 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

It’s been six years since Kubernetes v1.0 was released in 2015, and since then it’s become a critical technology foundation to deploy modern, cloud native applications with speed, develop them with agility and scale them with flexibility. With a fast-maturing ecosystem, advancements in tooling are making it possible for a new Ocean for Apache Spark of applications to be deployed on Kubernetes. Stateful, big data applications, once thought to be too hard to manage with Kubernetes, are now catching up and using it as a first-class cluster orchestrator.
With more and more of our customers moving their big data, ML and AI applications into Kubernetes, Spot is excited to announce the launch of Ocean for Apache Spark, a serverless container engine designed specifically for big data applications.
![]()
Why Ocean for Apache Spark?
While Kubernetes brings simplicity and standardization to containers and services, it makes the underlying cloud infrastructure challenging to manage. Even experienced DevOps teams struggle with the manual, complex and resource-intensive tasks for scaling, provisioning and managing infrastructure. Getting this right can help companies achieve the promises of Kubernetes and the cloud, but getting it wrong can lead to wasted resources, burned out teams, underperforming applications and high cloud bills.
Kubernetes for Big Data teams
For big data applications, the same cloud infrastructure challenges that DevOps face exist, but with even higher hurdles and steeper learning curves for data engineers and scientists, who often take on the work of Kubernetes themselves. Even with the help of managed services like EKS for EMR, operating Kubernetes is difficult. From initial cluster configurations, to setting up autoscaling, to everyday maintenance, learning how to do everything right and manage the compute, storage and networking infrastructure slows these teams down and distracts them from driving data initiatives.
Growing cost of data environments
According to Gartner, by 2022 public cloud services will be essential for 90% of data and analytics innovations, and by 2025, 75% of enterprises will shift from piloting to operationalizing AI, driving a 5X increase in streaming data and analytics infrastructures. As big data continues to grow at this pace, the cost of scaling cloud environments to support it also grows. Although the cloud providers offer ways to utilize cloud compute for less cost with spot and reserved instances, applying these pricing models effectively and reliably to get costs under control can take a huge effort that exceeds the capabilities and scope of big data teams.
Spot designed Ocean for Apache Spark to address these challenges and give big data applications automated, scalable, and reliable cloud infrastructure. With Ocean for Apache Spark, data teams gain greater agility and flexibility for their big data applications and they can focus on data, not platforms. Built with the same core technologies that power Ocean, Spot’s serverless container engine, Ocean for Apache Spark takes on the infrastructure needs of big data.
What is Ocean for Apache Spark?
As the data community moves more towards microservices, Apache Spark, the go-to open source framework for big data, AI and ML applications, began to natively support Kubernetes. With Spark 2.3, users have a Kubernetes scheduler to deploy workloads and manage their clusters. The rising popularity of both Kubernetes and Spark motivated Spot to build a tool that would change how big data teams think about the infrastructure supporting these applications.
Bringing serverless infrastructure to Spark
Ocean for Apache Spark is leveraging the same core capabilities that Ocean uses to scale infrastructure when a Spark job is deployed on Kubernetes. When a request comes in, Ocean for Apache Spark will provision infrastructure, intelligently using a mix of spot, on-demand and reserved instances to optimize cost.
Ocean for Apache Spark spins up Spark-aware infrastructure with autoscaling mechanisms that match instance type and size to Spark jobs, based on container requirements, giving applications the optimized compute they need to run at scale. By monitoring cloud resource utilization, both in real time and over time, Ocean for Apache Spark continuously tunes configurations for recurring Spark jobs, optimizing infrastructure for performance and cost. Over time, this autonomous system improves the reliability and efficiency of your cloud environments, enabling applications to take full advantage of the power of Kubernetes and the cloud.
