 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Apache Spark is an open-source distributed computing framework. In a few lines of code (in Scala, Python, SQL, or R), data scientists or engineers define applications that can process large amounts of data, Spark taking care of parallelizing the work across a cluster of machines.
Spark itself doesn’t manage these machines. It needs a cluster manager (also sometimes called scheduler). The main cluster-managers are:
- Standalone: Simple cluster-manager, limited in features, incorporated with Spark.
- Apache Mesos: An open source cluster-manager once popular for big data workloads (not just Spark) but in decline over the last few years.
- Hadoop YARN: The JVM-based cluster-manager of hadoop released in 2012 and most commonly used to date, both for on-premise (e.g. Cloudera, MapR) and cloud (e.g. EMR, Dataproc, HDInsight) deployments.
- Kubernetes: Spark runs natively on Kubernetes since version Spark 2.3 (2018). This deployment mode is gaining traction quickly as well as enterprise backing (Google, Palantir, Red Hat, Bloomberg, Lyft). As of June 2020 its support is still marked as experimental though.
As the new kid on the block, there’s a lot of hype around Kubernetes. In this article, we’ll explain the core concepts of Spark-on-k8s and evaluate the benefits and drawbacks of this new deployment mode.
Core Concepts
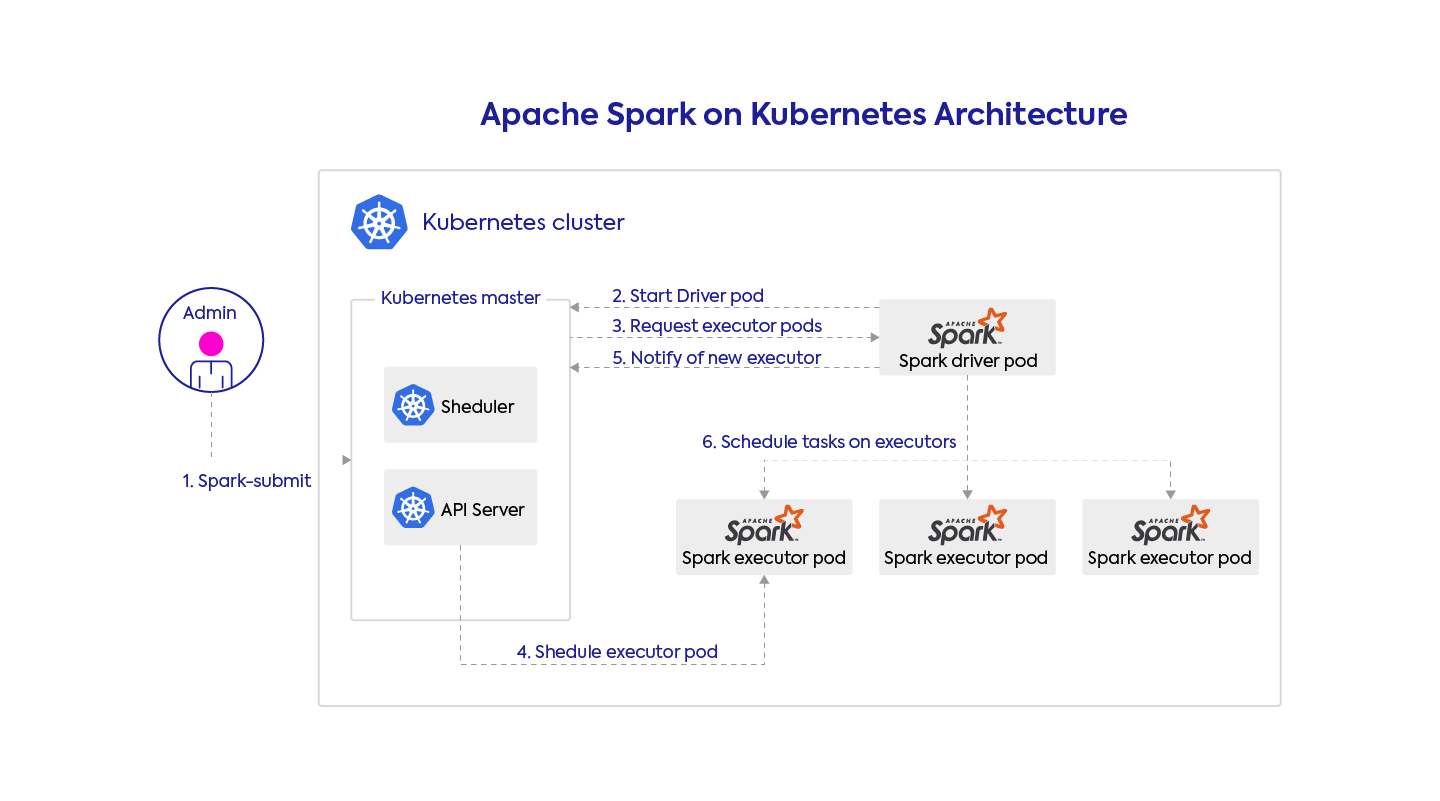
You can submit Spark apps using spark-submit or using the spark-operator — the latter is our preference, but we’ll talk about it in a future tutorial post. This request contains your full application configuration including the code and dependencies to run (packaged as a docker image or specified via URIs), the infrastructure parameters, (e.g. the memory, CPU, and storage volume specs to allocate to each Spark executor), and the Spark configuration.
