 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

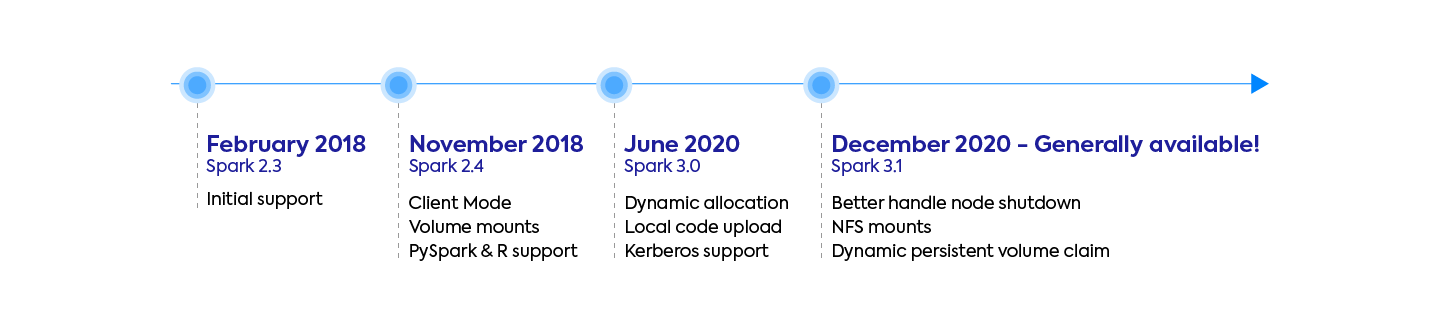
With the Apache Spark 3.1 release in March 2021, the Spark on Kubernetes project is now officially declared as production-ready and Generally Available. This is the achievement of 3 years of booming community contribution and adoption of the project – since initial support for Spark-on-Kubernetes was added in Spark 2.3 (February 2018). In this article, we will go over the main features of Spark 3.1, with a special focus on the improvements to Kubernetes.
Related Resources:
- For an introduction about using Kubernetes as a resource manager for Spark (instead of YARN), look at the Pros & Cons of Running Spark on Kubernetes.
- For a technical guide about being successful with Spark on Kubernetes, check out Setting Up, Managing & Monitoring Spark on Kubernetes.
- For a presentation of our Cloud-Native Spark platform for Data Engineers, head out to Spark on Kubernetes Made Easy: How Spot Improves On The Open-Source Version
The Spark-on-Kubernetes journey: From beta support in 2.3 to becoming the new standard in 3.1
Kubernetes became a new scheduler option for Spark (in addition to YARN, Mesos and Standalone mode) with Spark 2.3 in early 2018, thanks to a handful of large companies who spearheaded the project like RedHat, Palantir, Google, Bloomberg, and Lyft. This initial support was experimental – lacking in features and suffering from stability and performance issues.
Since this date, community support has boomed with many companies large and small attracted by the benefits of Kubernetes:
- Native Containerization. Use Docker to package your dependencies (and Spark itself) — see our optimized Docker images for Spark.
- Efficient resource sharing and faster app startup time.
- A rich open-source ecosystem reducing cloud-provider and vendor lock-in
Major features were contributed to the project – from basic requirements like PySpark & R support, Client Mode and Volume Mounts in 2.4, to powerful optimizations like dynamic allocation (3.0) and a better handling of node shutdown (3.1). During the last 3 years, over 500 patches (improvements and bug fixes) were contributed in total to make spark on Kubernetes much more stable and performant.
As a result, Kubernetes is increasingly considered as the new standard resource manager for new Spark projects in 2021, as we can tell from the popularity of the open-source Spark-on-Kubernetes operator project, or the recent announcements of major vendors adopting it instead of Hadoop YARN.
With Spark 3.1, the Spark-on-Kubernetes project is now considered Generally Available and Production-Ready. Over 70 bug fixes and performance improvements were contributed to the project in this latest release. Let’s now dive into the most impactful feature, the one our customers were eagerly awaiting.