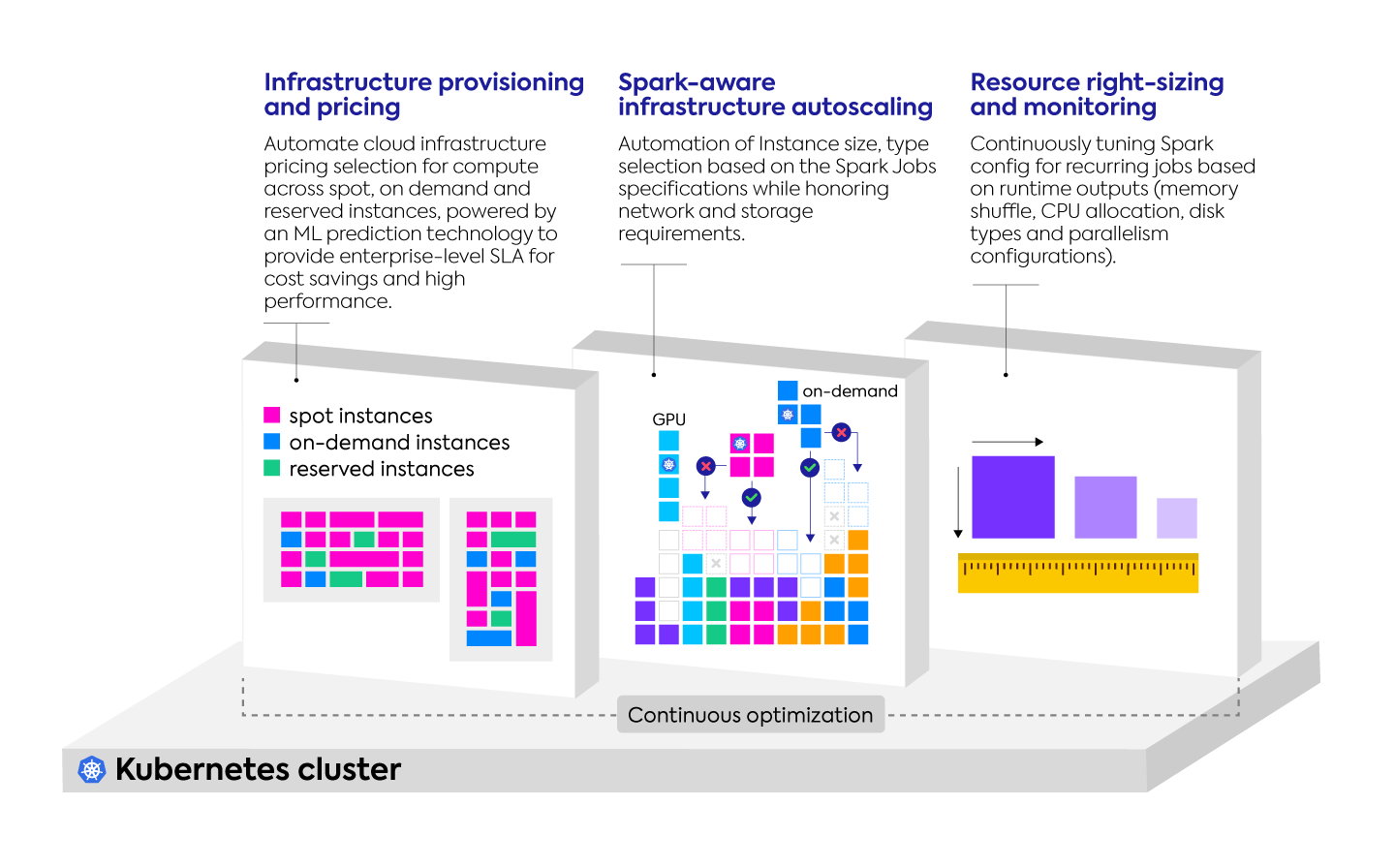
Tailored for big data
One of the biggest challenges that big data teams face is the unfamiliarity of tooling for cloud services, containers and Kubernetes. Ocean for Apache Spark makes it easy to use existing workflows and plug into pre-built integrations for JupyterHub, Airflow, Spark History Server and spark-submit. Users can configure Jupyter notebooks locally, while executing Spark applications on Kubernetes remotely. From setup to configuration, to resource provisioning and management, Ocean for Apache Spark removes the complexities of cloud infrastructure, so data engineers and scientists can focus on building and delivering powerful data applications.
Under the hood
Cluster management with Kubernetes and Ocean for Apache Spark
Before Kubernetes was ready for big data deployments, users were managing their clusters with either the built-in Spark scheduler, Apache Mesos or Hadoop YARN. These cluster managers are replaced by Kubernetes, affording containers more efficiency, and bringing unified management to infrastructure. Kubernetes makes it easier to have multiple deployments without a dedicated cluster, unlike Spark with YARN. Applications can be run in isolation of each other while utilizing the same shared resources, and Kubernetes takes care of allocating Spark jobs to nodes.