Kubernetes takes this request and starts the Spark driver in a Kubernetes pod (a k8s abstraction, just a docker container in this case). The Spark driver can then directly talk back to the Kubernetes master to request executor pods, scaling them up and down at runtime according to the load if dynamic allocation is enabled. Kubernetes takes care of the bin-packing of the pods onto Kubernetes nodes (the physical VMs), and will dynamically scale the various node pools to meet the requirements.
To go a little deeper, the Kubernetes support of Spark relies mostly on the KubernetesClusterSchedulerBackend which lives in the Spark driver.
This class keeps track of the current number of registered executors, and the desired total number of executors (from a fixed-size configuration or from dynamic allocation). At periodic intervals (configured by spark.kubernetes.allocation.batch.delay), it will request the creation or deletion of executor pods, and wait for that request to complete before making other requests. Hence this class implements the “desired state principle” which is dear to Kubernetes fans, favoring declarative over imperative statements.
The Pros – Benefits of Spark on Kubernetes
1. Containerization
This is the main motivation for using Kubernetes itself. The benefits of containerization in traditional software engineering apply to big data and Spark too. Containers make your applications more portable, they simplify the packaging of dependencies, they enable repeatable and reliable build workflows. They reduce the overall devops load and allow you to iterate on your code faster.
The top 3 benefits of using Docker containers for Spark:
1) Build your dependencies once, run everywhere (locally or at scale)
2) Make Spark more reliable and cost-efficient.
3) Speed up your iteration cycle by 10X (at Data Mechanics, our users regularly report bringing down their Spark dev workflow from 5 minutes or more to less than 30 seconds)
Our favorite benefit is definitely dependency management, since it’s notoriously painful with PySpark. You can choose to build a new docker image for each app, or to use a smaller set of docker images that package most of your needed libraries, and dynamically add your application-specific code on top. Say goodbye to long and flaky init scripts compiling C-libraries on each application launch!
Update (April 2021): We’ve made our optimized Docker images publicly available for anyone to use. They contain connectors to most commonly used data sources – we hope they’ll just work for you out of the box! Check out our blog post and our Dockerhub page for more details?
Update (October 2021): See our step-by-step tutorial on how to build an image and get started with it with our boilercode template!
2. Efficient resource sharing leading to big cost savings
On other cluster-managers (YARN, Standalone, Mesos) if you want to reuse the same cluster for concurrent Spark apps (for cost reasons), you’ll have to compromise on isolation:
- Dependency isolation. Your apps will have a global Spark and python version, shares libraries and environments.
- Performance isolation. If someone else kicks off a big job, my job is likely to run slower.
As a consequence, many platforms (Databricks, EMR, Dataproc, …) recommend running transient clusters for production jobs. Start a cluster, run the job, terminate the cluster. The problem with this approach is that you pay for the setup/tear down costs (often about 10 minutes, because it takes a lot of time to setup YARN properly), and you don’t get any resource sharing. It’s very easy to make mistakes and waste a lot of compute resources with this approach.
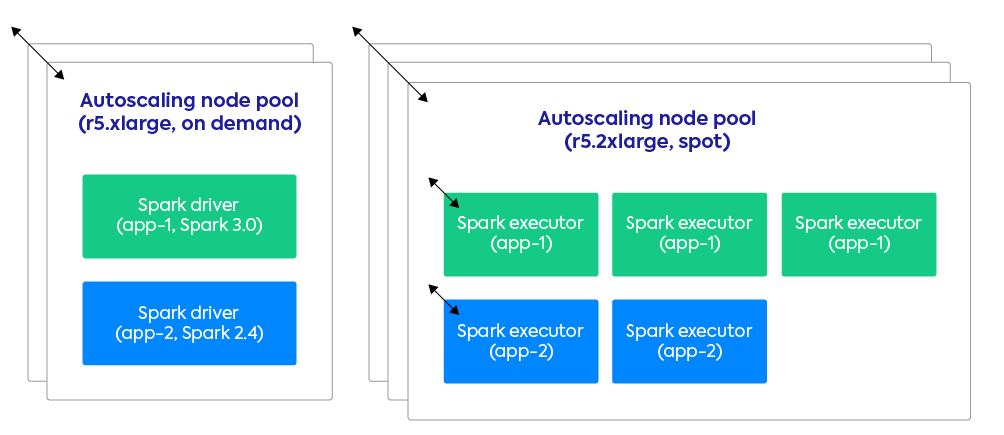
3. Integration in a rich ecosystem – cloud-agnostic & with less vendor lock-in

Deploying Spark on Kubernetes gives you powerful features for free such as the use of namespaces and quotas for multitenancy control, and role-based access control (optionally integrated with your cloud provider IAM) for fine-grained security and data access.