Better Handling for Node Shutdown – Graceful Executor Decommissioning (New Spark 3.1 feature)
This feature (SPARK-20624) was implemented by Holden Karau, and it is currently only available for Kubernetes and Standalone deployments. It is called “Better Handling for Node Shutdown”, though “Graceful Executor Decommissioning” is also a good name for it.
This feature makes Spark a lot more robust and performant when working with spot nodes. It ensures that before the spot interruption occurs, the shuffle and cache data is moved, so that the Spark application can continue with minimal impact. Before this feature, when a spot kill occurs, shuffle files are lost, and therefore need to be recomputed (by re-running potentially very long tasks). This feature does not require to setup an external shuffle service (which requires expensive storage nodes to be running on-demand, and is compatible with Kubernetes). This is easier to describe with a picture.
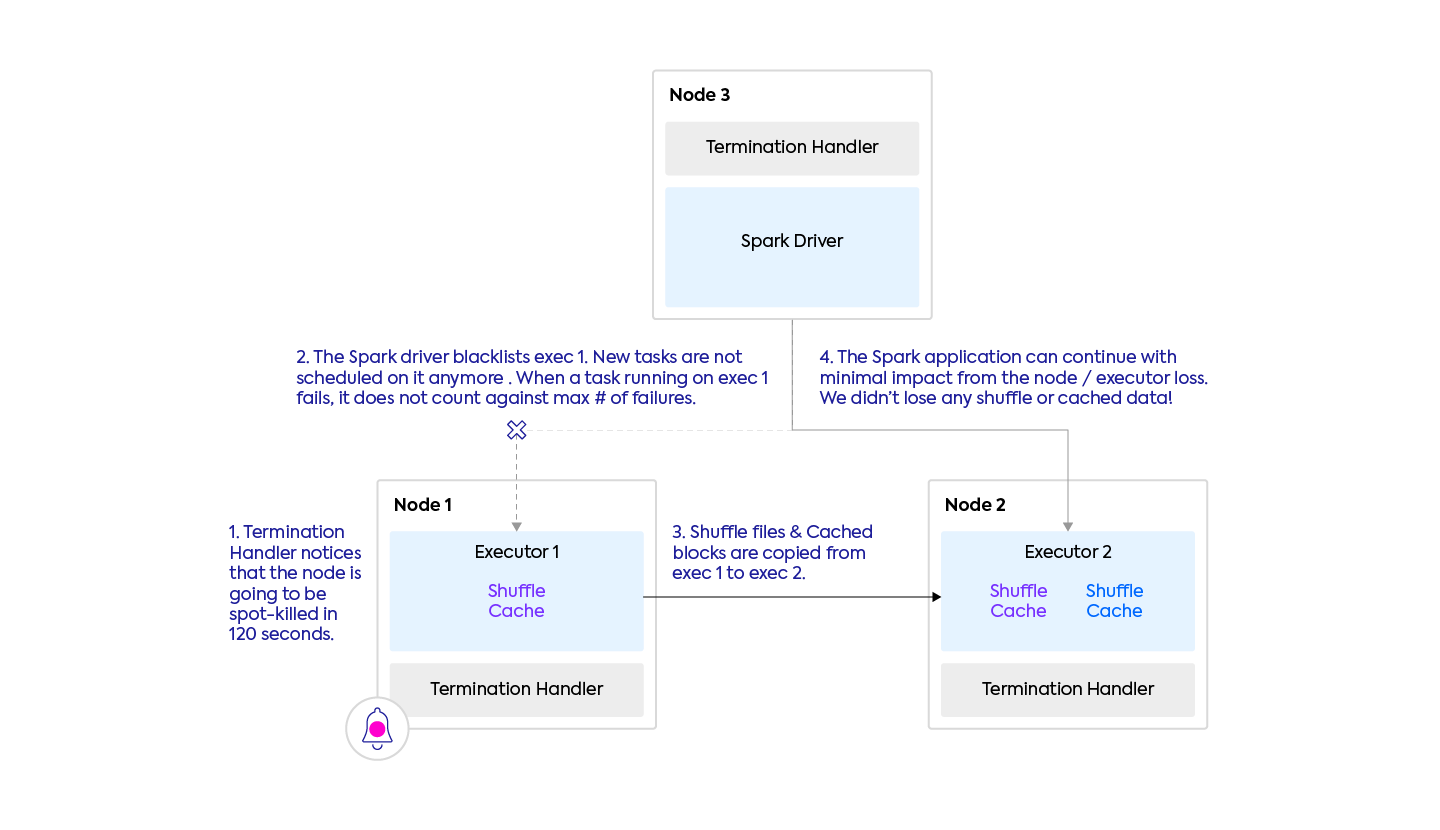
What does it do?
