 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Apache Spark is an open-sourced distributed computing framework, but it doesn’t manage the cluster of machines it runs on. You need a cluster manager (also called a scheduler) for that. The most commonly used one is Apache Hadoop YARN. Support for running Spark on Kubernetes was added with version 2.3, and Spark-on-k8s adoption has been accelerating ever since.
If you’re curious about the core notions of Spark-on-Kubernetes, the differences with Yarn as well as the benefits and drawbacks, read our previous article: The Pros And Cons of Running Spark on Kubernetes. For a deeper dive, you can also watch our session at Spark Summit 2020: Running Apache Spark on Kubernetes: Best Practices and Pitfalls or check out our post on Setting up, Managing & Monitoring Spark on Kubernetes.
In this article, we present benchmarks comparing the performance of deploying Spark on Kubernetes versus Yarn. Our results indicate that Kubernetes has caught up with Yarn – there are no significant performance differences between the two anymore. In particular, we will compare the performance of shuffle between YARN and Kubernetes, and give you critical tips to make shuffle performant when running Spark on Kubernetes.
Benchmark protocol
The TPC-DS benchmark
We used the famous TPC-DS benchmark to compare Yarn and Kubernetes, as this is one of the most standard benchmark for Apache Spark and distributed computing in general. The TPC-DS benchmark consists of two things: data and queries.
- The data is synthetic and can be generated at different scales. It is skewed – meaning that some partitions are much larger than others – so as to represent real-word situations (ex: many more sales in July than in January). For this benchmark, we use a 1TB dataset.
- There are around 100 SQL queries, designed to cover most use cases of the average retail company (the TPC-DS tables are about stores, sales, catalogs, etc). As a result, the queries have different resource requirements: some have high CPU load, while others are IO-intensive.
What do we optimize for?
The performance of a distributed computing framework is multi-dimensional: cost and duration should be taken into account. For example, what is best between a query that lasts 10 hours and costs $10 and a 1-hour $200 query? This depends on the needs of your company.
In this benchmark, we gave a fixed amount of resources to Yarn and Kubernetes. As a result, the cost of a query is directly proportional to its duration. This allows us to compare the two schedulers on a single dimension: duration.
Setup
This benchmark compares Spark running Ocean for Spark (deployed on Google Kubernetes Engine), and Spark running on Dataproc (GCP’s managed Hadoop offering).
Driver: n2-standard-4 instance
- 4 vCPUs
- 16GB RAM
5 executors on n2-highmem-4 instances
- 4 vCPUs
- 32GB RAM
- 375GB local SSD
We ran each query 5 times and reported the median duration.
We used the recently released 3.0 version of Spark in this benchmark. It brings substantial performance improvements over Spark 2.4, we’ll show these in a future blog post.
Spark on Kubernetes has caught up with Yarn
The plot below shows the performance of all TPC-DS queries for Kubernetes and Yarn. Overall, they show very similar performance. For almost all queries, Kubernetes and YARN queries finish in a +/- 10% range of the other. Visually, it looks like YARN has the upper hand by a small margin.
