 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

What is container driven autoscaling?
Whether you’re using a managed Kubernetes service like AWS EKS, GCP GKE or Azure AKS, or self-managing a DIY cluster deployed with open source tools like kops and Kubespray, the underlying hardware can vary from container to container. Each container requires specific resources (CPU/ memory/GPU/network/disk) and as long as the underlying infrastructure can provide those resources, the container will be able to execute its business logic.
In practice, when scheduling containers, Kubernetes verifies their requirements are met, but it does not take into account the size, type or price of instances that a container runs on, only that it has enough to do so. Often, users overprovision infrastructure to ensure applications stay up and running, but this results in enormous cloud waste and unnecessary spending.
Container-driven autoscaling is an approach that aims to reduce overprovisioning and enable high performance by giving containers the most optimized infrastructure possible, based on the requirements and constraints specified at application-level. Container and pod characteristics like labels, taints and tolerations define the kind of instance that it gets matched to.
The importance of picking the right machine type
Container orchestration platforms such as Kubernetes require users to handle the scaling of both the underlying infrastructure (e.g adding/removing nodes from the cluster) as well as workload-level pods. Kubernetes does offer pod scaling services for adding and removing containers (horizontal pod autoscaler) and modifying resources for specific containers (vertical pod autoscaler), but has no native infrastructure scaling or management capabilities.
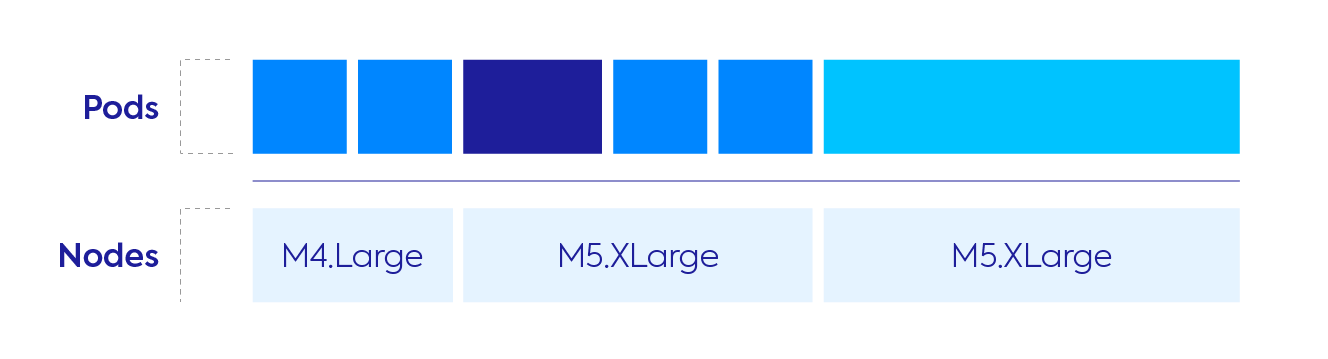
Managing the infrastructure of a Kubernetes cluster is a challenging task and often requires support of multiple machine types with various hardware features in order to meet application needs. To do this effectively, users end up managing multiple node groups that each support one machine type (or multiple types with similar hardware capacity). Each application has its own requirements for instance shapes and sizes, and as the number of nodegroups increases, so does the amount of wasted infrastructure resources.
Read more on that challenge and explore examples of how choosing the correct machine type could lead to dramatic cost reduction in the following blog post.
How does Ocean work?
Ocean, Spot’s serverless infrastructure engine, takes the container-driven scaling approach and allows users to support an unlimited number of machine types and sizes in one node group. This dramatically simplifies infrastructure management and results in substantial cost reduction. By monitoring events at the container-level, Ocean can automatically scale the right size and type of infrastructure to meet application requirements, at the lowest possible cost.
In this article, we’ll cover how Ocean by Spot implements Container Driven Autoscaling infrastructure.
Ocean integrates with the Kubernetes cluster using a controller Pod, which communicates with the Kubernetes API on one end, and the Ocean SaaS backend on the other.
The Controller fetches the metadata of the Kubernetes resources deployed on the cluster (for example Pods, Nodes, Deployments, DaemonSets, Jobs, StatefulSets, PersistentVolumes, PersistentVolumeClaims, etc) and sends it to the Ocean SaaS. Ocean SaaS analyzes the workload requirements in real time and makes smart decisions to scale the cluster up and/or down.
In fact, the Ocean autoscaler constantly simulates the Kubernetes Scheduler actions and will act accordingly to satisfy all the Kubernetes resources needs.
