 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Now more than ever our customers are asking us for ways to reduce their public cloud spend. Customers are also asking us whether spot instances are still providing the high level of discount that they always have. The reality is that spot instance pricing is still very much based on supply and demand. Excess capacity from the cloud provider means availability can change within minutes. Therefore, you might see pricing for a particular market increase for a few months and then dip shortly thereafter. Year over year we see these trends happen around certain holidays or events going on around the world. But despite these fluctuations, we always see a quick return to a stabilized high level of savings.
Our team at Spot is always following these trends and pricing with the help of a dedicated research team that is tasked with continuously improving our algorithms. This team helps develop some of our core features, such as Predictive Rebalancing, a feature that utilizes a machine learning model to identify and predict spot capacity usage and interruptions in the public cloud. This allows us to launch into the best spot markets, instance types and availability zones that offer the best price and are least likely to be interrupted.
Over time we have seen macroeconomic factors contribute towards increased or decreased spot pricing and availability. For example, March 2020 was not something any cloud provider could have predicted. During that time, we saw a dramatic shift in companies increasing their total public compute consumption and thus a higher number of spot interruptions along with increased spot pricing. I share this example because it’s important for users of spot instances to realize that they may see these trends from time to time, but nobody is ever going to offer you up to a 90% discount on anything without having a caveat or challenge to overcome.
I’ve always told our customers that Spot can provide historical pricing around spot markets, but we don’t have a crystal ball to know if the cloud provider is opening up a new data center tomorrow filled with their desired instance type and size, resulting in increased spot savings. For that reason, we never suggest our customers rely on historical data to drive their configurations.
Let’s dive a bit deeper into this and share some actual examples of how Spot can make your public cloud infrastructure resilient to such macroeconomic changes. I will separate this into two sections based on whether your applications are containerized or monolithic applications that might be running on a traditional auto-scaling group.
Containers
Spot Ocean is our flagship product for providing a serverless container experience in the cloud. All you have to do is deploy our controller into your existing K8s cluster and Ocean will automatically launch the best instance type, size, and family based on the pod requirements and continually optimize the infrastructure to ensure you are not wasting compute. All of this is done while also using our algorithms to drive every scaling decision and deliver cost savings and stability.
As a best practice, we encourage our customers to add as many instance types into the “allow list” as possible. This allows our autoscaler to make the best possible scaling decisions for you as workload requirements may change, and so will the fluctuating spot markets.
As I mentioned, spot market availability can change within minutes. Using historical data to drive your “allow list” may put you into a scenario where you see fewer cost savings from spot or capacity as a whole. With Ocean, you will almost always see a heterogeneous mix of instance types and families launched within your cluster. This is not only because of your pod’s requirements but also attributed to wherever we can find the best spot markets to launch into.
Kubernetes has made this easy as CPU and memory requests are treated equally. Therefore, Kubernetes does not care if you have the latest and greatest instance type running in your cluster or a much older type. If a pod is pending in the cluster, the scheduler will schedule it on any node that meets the requirements.
AWS customers have likely heard about the benefits that AWS Graviton instances can provide customers, such as improved performance and cheaper on-demand costs. The Graviton instances require a different AMI architecture than their predecessors using x86-based AMI’s. That is why AWS customers have not been able to use both x86 and Graviton instances in the same node groups or autoscaling groups.
We are excited to announce that Spot Ocean now supports the ability to run multi-architecture Virtual Node Groups. This allows our autoscaler to deliver the best infrastructure based on the market conditions. Check out our blog post with all the details on this feature release here.
Graviton instances have been consistently growing within the AWS ecosystem and presently have at least 13 different families. If you add in all of those instance families and sizes into your allow list, that gives Ocean more than 100 additional spot markets to constantly assess and launch into while simultaneously factoring in the hundreds of x86 markets. This becomes one of the best ways to make sure our autoscaler can track down the highest spot discounts as possible.
