 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

The classic problem with autoscaling groups is to find the ideal scaling threshold and target number of instances. Even though you want to run applications at a particular Target CPU utilization, the scaling policies always lag behind your actual usage. To cover most scaling scenarios, you will need to figure out what your CPU usage looks like, and then configure a bunch of scaling policies with different thresholds. Even so, you might still find situations where workloads are starving for more CPU during peak times or are oversized during dips in CPU usage. Elastigroup predictive autoscaling mitigates this problem by staying ahead of your demand.
Elastigroup predictive autoscaling uses a machine learning algorithm to accurately predict the CPU utilization pattern of your workloads and increase the number of instances based on the projected CPU utilization. Predictive autoscaling also helps in cases where your instances/applications take a lot of time to boot up. Predictive autoscaling can scale the instances in advance of the actual traffic and thus saving up to 30 minutes of startup time.
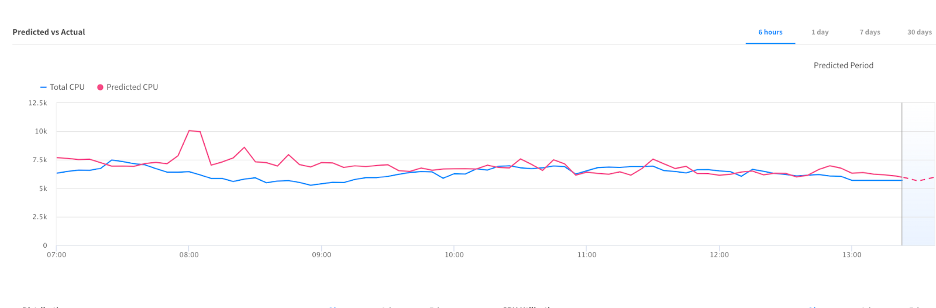
The machine learning algorithm builds a forecast based on historical data, and as you can see in the below graph, it ensures the predicted CPU utilization stays close to the actual CPU utilization in advance with the least configuration effort on the client’s side.
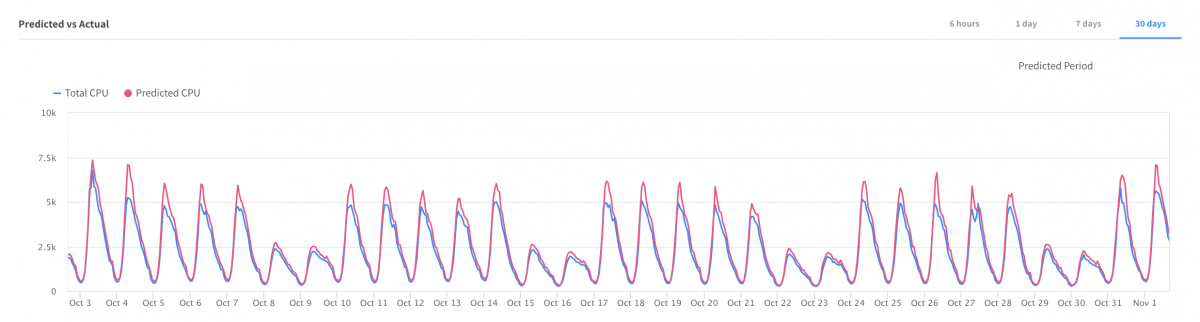 Furthermore, autoscaling groups using spot instances are often configured with different vCPU instance types. The Elastigroup autoscaling policy ensures that the CPU utilization threshold configured in the policy is maintained across the various instance types. Through accurate scaling across instance types, the underutilization/overutilization with different vCPU instance types can be avoided. Thus, giving you the option to increase your instance type list and spot markets.
Furthermore, autoscaling groups using spot instances are often configured with different vCPU instance types. The Elastigroup autoscaling policy ensures that the CPU utilization threshold configured in the policy is maintained across the various instance types. Through accurate scaling across instance types, the underutilization/overutilization with different vCPU instance types can be avoided. Thus, giving you the option to increase your instance type list and spot markets.
