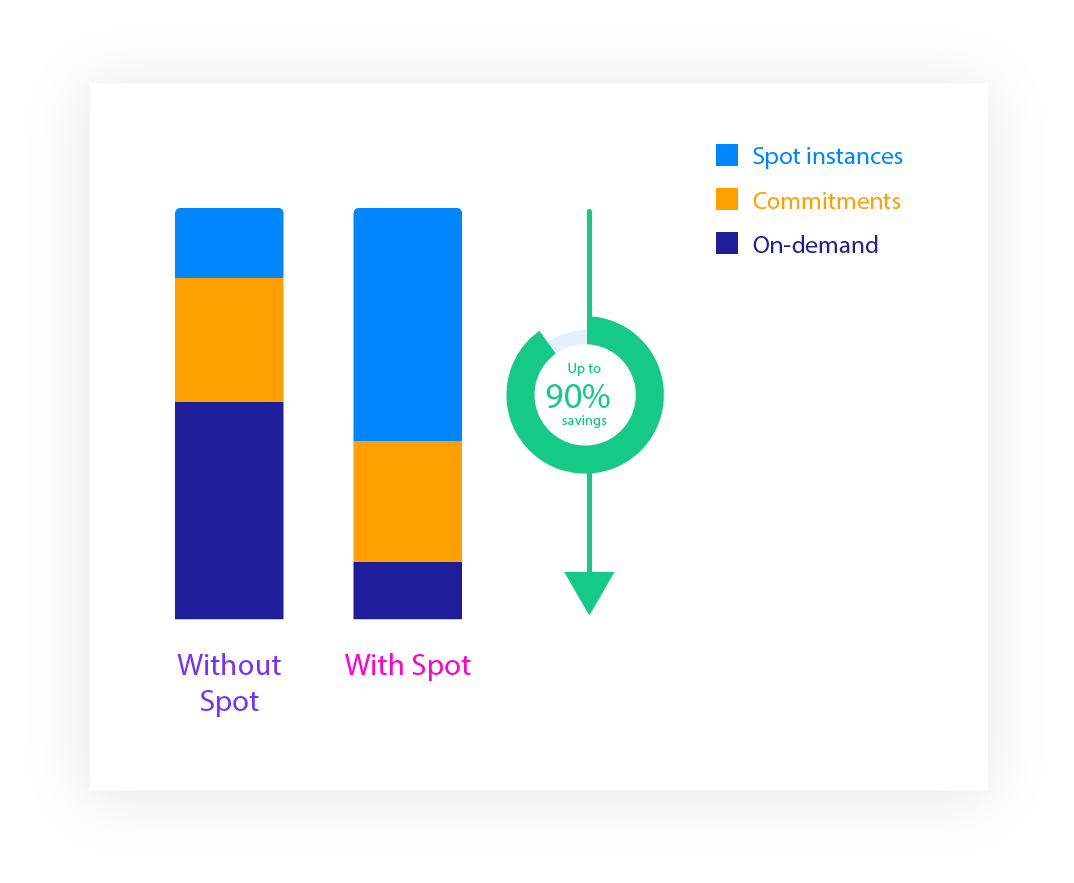
Identify where and how you can save up to 90% without changing or rearchitecting your applications. Spot provides insights, guidance and automation across all your cloud infrastructures to understand and optimize your cloud spend.
Ensure availability & performance
Avoid service disruption while utilizing a balanced blend of spot, reserved and on-demand instances without compromising availability and reliability. Spot delivers availability and performance across all types of cloud compute resources using sophisticated machine learning and analytics to predict interruptions and auto-replace instances.
Continuously optimize cloud resources
Workloads get exactly the resources they need, when they need them, avoiding overprovisioning and reducing wasted resources. Spot’s technology assesses and predicts resource requirements and autoscales your infrastructure in the most efficient way possible.
Reduce cloud infrastructure costs
Identify where and how you can save up to 90% without changing or rearchitecting your applications. Spot provides insights, guidance and automation across all your cloud infrastructures to understand and optimize your cloud spend.
Learn about our products for automated, optimized cloud operations

Cloud cost management and optimization
Understand, control and optimize cloud costs without sacrificing flexibility, all while driving application efficiency and business performance, with Eco for commitment optimization and CloudCheckr for cloud cost management.
Infrastructure automation and optimization
Continuous automation and optimization solutions, including Elastigroup for virtual machines, Ocean for containers and Kubernetes, Ocean CD for containerized application delivery, and Spot Security for security analysis and threat reduction.