.svg)
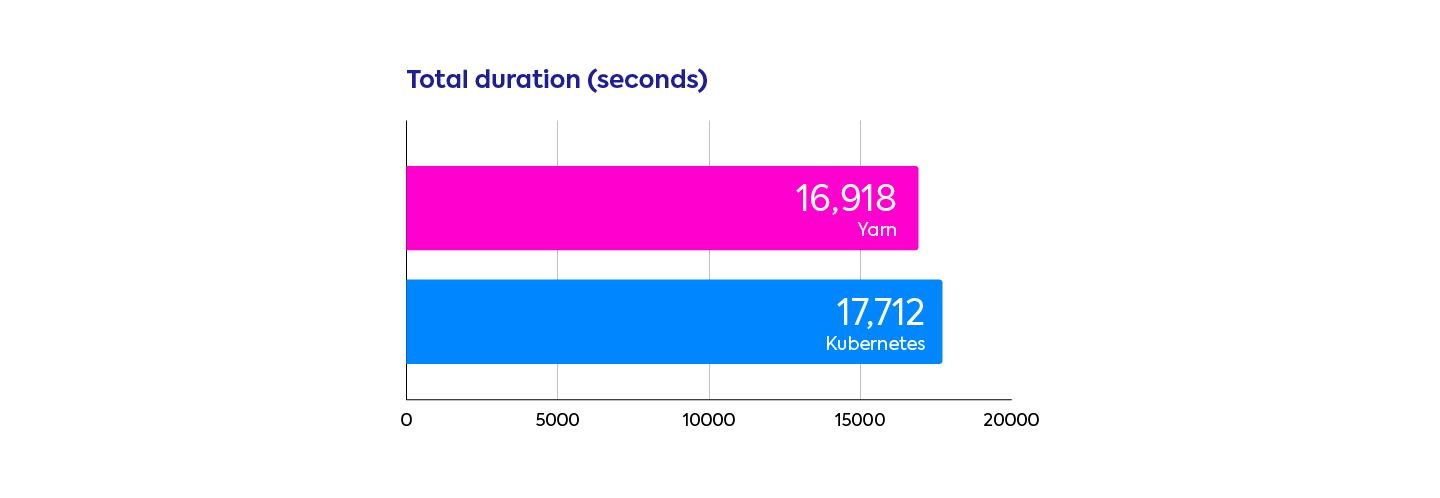
Aggregated results confirm this trend. The total durations to run the benchmark using the two schedulers are very close to each other, with a 4.5% advantage for YARN.
Since we ran each query only 5 times, the 5% difference is not statistically significant. And in general, a 5% difference is small compared to other gains you can make, for example by making smart infrastructure choices (instance types, cluster sizes, disk choices), by optimizing your Spark configurations (number of partitions, memory management, shuffle tuning), or by upgrading from Spark 2.4 to Spark 3.0!
So Kubernetes has caught up with YARN in terms of performance — and this is a big deal for Spark on Kubernetes! This means that if you need to decide between the two schedulers for your next project, you should focus on other criteria than performance (read The Pros and Cons for running Apache Spark on Kubernetes for our take on it).
In the next section, we will zoom in on the performance of shuffle, the dreaded all-to-all data exchange phases that typically take up the largest portion of your Spark jobs. We will see that for shuffle too, Kubernetes has caught up with YARN. More importantly, we’ll give you critical configuration tips to make shuffle performant in Spark on Kubernetes.
How to optimize shuffle with Spark on Kubernetes
Most long queries of the TPC-DS benchmark are shuffle-heavy. The plot below shows the durations of TPC-DS queries on Kubernetes as a function of the volume of shuffled data. When the amount of shuffled data is high (to the right), shuffle becomes the dominant factor in queries duration. In this zone, there is a clear correlation between shuffle and performance.

To reduce shuffle time, tuning the infrastructure is key so that the exchange of data is as fast as possible. Shuffle performance depends on network throughput for machine to machine data exchange, and on disk I/O speed since shuffle blocks are written to the disk (on the map-side) and fetched from there (reduce-side).
To complicate things further, most instance types on cloud providers use remote disks (EBS on AWS and persistent disks on GCP). These disks are not co-located with the instances, so any I/O operations with them will count towards your instance network limit caps, and generally be slower.
Here are simple but critical recommendations for when your Spark app suffers from long shuffle times:
- Use local SSD disks whenever possible. Adding local disks on GCP is a simple toggle feature. On AWS, change the instance type from, say, r5.2xlarge to r5d.2xlarge. The higher cost of these disks is usually largely paid back by the overall performance improvement.
- If local disks are not available, increase the size of your disks, as disk latency and throughput is almost proportional to disk size.
In the plot below, we illustrate the impact of a bad choice of disks. We used standard persistent disks (the standard non-SSD remote storage in GCP) to run the TPC-DS. It shows the increase in duration of the different queries when reducing the disk size from 500GB to 100GB. Duration is 4 to 6 times longer for shuffle-heavy queries!

How to mount a local disk in Spark on Kubernetes
As we’ve shown, local SSDs perform the best, but here’s a little configuration gotcha when running Spark on Kubernetes.
