 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps
Spot Ocean offers best-in-class container-driven autoscaling that continuously monitors your environment, reacting to and remedying any infrastructure gap between the desired and actual running containers.
The way this typically plays out is that when there are more containers than underlying cloud infrastructure, Ocean immediately starts provisioning additional nodes to the cluster so the container’s infrastructure requirements will be satisfied.
Once the nodes are successfully created, the process of adding them as nodes (or container instances for ECS clusters) takes place and when finally done this new infrastructure is operational. All in all the process can take anywhere from 1 to ~15 minutes.
While that is fine for many applications, in some cases several minutes of throttled service might impact users significantly. Try imagining your video chat application lagging for 3 minutes…
Ocean Headroom
For these cases we provide Ocean Headroom, an intelligent and controlled implementation of infrastructure overprovisioning that allocates just the right amount of spare resources, available for whenever relevant applications need to scale out. With headroom, applications can instantly scale out as there’s absolutely zero seconds of infrastructure prep, as the nodes are already there.
Of course, provisioning spare nodes costs money, and managing the amount and type of compute that is absolutely necessary for immediate scaling is a difficult task, especially in a hyper-dynamic containerized cluster environment .
That’s why Ocean Headroom is designed to abstract these considerations away and provide a balanced amount of extra resources, generated for specific applications in accordance with Ocean’s prediction algorithms, which consider the volume of past scaling events in the cluster.
Automatic headroom
This type of headroom which predicts the next applications to scale out is called automatic headroom. It runs an hourly check and based on the usage trend modifies the cluster’s extra resources. To keep it dynamic yet let the users control its overall size – automatic headroom size is configured as a function of the cluster size.
Manual headroom
Ocean also provides manual headroom. This is configured in Ocean’s VNG (Virtual Node Group) settings, and allows specifying the exact amount of resources that should be running in the VNG as headroom. It is useful for cluster administrators that are very much aware of their applications’ behavior and can tell precisely which workloads/VNGs will benefit from specific amounts of headroom.
Manual and automatic headroom – a complementary relationship
Previously you could only use either automatic headroom or manual headroom, not both. However, Ocean customer feedback showed that these two variations of headroom perfectly complement each other.
Take for example a queuing application that doesn’t scale much but feeds all user-facing services. Due to its scaling nature, Ocean’s automatic headroom prediction algorithm will focus on allocating spare resources for more dynamic applications. However, as the queuing application plays a critical role, using manual headroom to allocate resources for 1-2 more replicas can come handy when the queue fills up and might cause latency for many services.
This new mode of being able to define both automatic and manual headroom concurrently can be opted into by setting the “enableAutomaticAndManualHeadroom” cluster level flag as true in the Ocean API. For AWS API see here and GCP here. In Azure this is enabled by default
Ocean console users will be shown a notification in the UI allowing them to opt in.
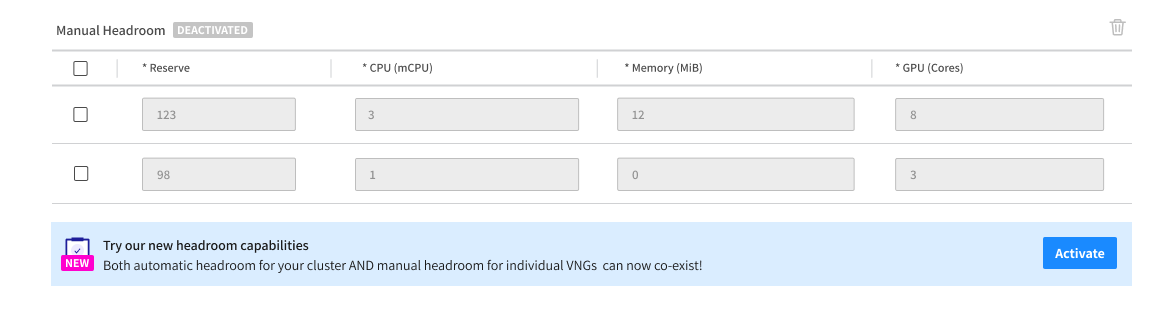
This notification will appear next to the headroom type (automatic/manual per VNG) . Click Activate to opt in to the new mode so you can enable optimal overprovisioning for ALL your mission-critical services. With this set, your infrastructure can scale instantaneously.
To learn about Ocean’s features for infrastructure automation, visit our Ocean product page or create a Spot account to get started.