 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Even though January 1 has passed, it’s not too late to commit to a New Year’s resolution. “Right–sizing” might sound like the latest fad diet that promises easy weight loss results. But you didn’t come to this particular blog because (like me) your pandemic diet sometimes consisted of nothing more than take-out and never-ending snacks. You’re reading this because your compute infrastructure might be bloated, and you’re retaining—and paying for—resources you don’t need. Right-sizing your infrastructure can save your company a ton of money which is a resolution we can all get behind.
We’ve written a new white paper, Compute infrastructure right-sizing in a cloud-native world, based on the experience and insight of our more than 1,500 customers to break down the challenges, best practices, and tools for right-sizing. We also explore how right-sizing is a natural fit for containerized workloads and best-practices for safely implementing downsizing activities.
Getting started
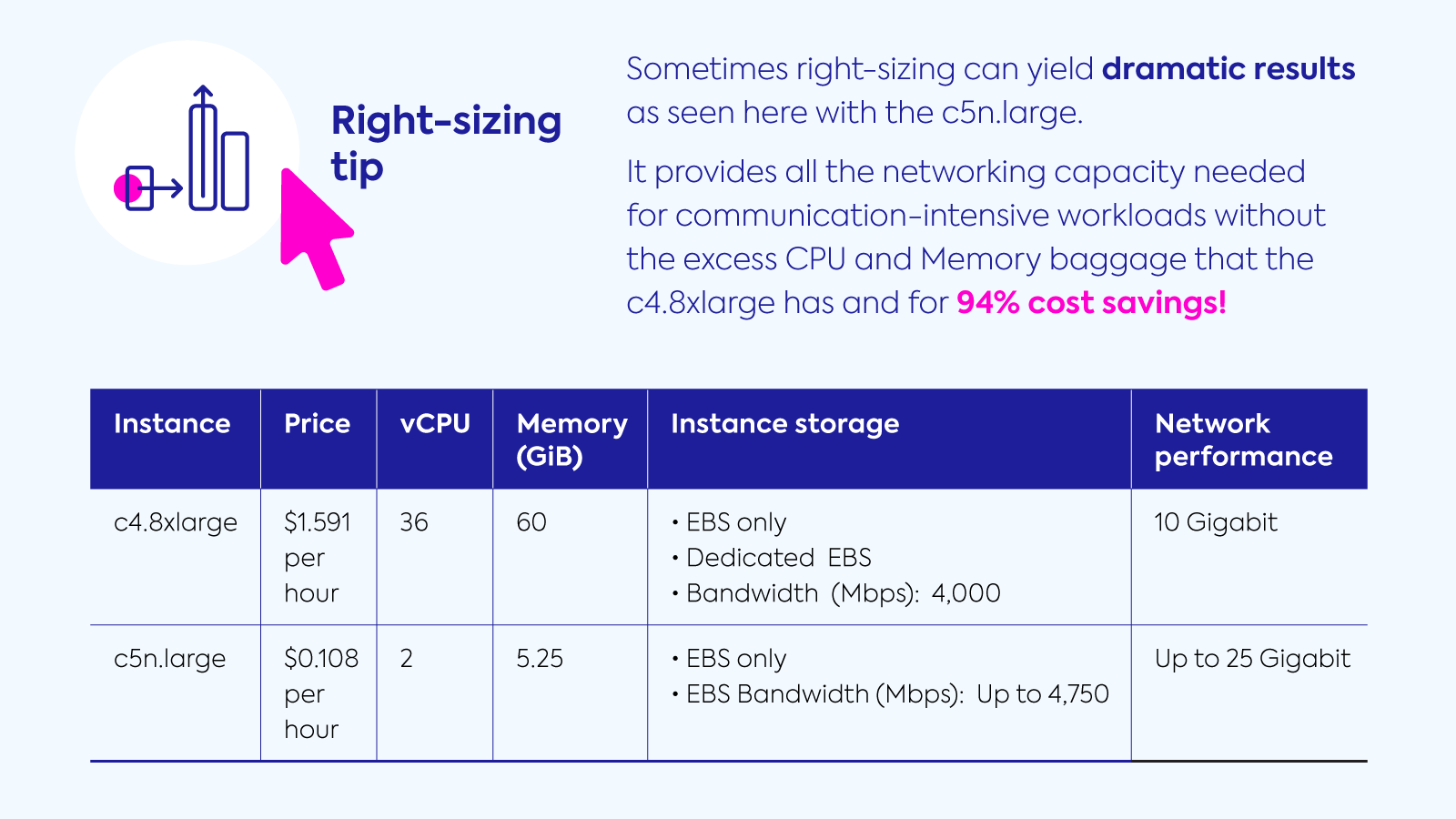
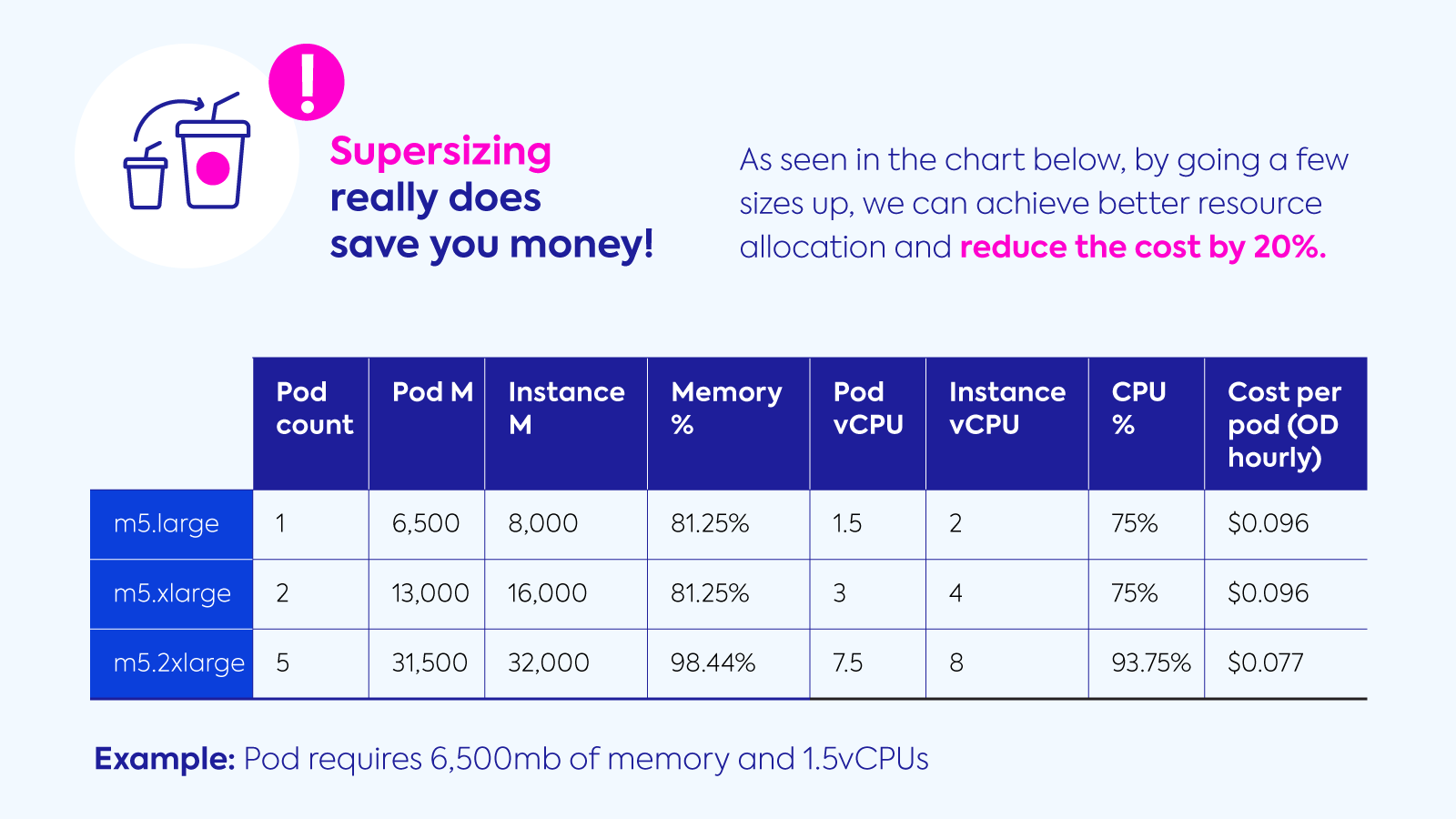
The reality is that unless you have prophetic powers, knowing in advance exactly how much CPU, memory, disk and network your applications are going to require is one of the trickiest areas during deployment. We see engineers often rounding up and greatly overprovisioning, taking a t-shirt sizing method for selecting instances – small, medium, large, and extra–large. Choosing the right size can potentially save you around 25% but possibly much more.