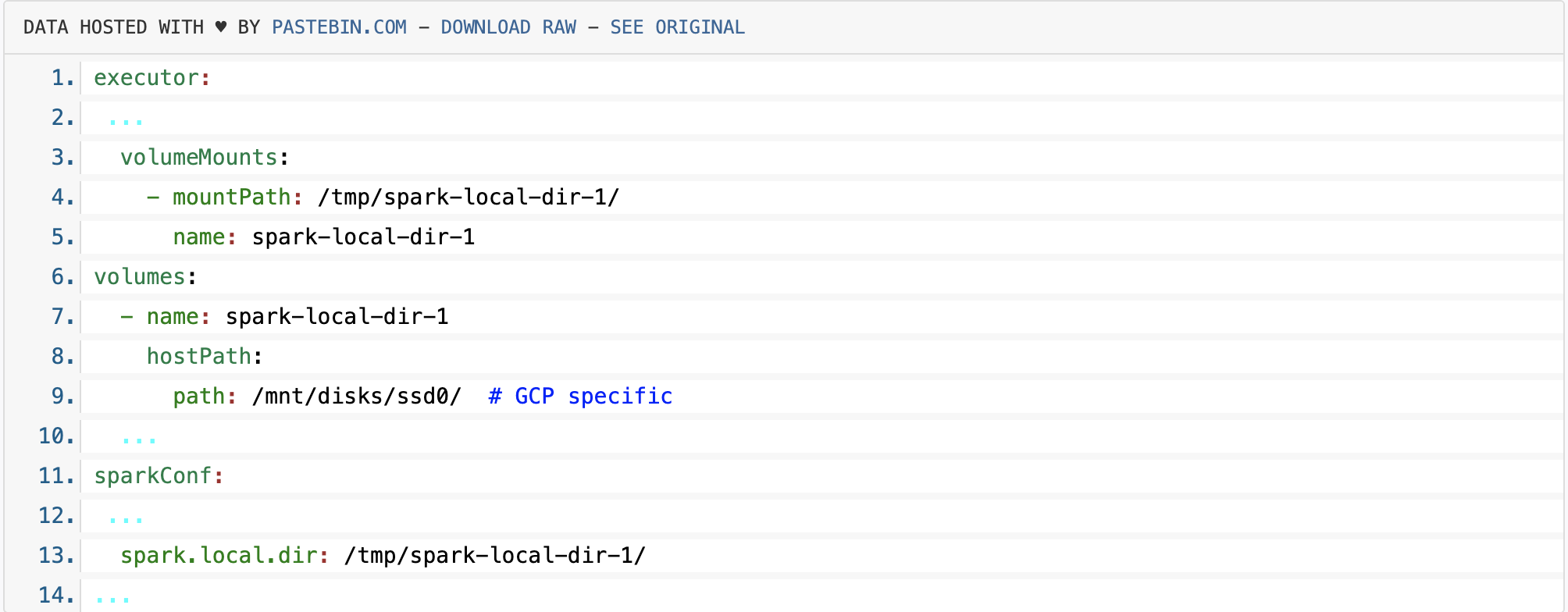
Simply defining and attaching a local disk to your Kubernetes is not enough: they will be mounted, but by default Spark will not use them. On Kubernetes, a hostPath is required to allow Spark to use a mounted disk.
Here’s an example configuration, in the Spark operator YAML manifest style:

Conclusion
⚠️ Disclaimer: Ocean for Apache Spark is a serverless Spark platform, tuning automatically the infrastructure and Spark configurations to make Spark as simple and performant as it should be. Under the hood, it is deployed on a Kubernetes cluster in our customers cloud account.
So we are biased in favor of Spark on Kubernetes — and indeed we are convinced that Spark on Kubernetes is the future of Apache Spark. In this article we have demonstrated with a standard benchmark that the performance of Kubernetes has caught up with that of Apache Hadoop YARN. We have also shared with you what we consider the most important I/O and shuffle optimizations so you can reproduce our results and be successful with Spark on Kubernetes.
How to go further:
- March 2021: Apache Spark 3.1 release now declares Spark-on-Kubernetes as Generally Available and Production Ready!
- April 2021: Use our optimized Docker images to get the best I/O performance with Spark on Kubernetes
- April 2021: Check our open-source monitoring tool Delight to troubleshoot the performance of Spark (on Kubernetes, or on any Spark platform)