Ocean considers the following Kubernetes configurations:
- Resources requests (CPU, Memory, and GPU)
- nodeSelectors
- Required affinity & anti-affinity rules
- Taints & tolerations
- Well-known labels, annotations and taints
- Spot proprietary labels and taints
- cluster-autoscaler.kubernetes.io/safe-to-evict: false label
- Pod disruption budgets
- PersistentVolumes & PersistentVolumeClaims
- Pod topology spread constraints
Scale Up
When in need, Ocean will decide to increase the cluster worker node capacity by adding new nodes to the cluster.
There are two main reasons for a scale-up event:
- Pending Pods that the Kubernetes Scheduler cannot place on existing nodes
- Missing headroom
Scale Up Process
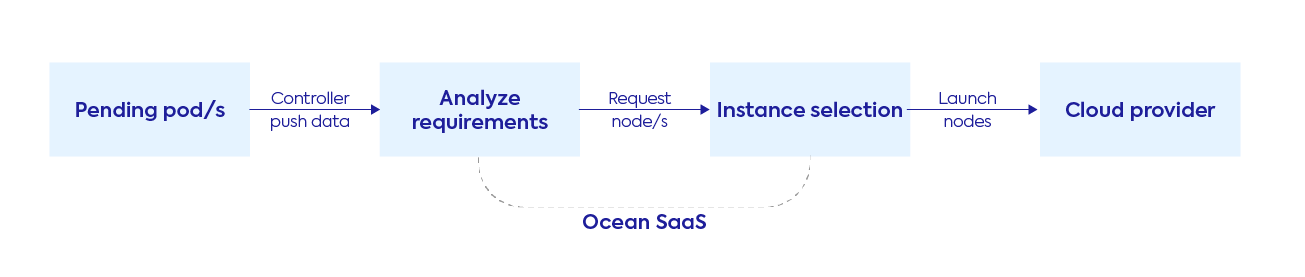
- The Controller Pod sends pending pod/s metadata as soon as they appear at the cluster level.
- Each minute, Ocean determines whether there are pending pods and checks headroom to ensure it’s in the desired state.
- Ocean SaaS will:
- Analyze the required resources: for each pending Pod, verify the requested resources and its’ defined constraints. Next, identify the relevant Virtual Node Group (VNG) that can accommodate the pod (in terms of supported node labels, taints/tolerations and instance types). Finally, a request for nodes is triggered against the instance selection process while specifying a list of supported machine types and sizes.
- Instance selection: this process is responsible for maximizing cost efficiency. It prioritizes instance selection in order of:
- Un-utilized Reserved Instances (RIs) or Savings Plans (SPs).
- Spot instances using Spot.io’s unique spot instance selection process which incorporates market scoring, cost and current instance distribution in the cluster.
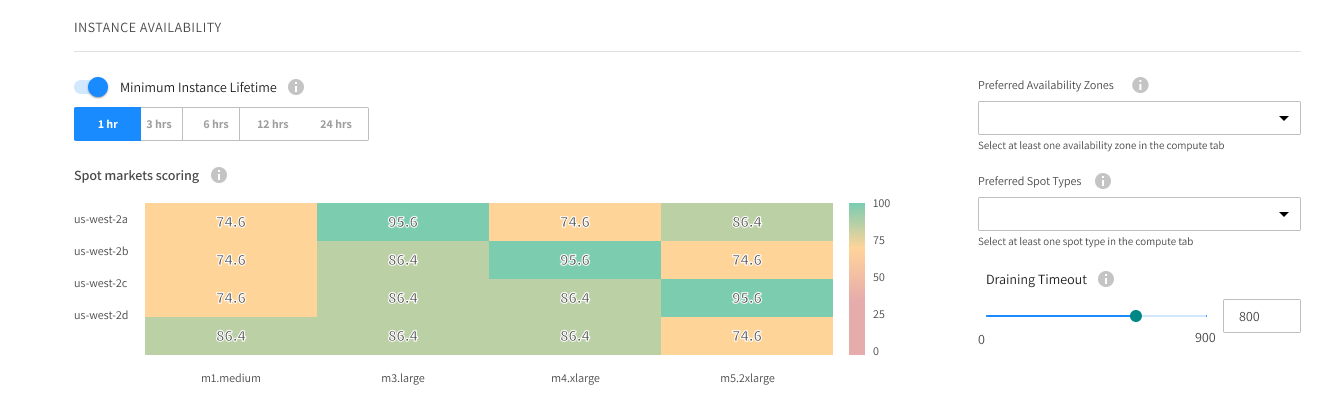 To learn more about the Spot platform unique market scoring system read the attached blog post.
