 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

When it comes to modern container orchestration, there are a variety of control plane solutions for managing your applications in a containerized environment. Users can opt for managed services (i.e. Amazon EKS and ECS, Google GKE and Azure AKS) or run their own orchestration with Kubernetes. However, the dynamic nature of containers introduces operational complexities that can make your cloud infrastructure difficult to manage.
Infrastructure services like compute, networking, and storage need to be both flexible and efficient as you scale your applications, and if not managed properly, can result in higher bills and low performance. An intelligent data plane solution can help auto scale container workloads, and optimize the cost of your container infrastructure. However, this combination of performance, high availability and cost efficiency often involves significant configuration and manual maintenance efforts.
Introducing Ocean by Spot
Ocean is a product designed to address the challenges we presented so far. It is a managed data plane for Kubernetes and ECS, designed to provide a serverless infrastructure experience for running containers on the cloud.
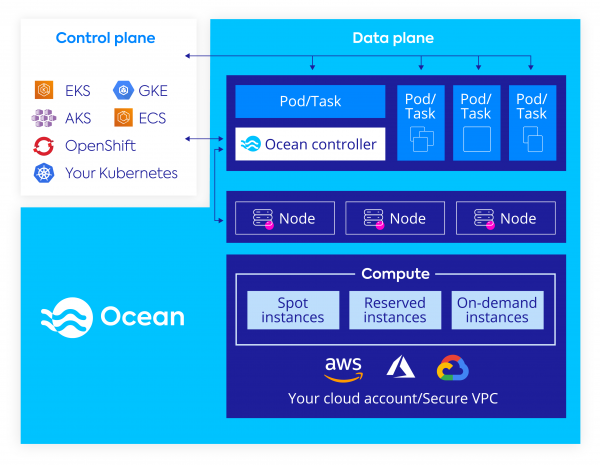
Ocean is designed to work in such a way that pods and workloads can take advantage of the underlying capabilities of cloud compute infrastructure such as pricing, lifecycle, performance, and availability without having to know anything about it.
Ocean integrates with your Control Plane of choice (EKS, GKE, AKS, ECS, Openshift, Docker Swarm or standalone K8s) and provides a fully managed data plane. It takes care of setting up the compute, networking and storage required to provision and scale the Worker Nodes (K8s), or Container Instances (ECS).
Ocean addresses the following key areas of container infrastructure management: right-sizing and bin packing, pricing optimization and health scoring, and infrastructure provisioning.
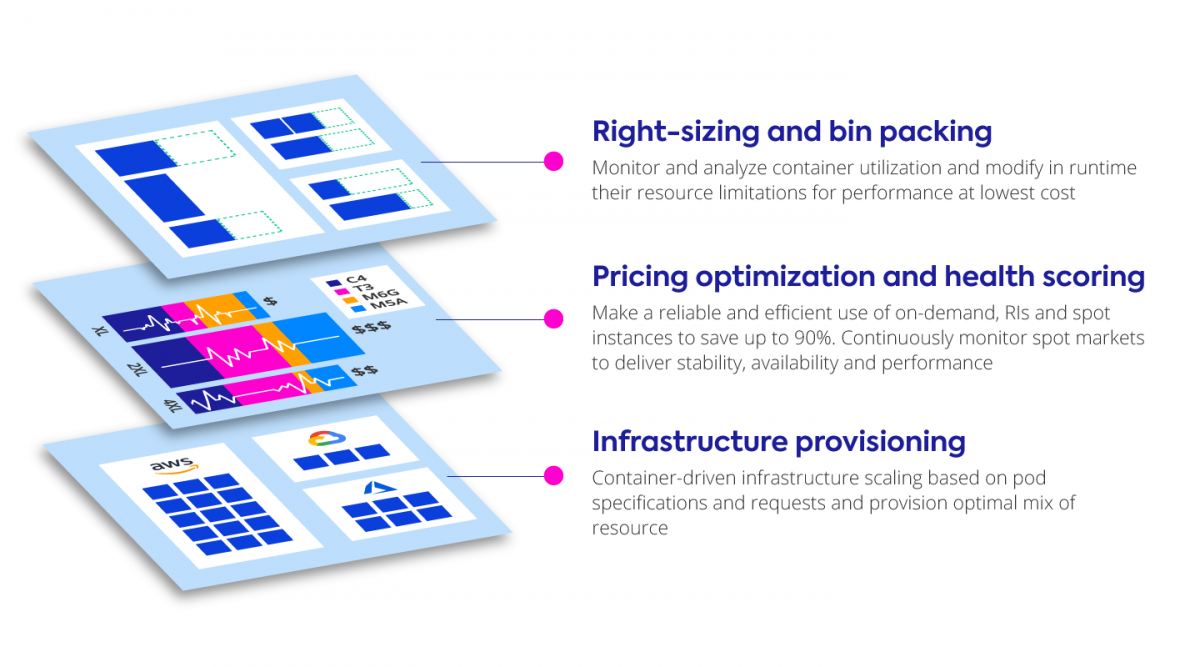
How does it work?