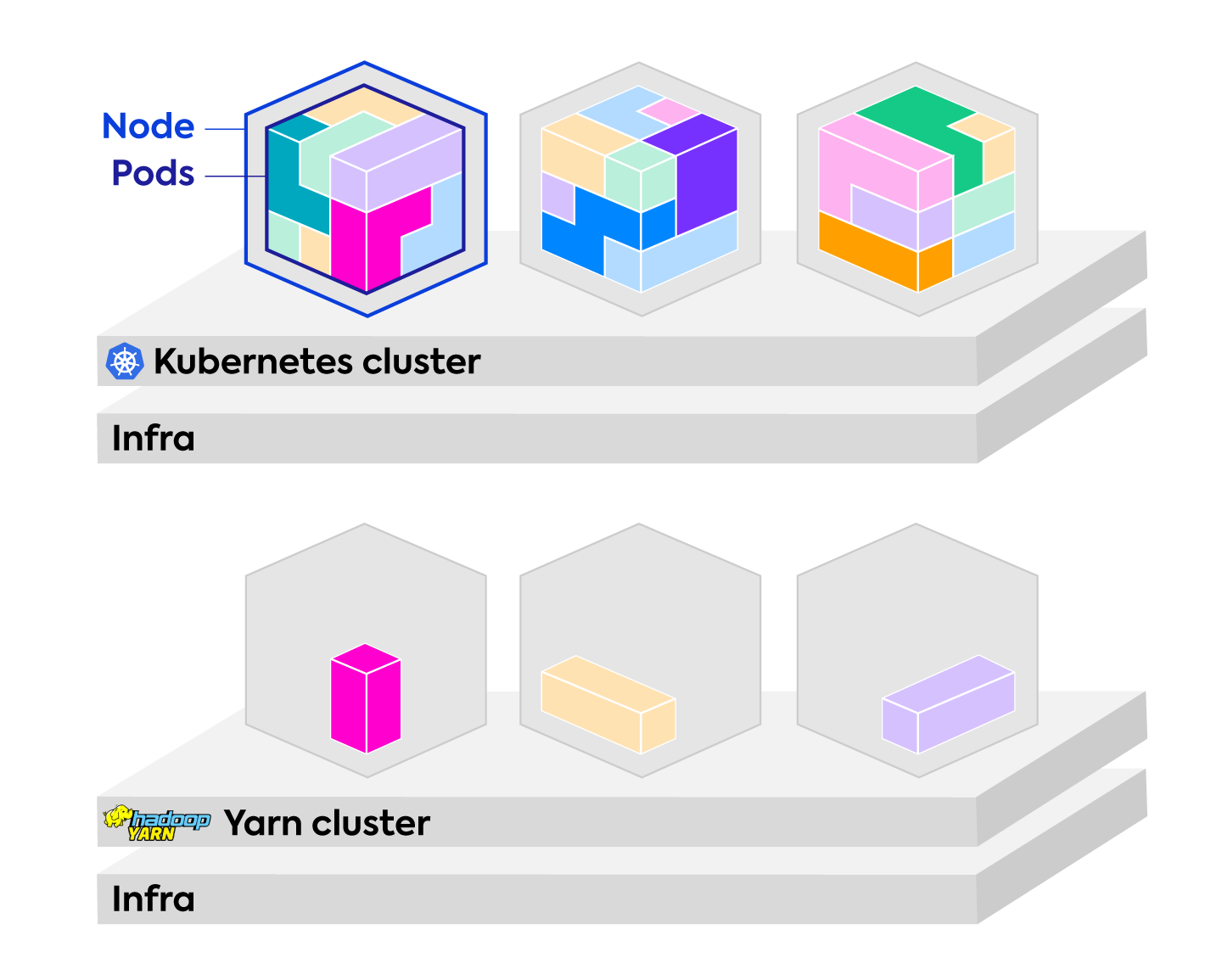
While Kubernetes brings more efficiency, easier management and scalability to applications, Ocean for Apache Spark extends those benefits to the underlying infrastructure in several different ways with a fully-managed data plane for your Spark clusters.