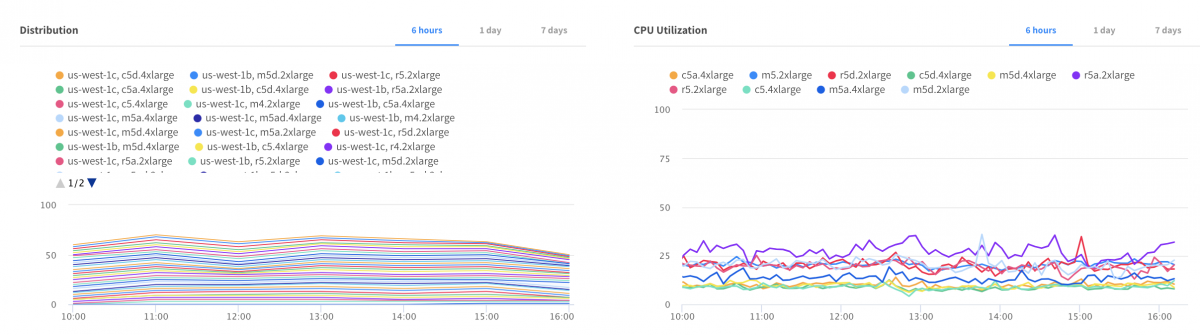
How it works
Elastigroup predictive autoscaling uses machine learning algorithm to accurately predict the CPU pattern of your workloads and increase the number of instances based on the predicted pattern and the Target CPU value to be maintained. The machine learning algorithms collect the cluster’s metrics, such as CPU utilization over time and creates a baseline that will eventually acts as a predicted metric of the cluster’s future load. Once the predicted metric value of the Elastigroup is determined, a calculation begins to find out the minimum number of instances required to handle the predicted load of the cluster. The autoscaling algorithm is based on a gradient boosting model that has been trained on thousands of different customer behaviors.
The model can predict the behavior of a group after observing CPU utilization for a week. If your cluster already has “Target-Scaling” policies configured, the learning period has already started, which will shorten your time to value for the predictive autoscaling.
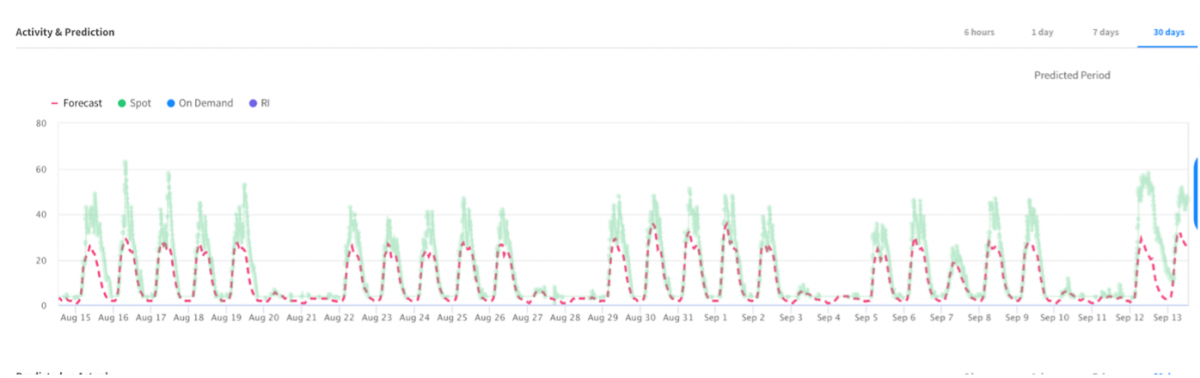
How to configure predictive autoscaling
Predictive autoscaling is configured in a Target Scaling Policy. You can enable it when you create an Elastigroup or by editing an existing Elastigroup. Do the following:
1. In the Elastigroup, go to the Scaling tab.
2. Under Target Scaling Policies, click Add, and then click on the policy name to open the form.
3. Complete the following in the form:
- Policy Name: Enter a name for your policy.
- Metric Name: Choose “Average CPU Utilization.”
- Target Value: The desired average value of the metric that will be tracked.
- Cooldown: Enter the cooldown duration in seconds.
4. Mark “Use predictive autoscaling”, and choose the mode:
- Predict and scale: In this mode Elastigroup will not only present its predicted data but will automatically scale up instances in advance according to the calculated Forecast value.
- Predict only: This mode allows you to analyze the predicted metric values, without automatically scaling the cluster according to these values.