- The executor which is going away is blacklisted – the Spark driver will not schedule new tasks on it. Spark tasks currently running on it are not forcibly interrupted, but if they fail (due to the executor death), the tasks will be retried on another executor (same as today), and their failure will not count against the maximum number of failures (new).
- Shuffle files and cached data from the executor going away are migrated to another executor. If there is no other executor (e.g. we’re removing the only executor that was there), you can configure an object store (like S3) as fallback storage.
- Once this is completed, the executor dies and the Spark app can continue unimpacted!
When does this kick in?
- When you use spot/preemptible nodes, the cloud provider (aws, gcp, azure) now gives you a 60-120 seconds notice ahead of time. Spark can now use this time period to save our precious shuffle files! The same mechanism also applies when a cloud provider instance goes down for other reasons, such as ec2 maintenance events.
- When a Kubernetes node is drained (e.g. for maintenance) or the Spark executor pod is evicted (e.g. preempted by a higher-priority pod).
- When an executor is removed as part of dynamic allocation, during downscale because the executor is idle. The cache and shuffle files will be preserved in this case too.
How can I turn it on?
- Configuration flags. The 4 main Spark configs to turn on are spark.decommission.enabled, spark.storage.decommission.rddBlocks.enabled, spark.storage.decommission.shuffleBlocks.enabled, spark.storage.decommission.enabled.
I recommend referring to the source code to look at the other available configurations. - The ability to be warned by the cloud provider that the node is going away (for example because of a spot kill) requires a specific integration. We recommend looking into the NodeTerminationHandler projects for AWS, GCP, and Azure. If you’re a Spot customer, note that we are taking care of this work for you
New Volumes Option for Spark on Kubernetes
Since Spark 2.4, you could mount 3 types of volumes when using Spark on Kubernetes:
- An emptyDir: An initially empty directory that shares a pod’s lifetime. This is useful for temporary storage. This could be backed by the node’s disk, SSD, or network storage.
- A hostpath: Mounts a directory from the underlying node to your pod.
- A statically pre-created PersistentVolumeClaim. This is a Kubernetes abstraction for various types of persistent storage, such as AWS EBS, Azure Disk, or GCP’s Persistent Disks. The PersistentVolumeClaim must have been created ahead of time by a user, and its lifecycle is not tied to the pod.
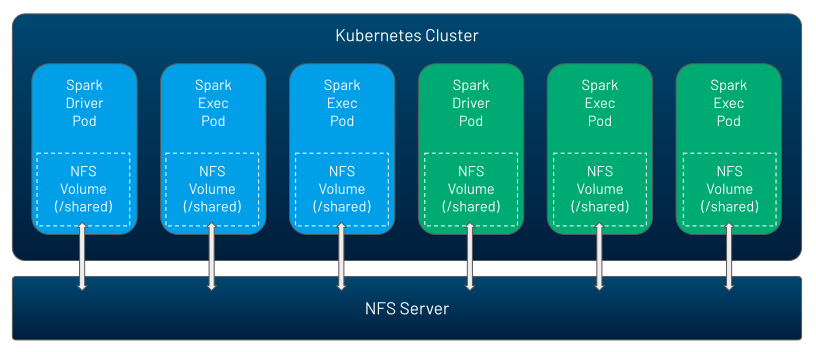
Spark 3.1 enables two new options – NFS, and dynamically created PersistentVolumeClaims.