Fortunately, in the cloud you are not stuck with physical servers as you would have been had you installed them in your data center and can always right-size your compute infrastructure even mid-flight. The challenge is in knowing when it’s appropriate to right-size and having the right metrics to make that decision.
Step on the scale
If you’re starting a new diet, you would first step on a scale and start tracking your calories and activity. This data is essential to understanding your current situation (thanks, snacks), setting goals, and figuring out how to reach them. The same goes for right-sizing; getting visibility and monitoring in place is essential to ascertain whether your workloads can be moved to machines with less resources required.
At a minimum, visibility into CPU and memory utilization of workloads is required, but disk and network consumption also play an important role in determining whether to increase or decrease resource requirements. In our white paper, we share a variety of monitoring options for both legacy/non-containerized applications and containerized workloads. And we detail best practices for choosing monitoring tools that are right for your organization. Think of it like choosing a fitness tracker – cost, ease-of-use, and capabilities are all considerations.
Go for the (low-hanging) fruit
From our experience, quick fixes with over-provisioned lower–priority systems are a great place to start right-sizing. Even though you might see more cost-savings by optimizing your most expensive applications and environments, getting an easy win under your belt can be proof to your organization that right-sizing deserves time and resources.
Keep an eye on your progress
After observing workload resources, anything less than 20% utilization is typically an excellent candidate for downsizing. Even if utilization is higher, but still nowhere near max capacity, you might still consider downsizing. Along the way, we recommend testing workload performance on right-sized instances to make sure there is no performance degradation. After that, ongoing monitoring of your application’s behavior in your production environment with APM tools is key to ensuring right-sizing does not impact performance.
Automate right-sizing and consider a turnkey solution for container workloads
Even with properly defined resource requirements there is still a potential risk of misconfiguration unless you have implemented automated right-sizing. In other words, someone might offer you a slice of mouth-watering birthday cake despite your best efforts to count calories. There are a variety of automation options available to ensure this doesn’t happen – from fully DIY to out-of-the-box – that we discuss. But from our perspective, cost-savings is just as important as freeing teams from manual, laborious, and time-consuming processes.
When it comes to right-sizing automation, our focus is on containerized workloads because they are a natural fit. Spot Ocean is a completely turn-key solution that provides resource utilization analysis and sizing recommendations for all container workloads which can be implemented as part of the CI process or when a deployment is being created on the cluster. Based on the right-sized requirements, Ocean continuously manages the underlying nodes ensuring that you always have the optimal compute power needed by your cluster. With robust, container-driven infrastructure auto-scaling and intelligent right-sizing for container resource requirements, engineers can code more, while operations can literally “set and forget” the underlying spot instance cluster.
Stick to your resolution
While it might be hard to stick to a diet, once you have a taste of the fruits of right-sizing, you’ll never go back. When you have the relevant data, we highly recommend investing in resources for right-sizing efforts, particularly for any workloads that will run long-term. Then, sit back, and enjoy the satisfaction of the cost-savings you will have achieved. (And go ahead, order some more take-out!)
