 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

NetApp is pleased to announce General Availability of its Spot Ocean for Apache Spark™ product on the Microsoft Azure cloud. Customers can now choose to have Spot optimize and manage their AI and data engineering projects at scale on many kinds of infrastructure.
Spot’s SaaS product removes the effort, complexity, and risk of setting up and running Apache Spark yourself. It also improves the performance and efficiency of data scientists’ Jupyter Notebooks. Key features of Ocean for Apache Spark on Azure include:
- Automated and optimized utilization of Azure spot instances to reduce your infrastructure costs.
- Transparent and optimized Kubernetes infrastructure management, including shutdown hours, right sizing, scale, headroom, and bin packing to reduce costs without sacrificing application performance.
- A detailed history of your Apache Spark application runs and configurations, so that you can track how resource changes affect performance and cost.
- Wizard and template configuration for AKS Kubernetes and Apache Spark provisioning, upgrading, and autoscaling, to save you time. Our DevOps-friendly Docker images simplify dependency management. Our Terraform scripts allow you to standardize your deployments.
- Dashboard insights that enable your developers to troubleshoot and track the improvements of their applications over time.
- Detailed visibility into charges, filtered by time, job, and user, to help you to tame costs.
- 24x7x365 monitoring and expert support.
Gain insight into Spark application performance
We recognize that Spark development and debugging can be challenging, and we’re here to help.
With our resource utilization tools, you can understand exactly how your Spark application is performing, identify which resource (I/O, memory, CPU, garbage collection) is affecting application execution, and resolve the bottleneck more efficiently. Our charts give a comprehensive view of several metrics over an extended period of time. Additionally, we save Spark historical logs — driver, Kubernetes, and executor — so that our UI dashboard can reconstruct the story of your application and recommend improvements.
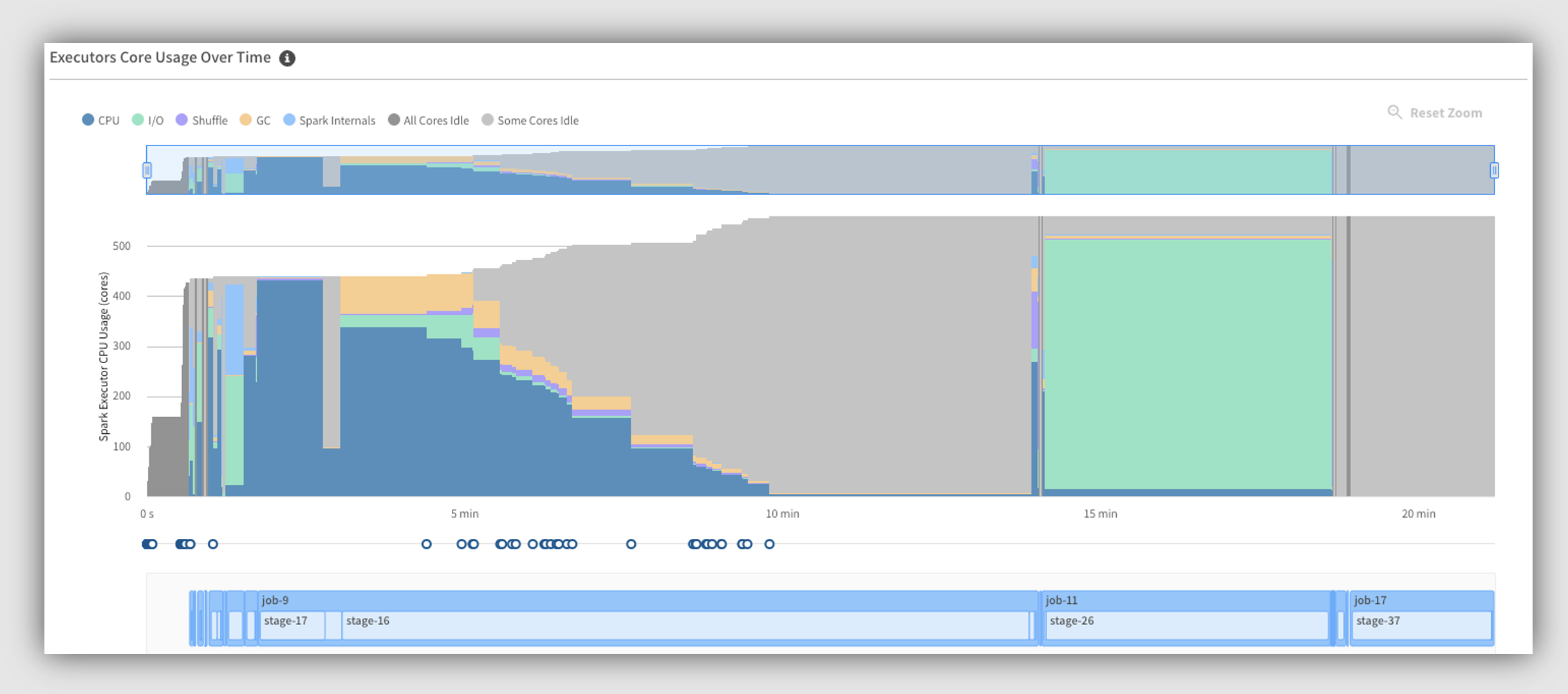
The following example chart shows an application that is mostly idle during the second half. Our recommendation is to reduce resources by 10% in that later stage.