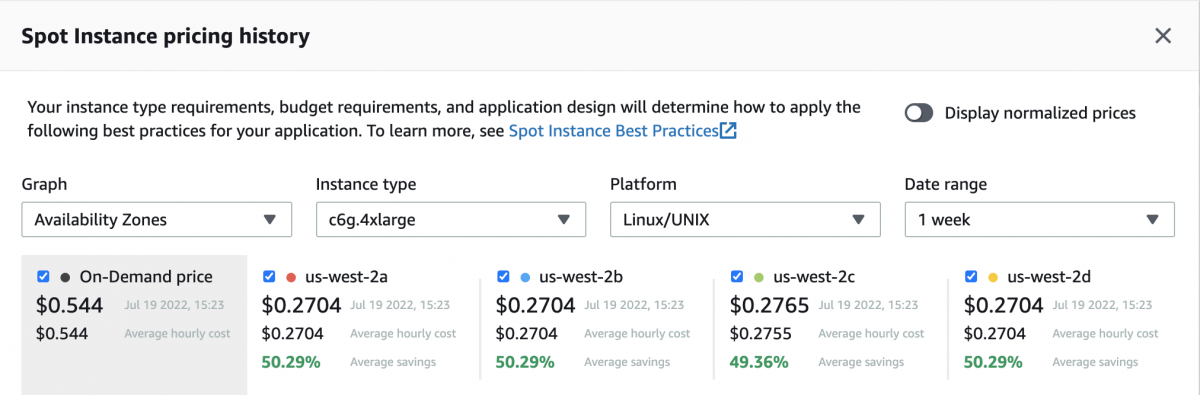
Let’s take a look at some data with a live example in the US-West-2 region comparing the latest Graviton instances to that of a x86 instance with the same amount of vCPU & Memory:
Graviton – C6G.4Xlarge
C5.4xlarge
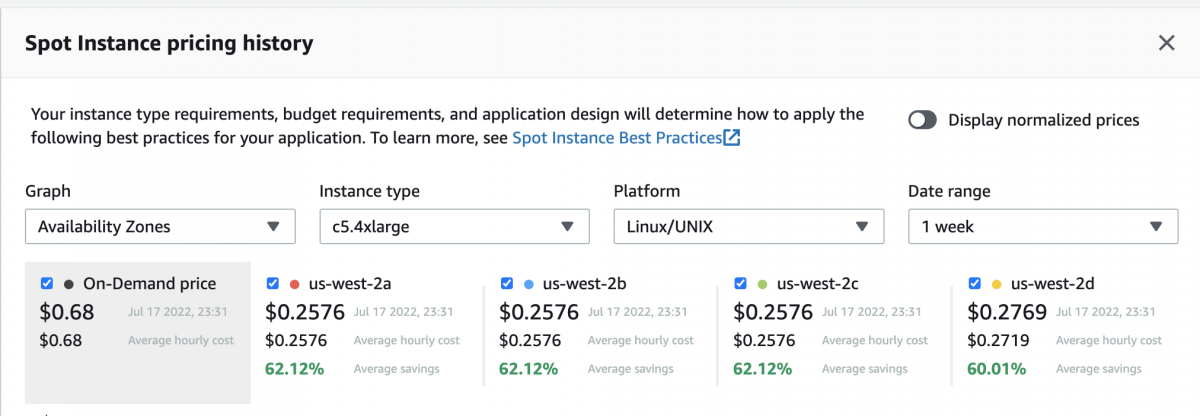
From the example above we can conclude that although the Graviton instance has a cheaper on-demand price than the non-Graviton c5.4xlarge, the spot price is cheaper for the c5.4xlarge in all but one availability zone.
Monolithic applications
Let’s not leave out our applications that are not containerized. Spot’s Elastigroup provides many of these same benefits as Ocean, but specifically for monolithic applications. Elastigroup provides the same capability of configuring both x86 and Graviton instances into the same allow list to provide a more diversified allow list of instances, cost savings and availability.
However, customers that leverage load balancers are likely stuck using a single instance size. This is because a homogenous configuration of instances (all the same type and size) ensures that the load balancer distributes traffic equally while also achieving steady utilization and performance, but the downside is a limited allow list of instance families that can be used. If you were to use different instance types and sizes, it would deliver more reliable spot infrastructure, but the traffic distribution would be skewed and lead to further inefficiencies.
With Elastigroup’s Intelligent Traffic Flow (ITF), we help remove this barrier for our customers. ITF uses the application load balancers’ weighting capability to distribute traffic based on instance capacity.
How does ITF work?
ITF uses the application load balancers’ weighting capability to distribute incoming traffic based on instance capacity. In this first release, ITF will group instances according to their vCPU count and will automatically calculate the weight of each group relative to the overall number of vCPU within the entire Elastigroup. Each instance in the cluster will end up with the same, optimal level of vCPU utilization. In the next release, ITF will also be able to calculate and balance traffic based on other metrics, such as memory and network consumption.
Together with core capabilities for compute provisioning, cost optimization, and predictive scaling, ITF rounds out Elastigroup’s functionality to deliver the most advanced, automated cloud infrastructure management platform available.
For every scaling event that takes place in the Elastigroup platform, ITF seamlessly recalculates the target group’s weight and automatically rebalances traffic without any manual intervention. Users can leverage as many spot instance markets as they wish to achieve higher availability while resource utilization is efficient and optimized across instances. ITF levels the playing field for customers running non-containerized workloads by allowing users to configure a true heterogeneous blend of instances within your allow list. All of this is done without any manual DevOps intervention and allows Elastigroup to chase after the most cost-effective infrastructure based on real-time market conditions.
The more instance types, the more cost-efficient infrastructure
When running workloads on spot instances, availability, reliability, and performance are always top of mind. Spot instances can be stopped or terminated with little warning, so using them means managing these challenges. We encourage all of our Ocean and Elastigroup customers to configure as many instance types and availability zones as possible within their groups. This will ensure Ocean and Elastigroup will be ready to adapt and scale the most cost-effective and available infrastructure depending on your configured strategy without falling victim to point-in-time spot pricing increases.
In the event spot instance availability is not favorable for all the configured spot markets, Ocean and Elastigroup can fallback to on-demand instances by launching the cheapest on-demand instance configured within the group. These new capabilities will make your infrastructure more resilient to macroeconomic changes.
Stay tuned in the coming weeks for an upcoming feature announcement for Elastigroup: Dynamic AZ selection. In cases where customers require only using a single-AZ architecture, Elastigroup will automatically select the best availability zone during creation/scale-up events to deliver you the most cost-effective and available spot markets.
Getting started
Multiple AMI’s in Ocean + Elastigroup are available now and can be configured via the Spot API. The implementation of this new feature will be available in the Spot UI soon. Additional information on how this can be configured is available in the Spot API documentation and we will include an example from our API documentation below:
{
"group": {
"compute": {
"launchSpecification": {
"imageId": null,
"images": [
{"id" : "ami-12345678901234567"},
{"id" : "ami-23456789012345678"}
]
}
}
}
}
Sign up for a demo
Let us know you’re interested in reducing your public cloud compute.