If you have a need outside the k8s scope, the community is very active and it’s likely you’ll find a tool to answer this need. This point is particularly strong if you already use Kubernetes for the rest of your stack as you may re-use your existing tooling. It also makes your data infrastructure more cloud-agnostic and reduces your vendor lock-in!
The Neutral – Spark performance is the same
We ran benchmarks that prove that there is no performance difference between running Spark on Kubernetes and running Spark on YARN.
In our blog post – Apache Spark Performance Benchmarks show Kubernetes has caught up with YARN – we go over the setup of the benchmark, the results, as well as critical tips to maximize shuffle performance when running Spark on Kubernetes.
Despite the raw performance of Spark being the same, you can generate significant cost savings by migrating to Spark on Kubernetes as we mentioned earlier. Read the story of a customer who reduced their costs by 65% by migrating from YARN (EMR) to Spark-on-Kubernetes (Data Mechanics).
The Cons – Drawbacks of Spark on Kubernetes
1. Making Spark-on-k8s reliable at scale requires build time and expertise
If you’re new to Kubernetes, the new language, abstractions and tools it introduces can be frightening and take you away from your core mission.
And even if you already have expertise on Kubernetes, there’s a lot to build:
- Create and configure the Kubernetes cluster and its node pools
- Setup the spark-operator and k8s autoscaler (optional, but recommended)
- Setup a docker registry and create a process to package your dependencies
- Setup a Spark History Server (to see the Spark UI after an app has completed, though Delight can save you this trouble!)
- Setup your logging, monitoring, and security tools
- Optimize application configurations and I/O for Kubernetes
- Enable spot/preemptible nodes on your cluster (optional, but recommended)
- Building integrations with your notebooks and/or your scheduler
This is why we built Data Mechanics – to take care of all the setup and make Spark on Kubernetes easy-to-use and cost-effective for everyone, from the smallest teams to large enterprises. Read How Data Mechanics Improves on Spark on Kubernetes open-source to learn more about what our platform offers on top of open-source.
2. You should be running the latest Spark versions
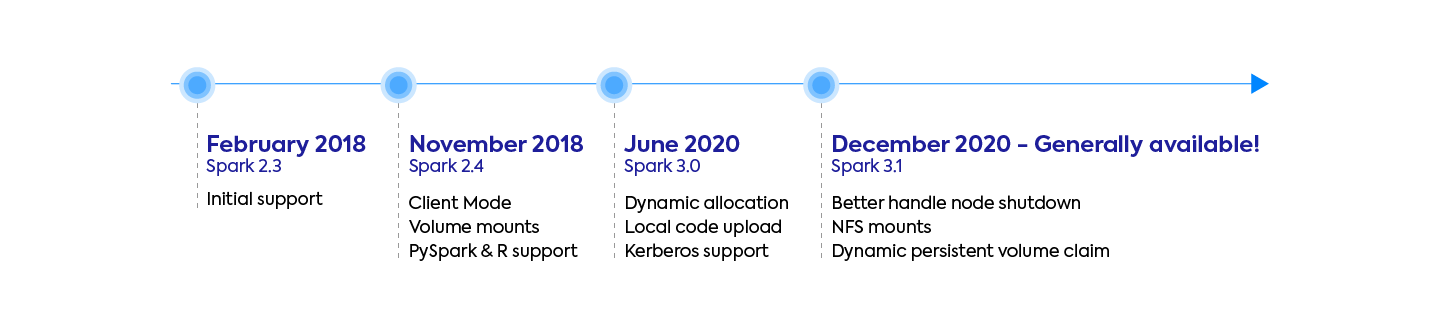
Initial support for Spark on Kubernetes started with Spark 2.3 in February 2018, but this version was lacking critical features. At Data Mechanics, we only support Spark 2.4 and above. We highly recommend using:
- Spark 3.0 and above: To benefit from dynamic allocation – the ability for each Spark application to add and remove Spark executors dynamically based on the load. This feature is very important if you intend to use Spark in an interactive way (from notebooks). It’s the only way to make them cost-effective.
- Spark 3.1 and above: Spark-on-Kubernetes was officially declared Generally Available and Production Ready with this release – read our article to dive deeper into the Spark 3.1 release. It brought critical stability and performance improvements, in addition to powerful features, like the ability for Spark to anticipate spot kills and gracefully shutdown executors (without losing their shuffle and cached data) before they are interrupted.
Conclusion – Should You Get Started ?
Traditional software engineering has shifted towards cloud-native containerization over the past few years, and it’s undeniable a similar shift is happening for big data workloads. In fact since Spark 3.1 (released in March 2021), Spark on Kubernetes has officially been declared as Generally Available and production-ready.
Does it mean that every data team should become Kubernetes experts? Not at all. We’ve built Ocean for Apache Spark for precisely for that reason. To make Spark on Kubernetes absolute setup- and maintenance-free. We’ve helped many customers run Spark on Kubernetes, both for new Spark projects or as part of a migration from a YARN-based infrastructure. Our platform improves on top of the open-source version by adding intuitive user interfaces, notebook and scheduler integrations, and dynamic optimizations that typically generate 50 to 75% cost savings.
We’d love to help! Book a demo with us to get started.