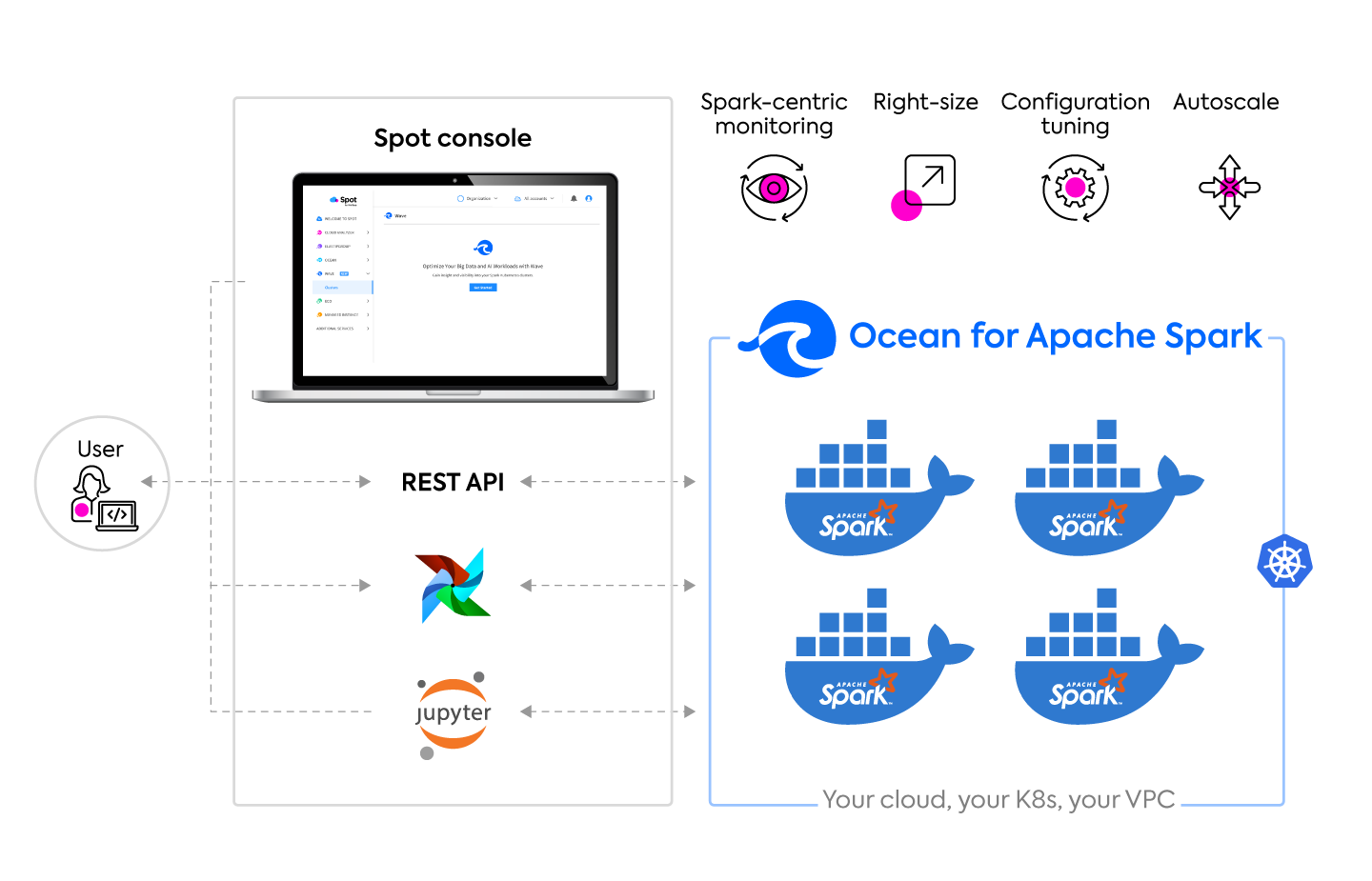
Once integrated with your environments, Ocean for Apache Spark takes care of setting up the infrastructure required to deploy and scale Spark executor pods. Ocean for Apache Spark handles all the provisioning, autoscaling, management and optimization of your infrastructure with these core features and functionalities:
Optimization Engine
Like Ocean, Ocean for Apache Spark takes a container-driven approach to infrastructure. Leveraging advanced AI algorithms, Ocean for Apache Spark’s autoscaling mechanisms monitor the resource requirements of incoming Spark jobs and automatically choose the best infrastructure to run an application at the highest performance. Taking into account the specific requirements of incoming workloads, Ocean for Apache Spark matches CPU, RAM, and other resources in real-time to scheduled pods.
Spark Application right-sizing
Big data applications are often resource-intensive, requiring a lot of compute power to ingest, process, normalize and analyze. However, estimating how much memory, CPU and other resources an application needs is not a simple task, especially for big data teams that don’t have the expertise to estimate or plan for their application’s resource consumption.