Ocean connects to the cluster’s control plane via a Controller Pod (in the case of K8s) or directly via API (for ECS). This connection allows Ocean to see the status of the cluster, it’s resources and respond accordingly.
Ocean infrastructure provisioning works by watching events at the Kubernetes API Server, affording it levels of visibility and flexibility that cannot otherwise be achieved, ensuring dependable performance, fast scalability, and up to 90% lower cloud infrastructure costs
When launching instances, Ocean supports an optimal blend of lifecycles. The preference is running on spare capacity, which provides the optimal cost. However, when vacant reservations are available, Ocean will utilize them first, since they are already paid for.
Moreover, Ocean leverages its predictive capabilities to predict spare capacity interruption, and is able to proactively replace endangered instances with ones from safer markets, or fall back to On Demand if needed. This proactive approach means that nodes are able to drain gracefully, and their workload migrated to their replacements without any downtime.
All of this happens automatically, with minimal setup required. Users can create a new Ocean cluster to join their existing container cluster within minutes, and let Ocean get to work. This creates a “serverless containers” experience, which frees engineers to focus on developing new projects rather than on maintaining infrastructure. However, Ocean does provide granular control and deep visibility for those who want it, with many additional features. In the next section, we’ll explore those.
Under the hood
In this section we’ll cover additional features and functionality that Ocean brings to the table, and how they make Ocean stand out as a unique solution in the container infrastructure management sphere.
Autoscaling – Container Driven Design Pattern
Ocean is built on top of a “container driven” Auto Scaling software (Patent PATS: 505789595), developed by Spot, which is responsible for scaling the cluster up and down to accommodate container workloads. The Auto Scaling software studies the resource requirements of incoming workloads and pods sizes and uses bin-packing algorithms to scale up instances of matching size and type. It takes into account additional considerations such as networking, storage, cpu platform, price or availability requirements, while honoring k8s labels, annotations and PDBs (Pod Disruption Budgets).
The autoscaler continuously simulates variations of the cluster, and looks for instances it can scale down while maintaining availability. When it finds a node whose workload can safely be rescheduled on other nodes, its pods/tasks will be drained and the node will be scaled down.
This combination of optimal scale up with efficient scale down results in a highly utilized cluster for minimum costs.
Headroom
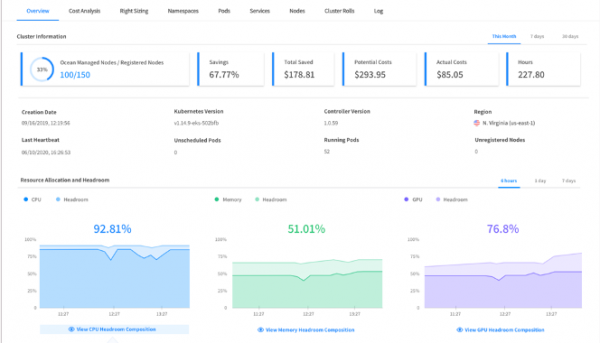
Ocean’s Autoscaler also provides the option to include a buffer of spare capacity (vCPU and memory), known as headroom. The headroom ensures that the cluster has the capacity to quickly scale additional workloads without waiting for new nodes to be provisioned and registered to the cluster. By default, the headroom maintained is 5% of the cluster’s total resources, but it can be configured to different amounts that will scale up and down with the cluster, or set manually to a permanent size. Ocean offers rich visibility into the headroom capacity calculation in your cluster–headroom allocations, broken down by CPU, memory and GPU, can be seen granularly at the node, or aggregated at the VNG and cluster levels.
