Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps
When EC2 instances fail to serve requests the usual cause is typically hardware issues or high CPU utilization. To avoid sending traffic to instances with these issues, AWS continuously monitors instance health and routes inbound traffic accordingly.
In the past Elastigroup fetched the health status for all managed instances and triggered an automatic replacement once an instance was determined as unhealthy. That helped maintain the target number of healthy instances running and serving requests in the cluster at all times.
However, in some cases customers prefer to continue running the unhealthy instances rather than automatically replacing them (primarily for root cause analysis and to assess if health status is actually a real issue).
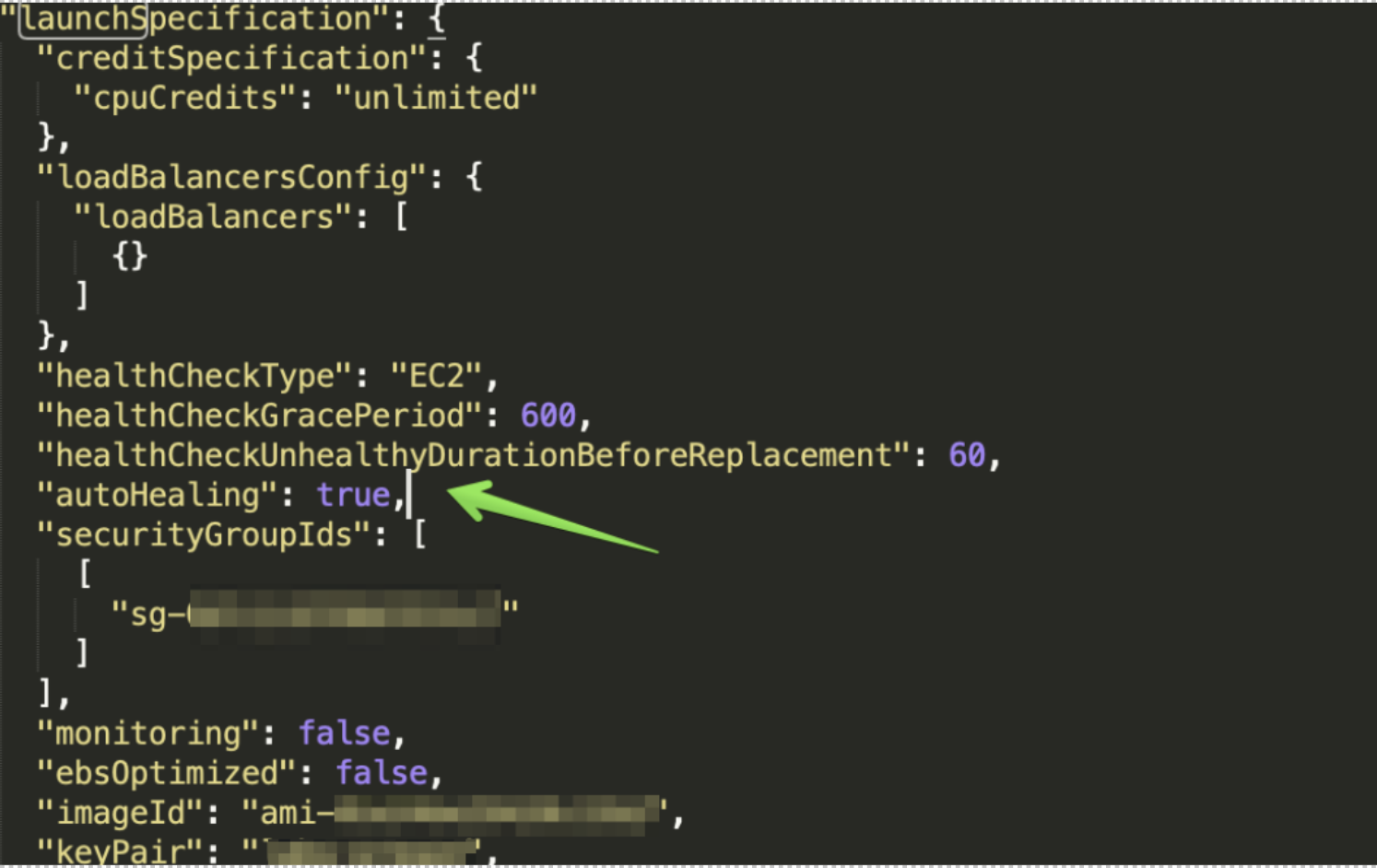
New auto-healing configuration
To address this Elastigroup has released a new auto-healing parameter in which customers will be able to define the desired behavior for unhealthy instances, separating the health checks from the replacement function.
Getting started
You can configure the autoHealing value in Spot’s API and define whether an unhealthy instance will be automatically replaced or not.
If you set the autoHealing parameter to be false then Elastigroup will not replace unhealthy instances. If set to true (default) then all unhealthy instances will be automatically replaced.