 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Apache Spark 3.2 was released just last week (see release notes) and it is now available for anyone who wishes to run Spark on Kubernetes (or simply Spark on Docker) as we updated our DockerHub repository of optimized Docker images for Spark.
In this article, we’d like to take you through a tour of the new features of Apache Spark that we’re excited about. We’ll first look at general improvements that benefit the entire Spark community, and then focus on an exciting new development for Spark-on-Kubernetes users.
Main Features – General Improvements
Hadoop 3.3.1 – Performance Improvements
Spark 3.2 now uses Hadoop 3.3.1 by default (instead of Hadoop 3.2.0 previously). You may believe this does not apply to you (particularly if you run Spark on Kubernetes), but actually the Hadoop libraries are used within Spark even if you don’t run on a Hadoop infrastructure. In particular, Spark uses the Hadoop libraries whenever it reads from an object store (like S3), so this is actually important.
The Hadoop 3.3.1 release brought significant performance improvements to the S3A connector (HADOOP-17400). These improvements tune the performance of s3 listing and removes many unnecessary calls to the S3 API, hence reducing the risk of getting throttled, and generally improving the performance of Spark when reading from S3.
The other notable change is the fact that the “Magic S3 committer” is now more easy to use and even recommended as the default, as we can now benefit from the fact that S3 supports strong read-after-write consistency globally since December 2020. The Spark 3.2 and Hadoop 3.3.1 releases fixed a few bugs and improved the performance of this committer significantly.
You can now enable the magic committer by turning a single Spark configuration flag (instead of many), where <bucket> is the S3 bucket where you’re writing your data: “spark.hadoop.fs.s3a.bucket.<bucket>.committer.magic.enabled”: “true”.
If you’re lost on what an S3 committer is, we recommend reading this documentation, which is slightly outdated, but makes a great introduction to the S3 Commit problem. Also note that the Hadoop maintainers are working on an analogous committer optimized for the object stores of Google Cloud and Azure.
Adaptive Query Execution – Performance improvements
The Spark development team continuously looks for ways to improve the efficiency of Spark SQL’s query optimizer. The query optimizer is responsible for selecting the appropriate join method, task execution order and deciding join order strategy based on a variety of statistics derived from the underlying data.
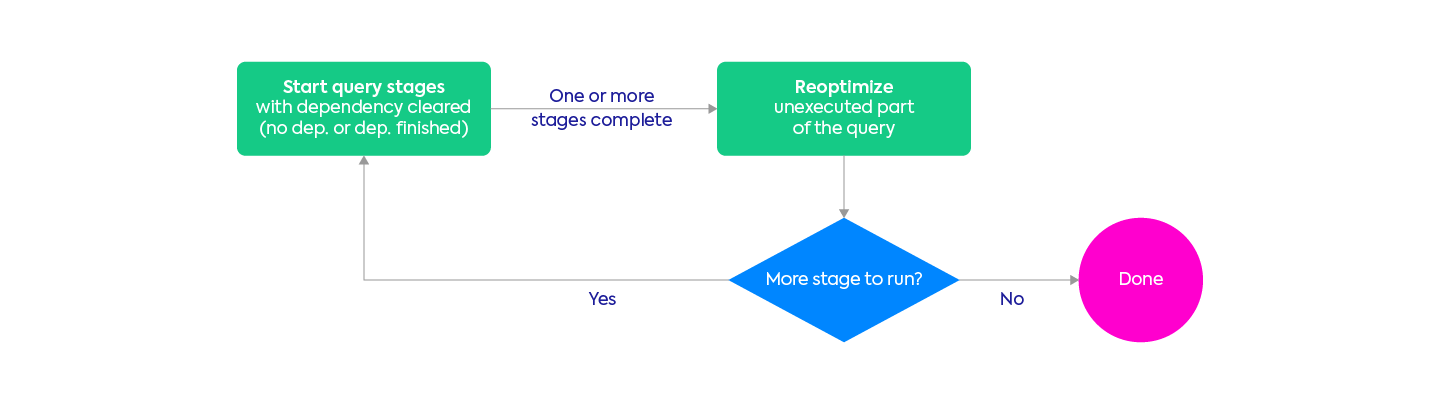
Adaptive Query Execution is one of these optimization technique, first released in Spark 3.0. With Spark 3.2, Adaptive Query Execution is enabled by default (you don’t need configuration flags to enable it anymore), and becomes compatible with other query optimization techniques such as Dynamic Partition Pruning, making it more powerful.