In particular, during “job-11” there is a lot of I/O, and we have two suggestions to address this: you should consider adding SSD if your application is writing a lot to disk, and you might have too many files in a partition.
Lower application costs while improving reliability and availability
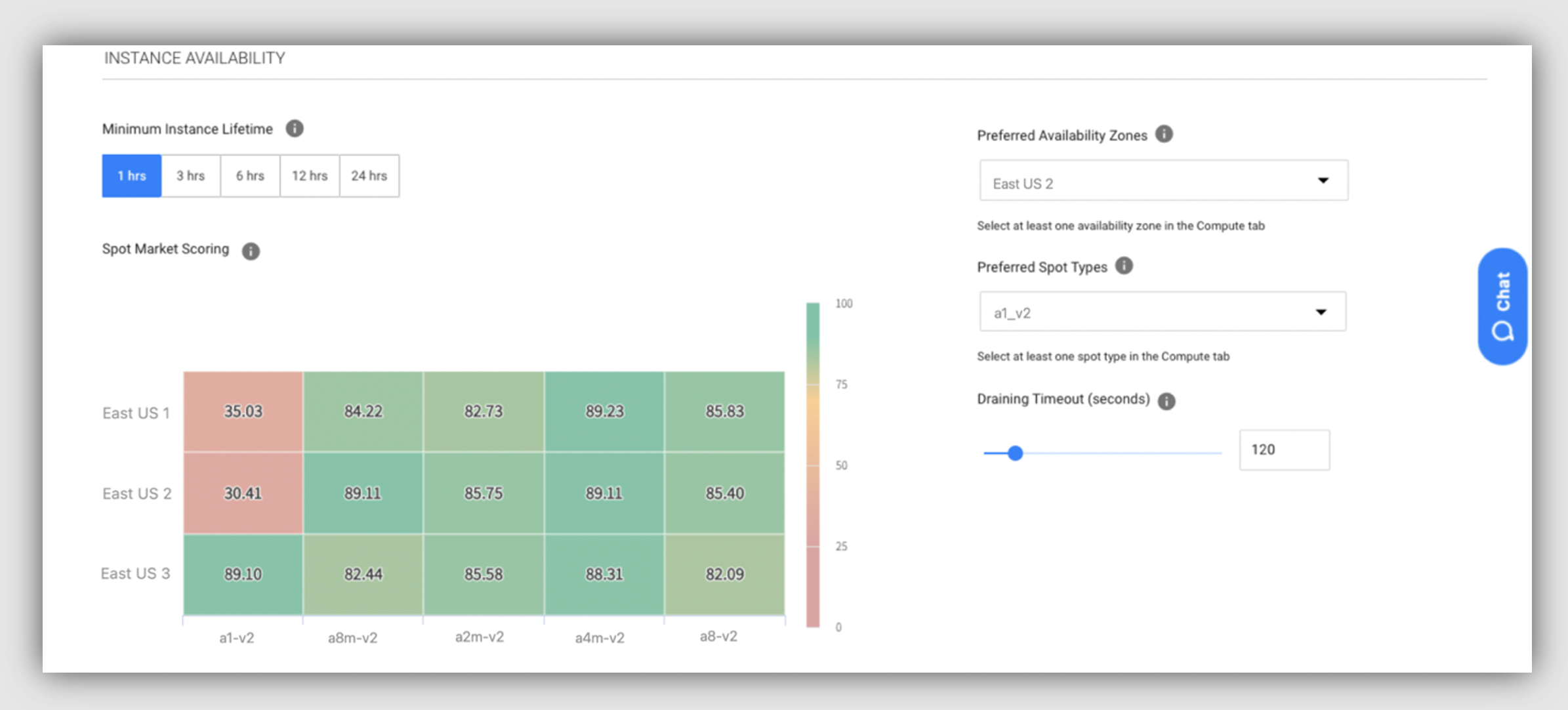
With its intelligent spot instance selection, Ocean for Apache Spark removes the need to pair applications with specific Azure instance types. Our SaaS platform chooses at runtime the spot instance type that has the highest availability, lowest price, and lowest likelihood of a spot kill. This flexibility can improve application duration and reduce spot kills by up to 79%. Our engine seamlessly switches among reserved instances, spot instances, and on-demand instances to give you the best performance-to-cost ratio.
Integrate your existing data tools
Ocean for Apache Spark supports the execution of Jupyter Notebook through Microsoft VS Code, and it integrates with schedulers like Airflow and Azure Data Factory. We have a robust REST API that makes it easy to submit Spark applications from anywhere. Ocean for Apache Spark provides application-level metrics like data read/written, shuffle data, CPU utilization, and cost, which enable a developer to troubleshoot and to track improvements in his application. By building on top of open source, cloud-native technology, Ocean for Apache Spark natively interfaces with the most popular tools from the Kubernetes ecosystem: observability, networking, security, cluster management, and more.
Try Ocean for Apache Spark on Azure
We’ve helped many customers migrate their Spark workloads to Spark on Kubernetes, allowing them to reap all the benefits that Ocean for Apache Spark has to offer. Statisticians around the world from the United Nations Global Big Data Platform leverage Ocean for Apache Spark to simplify their work and reduce their costs. Data integration product Lingk.io migrated from EMR to Ocean for Apache Spark, achieving large savings while improving their end-users’ experience.
Request a demo with a solution architect.