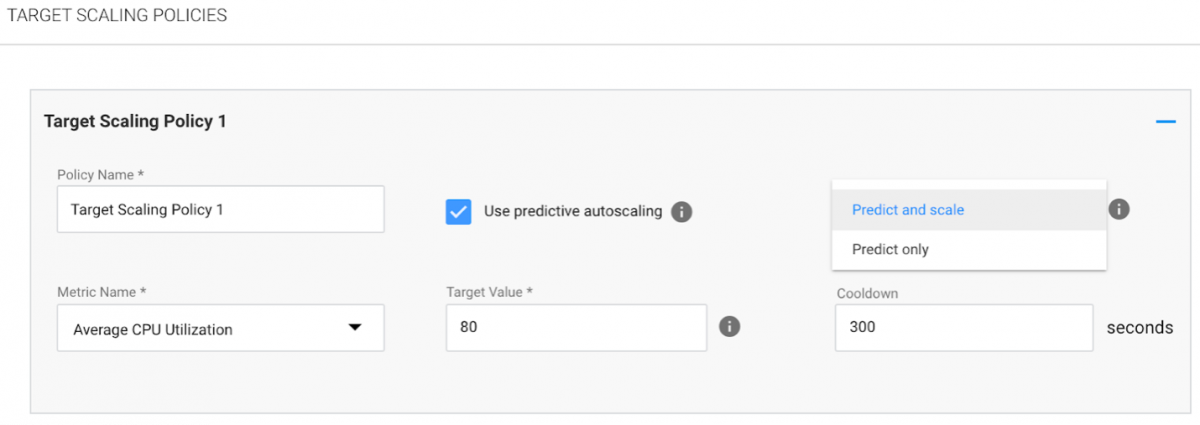
5. To save the configuration, click Next, and then click Create or Update at the bottom of the Review tab.
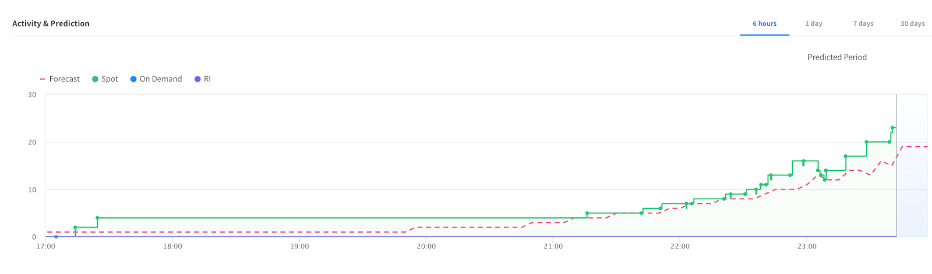
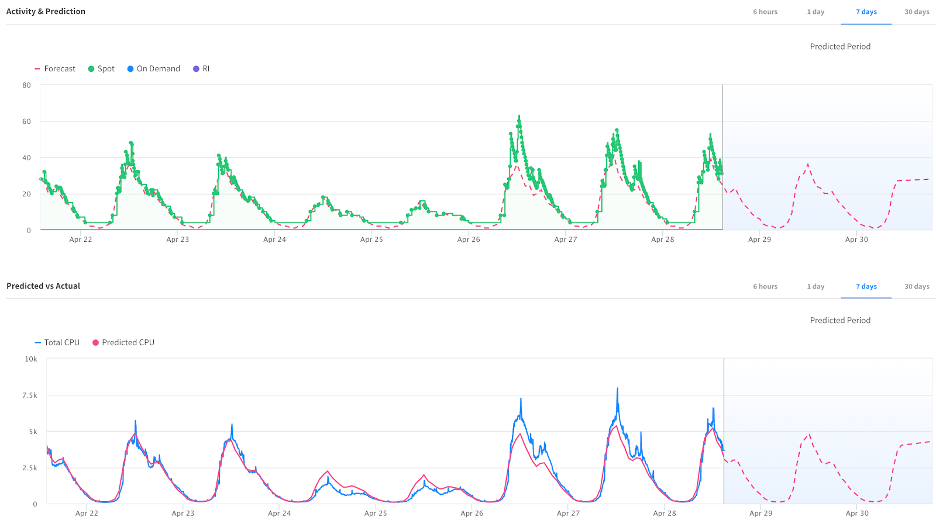
After you enable the scaling policy with predictive autoscaling, below graphs will appear in the Elastigroup Overview page that shows “Activity & Prediction.”
Summary
Elastigroup predictive autoscaling simplifies defining scaling policies by continuously monitoring and reacting to your workload’s demand. It can accurately predict the CPU utilization peaks and dips of your workload and automatically scale the optimal capacity ahead of time. It reduces latency due to instance and application bootup time by scaling instances in advance of the demand. Predictive autoscaling paired with Predictive Rebalancing ensures spot instances are run with high savings and production-grade availability by predicting the workload usage and spot interruptions in advance.