AQE allows the query optimizer to collect data as certain stages are completed, reconstruct the query plan based on the new statistics gathered from query execution, and apply these changes to the query plan in the middle of an application’s execution.
DataSource V2 Aggregate Pushdown – Performance improvements
When Spark reads data from any storage (parquet files on a object store, a data warehouse, HDFS, a SQL database …), it uses a library which implements a specific API. With Spark 2.3 released in 2018, a new API (called DataSource V2) was released, and the main common data connectors (readers and writers) were ported to it. The basic API (V1) only allowed Spark to read/write data in a distributed way. The new API (V2) enables a lot of optimizations at the data source layer such as reading less data by pushing filters “down” at the data source.
With Spark 3.2, you can now benefit from from predicate pushdown on queries that contain an aggregated filter or select an aggregated column. To give a concrete and simple example, asking Spark to compute the number of rows in a parquet file will now be much faster, as Spark can read it from the metadata of the file directly, rather than scanning it (see SPARK-35511).
Supported aggregate functions include count, sum, min, max, and average. With aggregate pushdown, Spark can apply the aggregate predicate to the Data Source, reducing the number of files read and shuffled across the network. If multiple aggregates are included in the query and the aggregates are supported by the DataSource, Spark will push down all the aggregates.
Note that if you select an aggregate *and a dimensional column*, the aggregate will not be pushed down to the data source. Also note that this optimization will see the most effect when using parquet or Delta as a data source.
Koalas – PySpark Improvements for Pandas Users
Koalas, the Spark implementation of the popular Pandas library, has been growing in popularity as the go-to transformation library for PySpark. With Spark 3.2, Koalas will now be bundled with Spark by default, it does not need to be installed as an additional library. The goal is to make Spark more accessible even to people who are used to running pure python code on a single machien, and in fact, it is now much faster to run the same code using PySpark than using pure Pandas, even if you don’t run the distributed capabilities of Spark (thanks to the many optimizations built in Spark SQL).
API Changes
Previously, if you wanted to switch between Pandas, Koalas, or Spark functionality, you needed to apply conversion functions to get the proper DataFrame object that would allow you to utilize specific transformation. With the release of Spark 3.2, Pandas now runs natively on Spark and is included within the PySpark API.

The cell above describes the workflow of utilizing a Pandas function, creating a Pandas DataFrame, and converting into a Spark DataFrame. This operation is particularly inefficient as you will collect the entire `test.csv` to your driver prior to beginning your Spark operations, forgoing one of the key benefits of Spark, distributed processing. In addition, the code itself becomes tedious as we need to switch between libraries in order to utilize the transformations and functionality we desire for our application.

With Spark 3.2, you can import the read_csv function directly from the PySpark API and receive a Spark DataFrame, removing the need to convert back and forth between the two libraries. In addition, the read_csv function is now implemented using Spark as a backend, meaning you will benefit from parallelization as you read and process the csv into memory. This implementation will not only allow developers to produce cleaner PySpark applications, but it will also eliminate confusion around which operations are executed only on the Spark driver and which are distributed across the executors.
Visualizations
The standard Python Pandas implementation is packaged with matplotlib as the default plotting library. With 3.2, PySpark Pandas uses plotly by default. Plotly offers a number of enhancements such as native support for interactively zooming in and out of the graph, as well as recomputing plot views using Spark. If you choose to switch back to matplotlib, you can specify the PySpark plotting library in your Spark config.
RocksDB – Spark Streaming Improvement
The standard Spark streaming configuration supports stateful operations such as streaming aggregations or joins by storing persisted values in memory. For some streaming workloads with high cardinality, storing state in memory may be insufficient, causing the application to spill the data to disk and hinder performance.