To learn more about the Spot platform unique market scoring system read the attached blog post.
-
-
- In case of lack of spot instance availability, the system would fall back to On Demand (OD) instances automatically and provide a 99.99% SLA to ensure that workloads will continue executing.
- Once spot capacity becomes available again, Ocean will automatically revert back to utilizing spot instances by replacing the OD nodes gracefully. This enables continuous infrastructure optimization allowing the users to receive cost savings without having to manually intervene every time.
-
Instance Termination
Ocean works to ensure a graceful termination of nodes and pods in the cluster. The following scenarios cause the termination of nodes when using Ocean:
Scale-down events
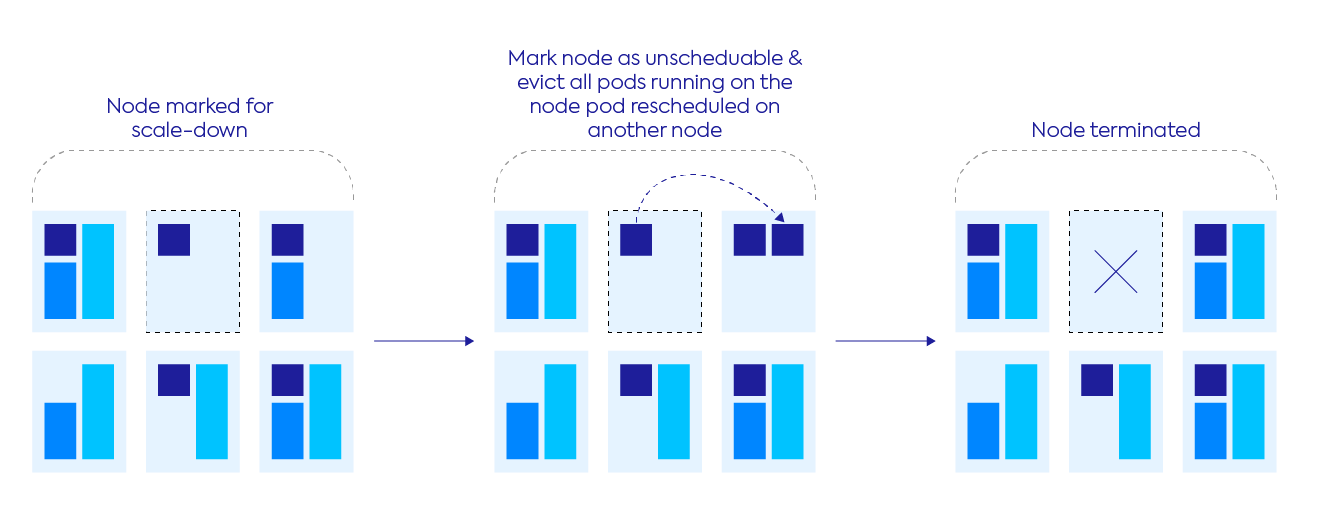
Since a Kubernetes cluster usually has a lot of dynamic workloads, there will typically be a time when the nodes running in the cluster are no longer needed. When this happens, Ocean will identify half-used nodes and will bin-pack more efficiently to achieve higher resource allocation. Every minute, Ocean simulates whether there are any running pods (starting with the least utilized nodes) that can be moved gracefully to other nodes within the cluster. If so, Ocean would drain those nodes (cordon the nodes, drain the pods gracefully) while respecting PDBs (Pod Disruption Budgets), to ensure continuous infrastructure optimization and increased cloud savings.
Scale down behaviour
- When scaling down a node, Ocean utilizes a configurable draining timeout of at least 300 seconds. At this time, Ocean marks the node as unschedulable and evicts all pods (respecting the configured terminationGracePeriodSeconds parameter) running on the node.
- When evicting a pod, a new one will be created on a different node in the cluster.
- After the draining timeout has expired, Ocean will terminate the node and remove any pods that weren’t successfully evicted.
- Ocean draining process takes into consideration PodDisruptionBudgets and will perform the pod eviction while respecting the configured PDBs (when possible)
Some workloads are not as resilient to instance replacements as others, so you may wish to prevent replacement of the nodes, while still getting the benefit of spot instance pricing. A good example of these cases are jobs/batch processes that need to finish their work without termination by the Ocean autoscaler.