Ocean for Apache Spark’s automated right-sizing capabilities take this responsibility away from teams and provide ways to improve the resource configurations of deployments and jobs. By comparing resource requests to actual consumption over time, Ocean for Apache Spark continuously tunes configurations to avoid overprovisioning of nodes, prevents under-utilization and ensures that enough resources are provisioned.
Spark Executor bin packing
Using advanced algorithms, Ocean for Apache Spark automatically and efficiently bin packs Spark executors to get the most of out of the existing nodes before provisioning more instances. Taking into account Spark-job specific considerations, Ocean for Apache Spark optimizes resource allocations by determining if multiple containers should be placed on the same instances or spread across a group of them.
Automated headroom
It’s common for big data workloads to have periods of low activity, followed by times where they need to quickly scale. It’s important that infrastructure match the scalability of the applications running on it, and with Ocean for Apache Spark’s automatic headroom feature, users are assured that their systems can adapt to infrastructure needs. Ocean for Apache Spark maintains default excess capacity to quickly scale additional workloads instantaneously without users having to wait for additional nodes to be provisioned.
Getting started with Ocean for Apache Spark
The Ocean for Apache Spark environment consists of a Kubernetes cluster with all of Ocean for Apache Spark’s components installed. Ocean for Apache Spark users can create a cluster at the command-line or easily import existing clusters to Ocean for Apache Spark. Users will be able to access Ocean for Apache Spark directly from the Spot console, and see metrics for capacity usage, cost analysis and cluster status.
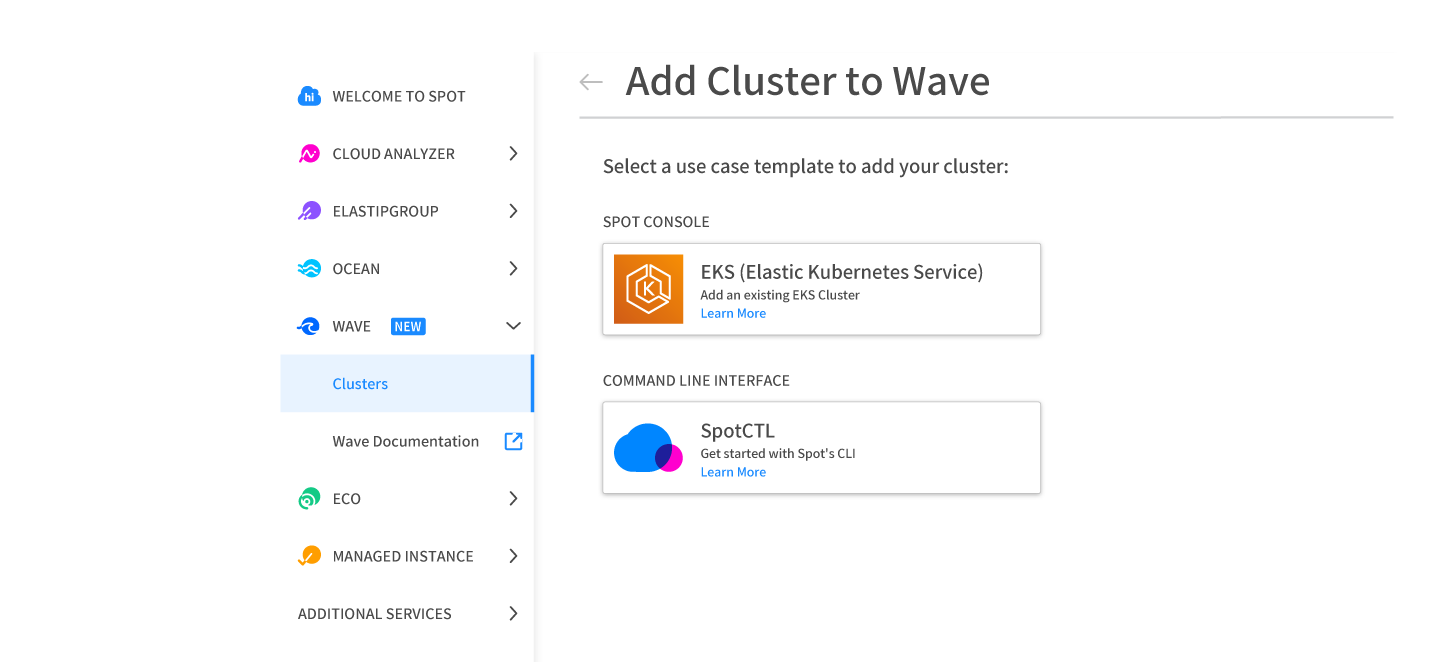

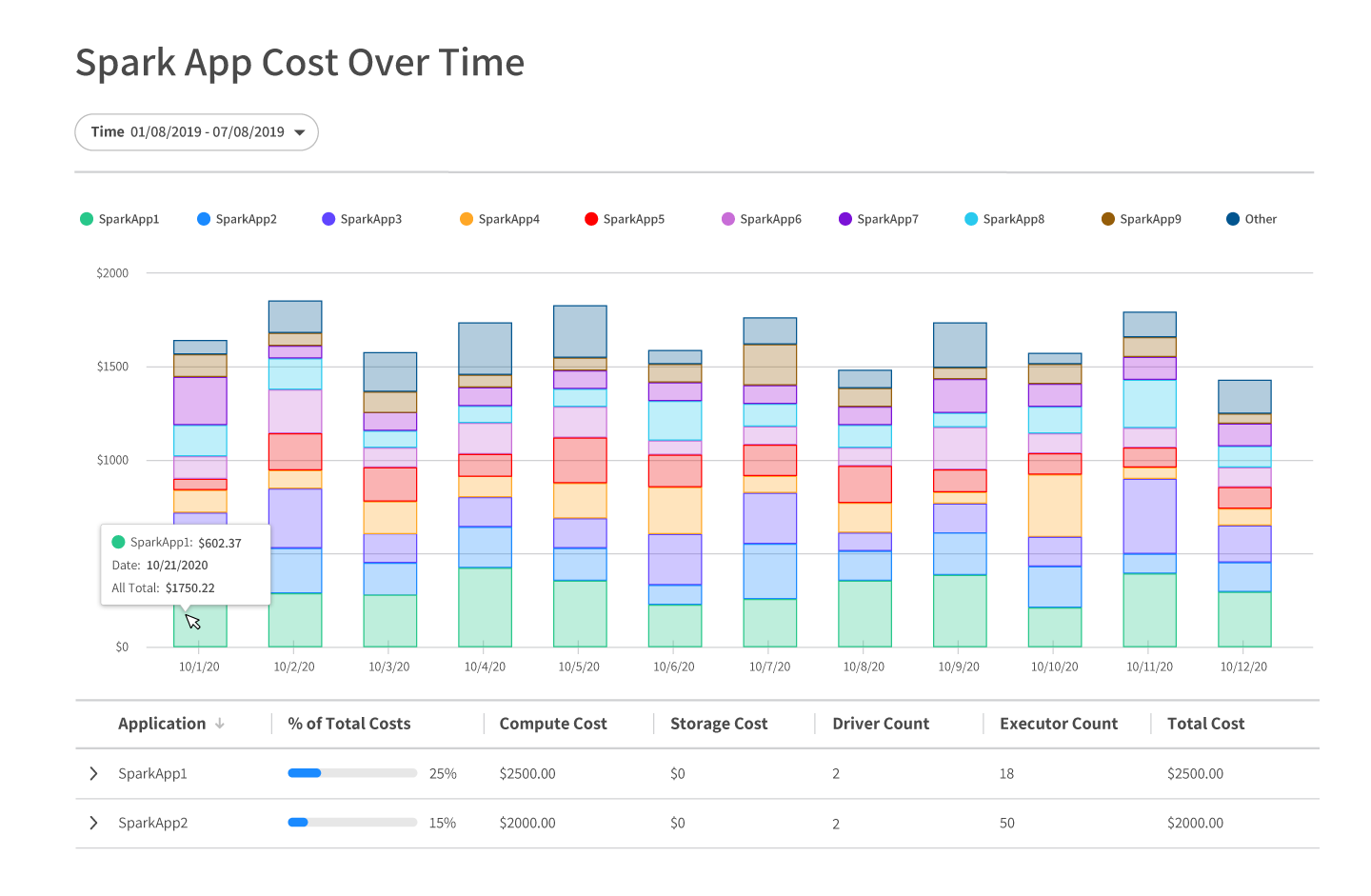
Get the first look at Ocean for Apache Spark!
To learn more, visit the Ocean for Apache Spark page and connect with us to schedule a demo to see what Ocean for Apache Spark can do for your big data applications.