Spark now supports RocksDB, a persistent key value store for performant state management. RocksDB offers significant boosts in both lookup performance and latency compared to the legacy, in-memory solution. To run your Spark Application with RocksDB add the following configuration setting:
“spark.sql.streaming.stateStore.providerClass”: “org.apache.spark.sql.execution.streaming.state.RocksDbStateStoreProvider”
Spark-on-Kubernetes improvements
Executor Failure Reason in Spark UI
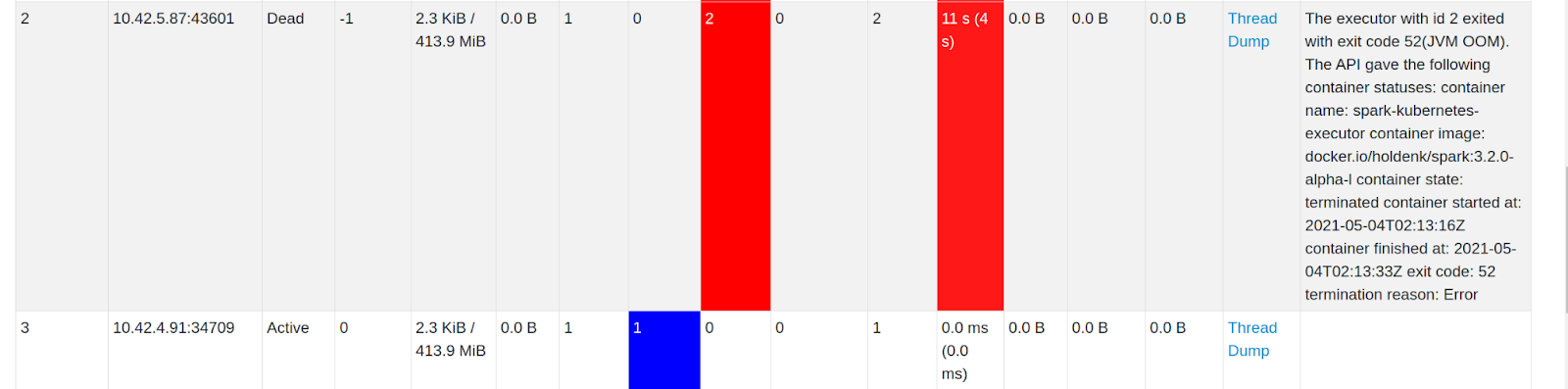
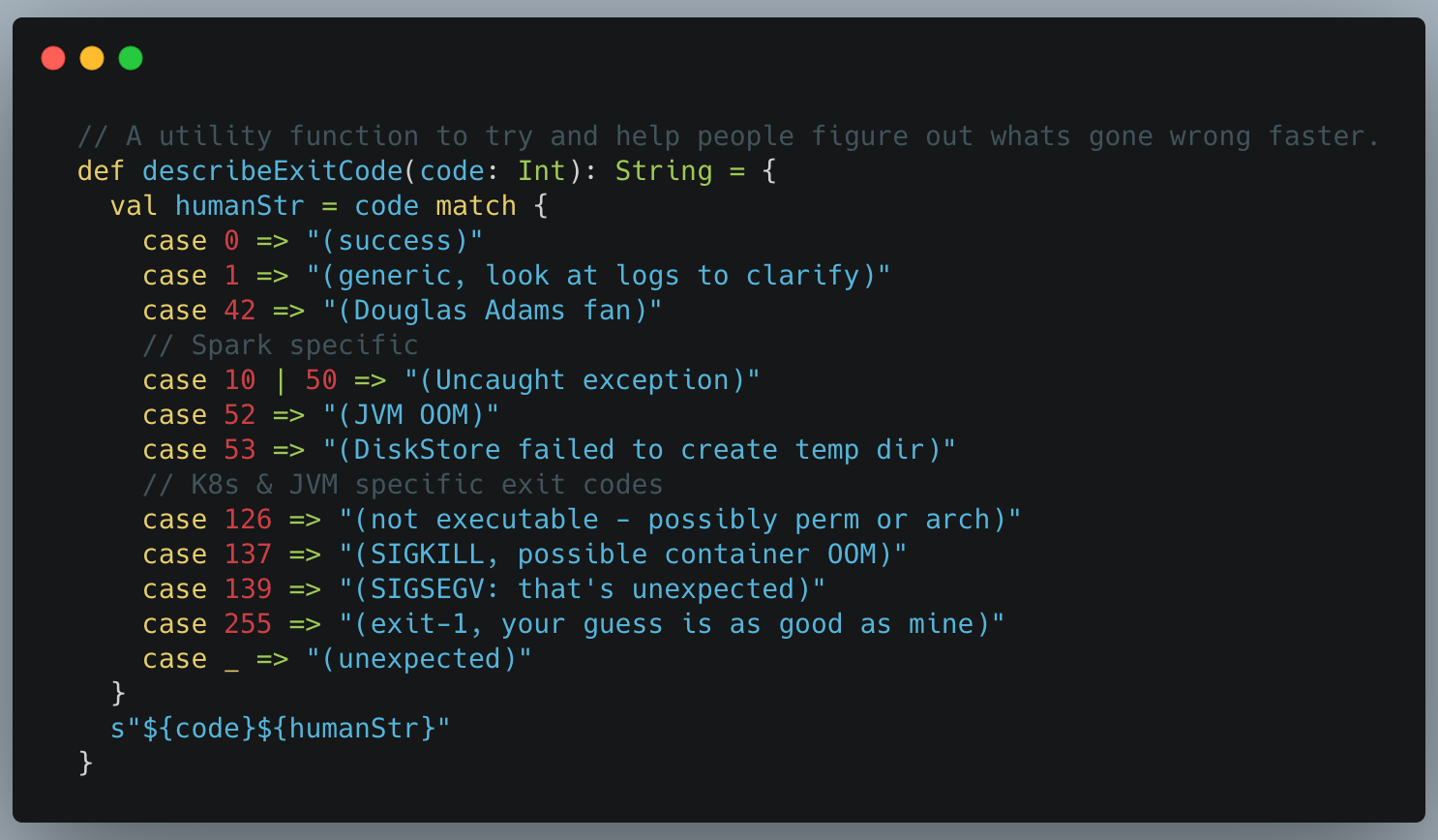
The Spark UI now adds a new column on its Executors page giving you the reason why a Spark executor died. This improvement applies to all Spark users, not just Spark-on-Kubernetes. For Spark-on-Kubernetes users, a bug preventing the propagation of the error code was fixed, and some additional insights is available, such as translating the Docker exit code into something (some) humans understand.
Kubernetes Persistence Volume Claim Reuse on Executor Restart