Ocean makes it easy to prevent scaling down of nodes running pods configured with one of the following labels:
- spotinst.io/restrict-scale-down:true label – this label is a proprietary Spot label (additional Spot labels), can be configured on a pod level. When configured, it instructs the Ocean autoscaler to prevent scaling down a node that runs any pod with this label specified.
- cluster-autoscaler.kubernetes.io/safe-to-evict: false label – cluster-autoscaler label, works similarly to the restrict-scale-down label. Ocean supports that label to ensure easy migration from the cluster-autoscaler to Ocean.
Container instance replacement
There are several scenarios on which Ocean actively works to replace existing nodes in the cluster:
- Revert to Spot – Ocean launched on-demand nodes due to a lack of spot capacity. Once spot capacity becomes available again, Ocean works to replace those on-demand nodes with spot capacity to maximize savings.
- Utilize RIs/Utilize SPs – Ocean recognizes there are unused reserved instances or savings plans that can be utilized and works to replace existing nodes with on-demand nodes that will utilize those reservations.
- Auto-healing – Ocean detects that node/s become unhealthy and works to replace them.
- Predictive rebalancing – Ocean predicts an interruption is about to occur and gradually replaces the node
- Spot Interruption – The instance is reclaimed by the cloud provider.
- Cluster roll – A user or a scheduled task triggers a cluster roll and all (/subset) of the nodes in the cluster will be gradually replaced.
Ocean makes smart decisions to further optimize the cluster and ensure the availability of required capacity.
Instance replacement behaviour:
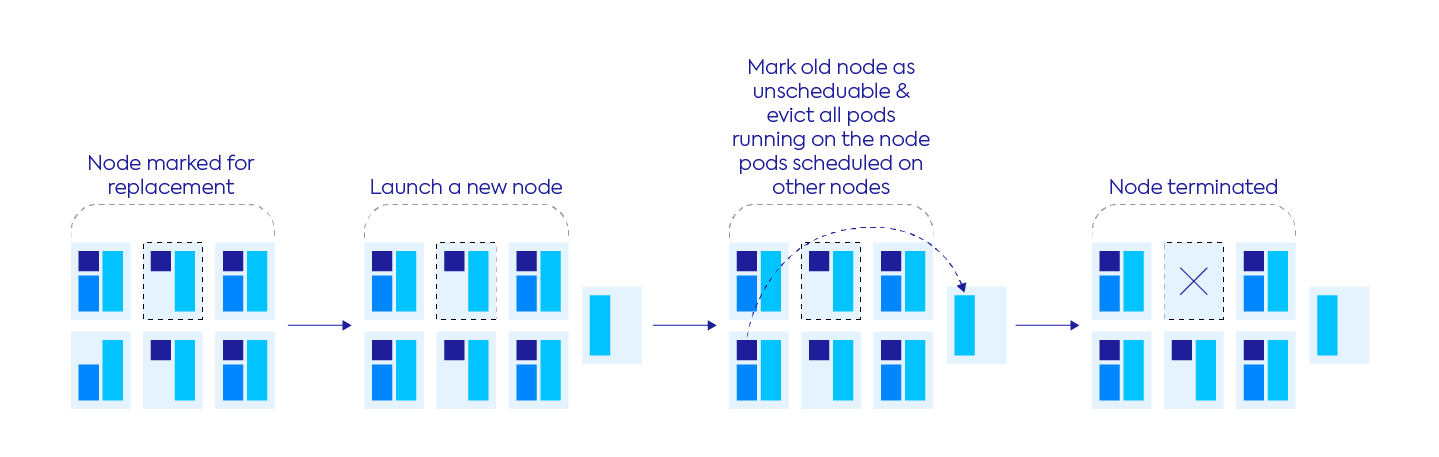
- First, Ocean will launch a new instance to replace the old one.
- Once the machine is registered to the cluster, Ocean will start draining the old instance similar to a scale-down event.
In case of a spot interruption, Ocean will replace the instance and start the draining process for the old instance immediately, without waiting for the new instance to register as healthy in the cluster. In cases like this, having a little bit of spare capacity in the form of headroom is very useful to allow safe draining of pods.
Summary
Spot Ocean provides a continuously optimized container driven autoscaler working to ensure infrastructure availability at the lowest possible cost. To learn more about Ocean check out a this demo, or head over to the https://docs.spot.io/ocean/ to get started.