NFS is a volume which can be shared by many pods at the same time, and which can be pre-populated with data. So it is a way by which you can exchange data, code, configurations across your Spark applications, or across driver and executor within a given Spark application. Kubernetes does not run the NFS server, you could run it yourself, or use a cloud service for it (such as AWS EFS, GCP Filestore, or Azure Files).
Once you created the NFS share, it’s now very easy with Spark 3.1 to mount it in your Spark applications just by using Spark configurations:
spark.kubernetes.driver.volumes.nfs.myshare.mount.path=/shared
spark.kubernetes.driver.volumes.nfs.myshare.mount.readOnly=false
spark.kubernetes.driver.volumes.nfs.myshare.options.server=nfs.example.com
spark.kubernetes.driver.volumes.nfs.myshare.options.path=/storage/shared
The second new option, dynamic PVC, is just a more user-friendly way of using persistent volumes. Previously you had to pre-create PVC, then mount them. If you are using dynamic allocation, you don’t know how many executors might be created during the execution of your app, and so this is very hard to do. You also had to clean up the PersistentVolumeClaims yourself when they become unused, or accept wasting storage resources.
With Spark 3.1, everything is dynamic and automated. As you submit a Spark application (or as you request new executors during dynamic allocation), PersistentVolumeClaims are dynamically created in Kubernetes, which will automatically provision new PersistentVolumes of the Storage Classes you have requested (e.g. AWS EBS, Azure Disk, or GCP’s Persistent Disks). When the pod is deleted, the associated resources are automatically destroyed.
Other Spark 3.1 Features: PySpark UX, Stage-Level Scheduling, Performance Boosts
Besides Spark on Kubernetes going GA, Spark 3.1 brought a lot of notable features. Here we’re going to focus on a few major one.
PySpark developer UX has received two big improvements with Spark 3.1:
- The PySpark documentation has received a complete redesign which makes it a lot more pythonic and user friendly. Check it out!
- Type Hints support now means you should receive code completion and static error detection for free in your IDE.
The Spark History Server which can render the Spark UI after your application has completed will now display statistics about the Structured Streaming queries you ran.
Stage-level scheduling (SPARK-27495) only applies for YARN and Kubernetes deployments when dynamic allocation is enabled. It lets you control in your code the amount and type of executor ressources to request at the granularity of a stage. Concretely, you could configure your application to use executors with CPUs during a first stage of your app (say, to do ETL and prepare data), and then to use GPUs in a second phase of your app (say, to train a ML model).
On the performance side, Spark 3.1 has improved the performance of shuffle hash join, and added new rules around subexpression elimination and in the catalyst optimizer. For PySpark users, the in-memory columnar format Apache Arrow version 2.0.0 is now bundled with Spark (instead of 1.0.2), which should make your apps faster, particularly if you tend to convert data between Spark and Pandas dataframes. The good news is that you will benefit from these performance improvements for free, without any code or configuration changes required.
Conclusion
Spark 3.1 is an exciting release for Apache Spark, celebrating the achievement of many years of community support to the Spark-on-Kubernetes integration, to mark its support as Generally Available and Production-Ready. This isn’t a surprise for us at Spot – as we’ve been helping customers migrate to our cloud-native spark platform (deployed on a managed Kubernetes cluster inside our customers cloud account), consistently achieving great results in terms of developer experience and performance/cost-reductions. If you’d like to start a POC for Ocean for Apache Spark with us, get in touch with our team.
Besides Spark on Kubernetes going GA, the graceful decommissioning feature achieves the vision of fully disaggregating compute ressources from storage, and makes the use of cost-effective spot instances much more stable with Spark. Our initial tests of the feature are very promising – we will soon publish a story of one of our large customers using this feature, so stay tuned!