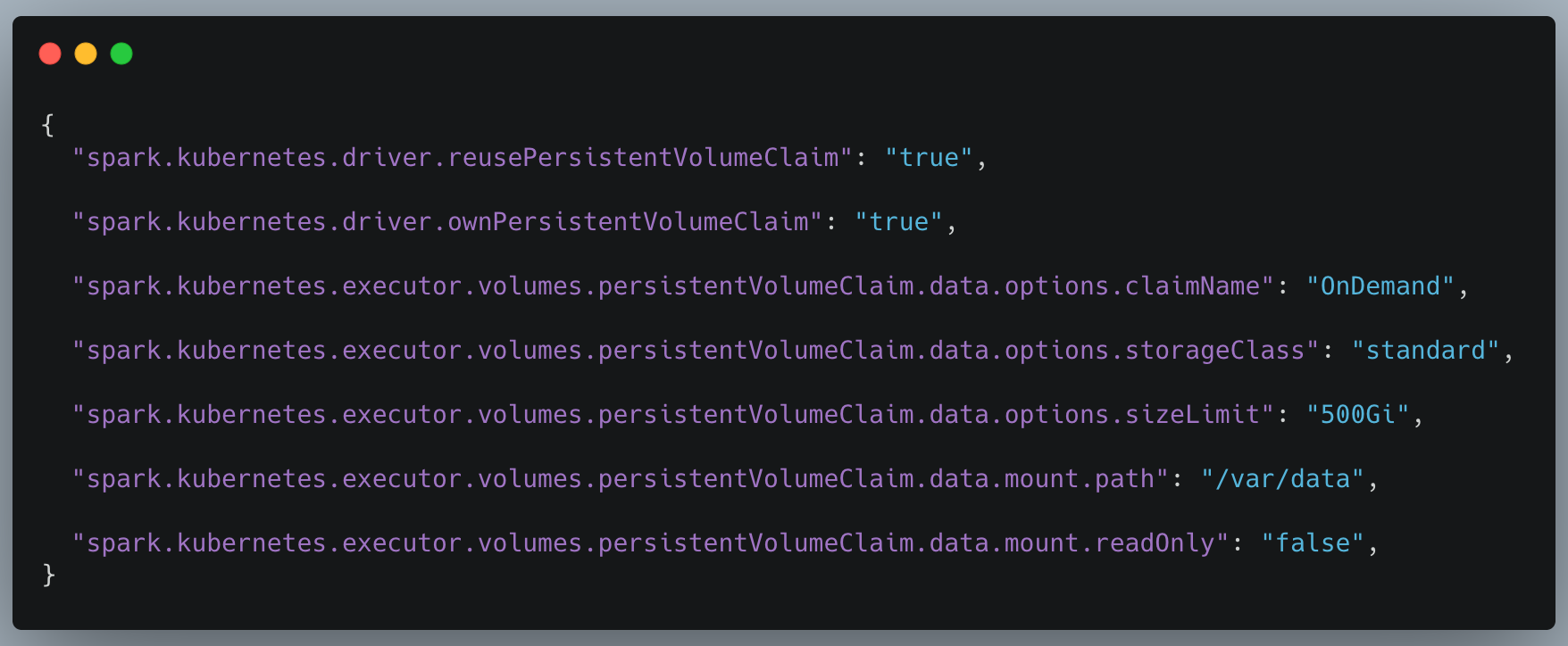
In the 3.1 release, Spark introduced the ability to dynamically generate, mount, and remove Persistent Volume Claims (PVCs)to Spark on Kubernetes workloads, which are basically volumes mounted into your Spark pods, managed by Kubernetes, and backed by a physical cloud volume (such as an EBS on AWS, a persistent disk on GCP, or an Azure disk). See our documentation if you’d like to do this on our platform.
If an executor is lost due to a spot kill or a failure (e.g. JVM running OutOfMemory), the persistent volume was lost at the same time as the executor pod dies, forcing the Spark application to recompute the lost work (shuffle files).
Spark 3.2 adds PVC reuse and shuffle recovery to handle this exact scenario (SPARK-35593). If an executor or node is lost during runtime, Spark will keep the persistent volume claim initially associated with the lost executor, request a new pod from Kubernetes, and attach that existing volume to it so that the precious shuffle files are not lost, and Spark can recover the work already completed instead of recomputing it.

This feature will greatly improve the robustness and efficiency of Spark-on-Kubernetes when dealing with sporadic executor failures, as well as facilitate the use of Spot/Preemptible nodes, which offer 60%+ cost savings compared to traditional on-demand nodes. This is a big win for Spark-on-k8s users!
Conclusion
Apache Spark 3.2 brings significant performance improvement for Spark across all use cases – from Spark SQL users (AQE), to Pandas developers (Koalas), and Streaming users (RocksDB). It’s also another release of added stability and maturity for the Spark-on-Kubernetes project (officially Generally Available since Spark 3.1), as the PVC reuse solves in a robust way the issue of losing a Spark executor during your application runtime.
We look forward to showing these impacts as you upgrade your workloads to Spark 3.2 on our platform. If you’re not a customer but are interested in migrating to Spark-on-Kubernetes, book a demo with us!