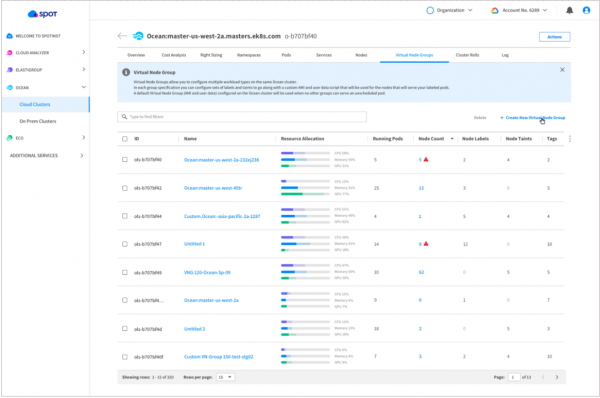
Virtual Node Groups
Managing differed types of workloads on the same k8s/ECS cluster would require managing several logical entities, also known as node groups (or different AWS Autoscaling Groups, Google Cloud Platform NodePools, etc.).
This issue is addressed by one of Ocean’s key features, Virtual Node Groups (previously called launch specifications). From a tab on the Ocean console, users will be able to configure labels and taints for their workloads, and have a view into data on resource allocation and headroom. VNGs allow users to manage different types of workloads on the same clusters that can span multiple AZs and subnets. It’s a key feature in Ocean that goes beyond describing instance properties, offering governance mechanisms, scaling attributes and they are responsible for the worker node groups in the cluster. VNGs deliver physical separation between different Kubernetes workloads, allowing teams to carve out the infrastructure within a single cluster as per their needs.
Right Sizing
Estimating pod/task resource requirements in terms of vCPU and memory is not a simple task. Even if development teams manage to achieve an accurate estimate of their application’s resource consumption, chances are that these measurements will differ in a production environment. Thankfully, Ocean’s Right Sizing feature compares the CPU & memory requests of the workloads to their actual consumption over time. Analyzing the comparison provides right-sizing suggestions to improve the resource configuration of the deployments/services. Applying correct resource definitions can help avoid over-provisioning of extra space to nodes, preventing underutilization and higher cluster costs, or under-provisioning of too little resources, which could result in different errors in the cluster, such as OOM events.
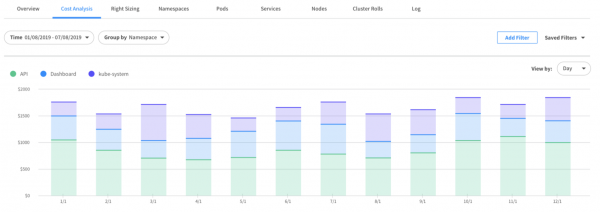
Visibility, Cost Analysis and Showback
Ocean enables users to drill down into the cluster resources with the help of detailed dashboards: Resource allocation and utilization views, cost analysis per namespace, node, deployment, pod/task and right down to the container level. Costs can be viewed for different time periods, and custom filters can be applied based on Labels and Annotations.
Blue/Green Nodes Upgrades – Cluster Roll
One of the challenges of maintaining an elastic infrastructure at scale is deploying configuration updates that affect launch configurations across the cluster. Ocean tackles that challenge with the intelligent Cluster Roll feature. With the application-aware Ocean Cluster Roll, users can deploy their cluster with one click. Ocean will perform a Blue-Green Deployment of the cluster nodes, taking into consideration the pods or tasks currently running in the cluster, and suspending any auto-scaling related activity, until the roll is completed. The resulting nodes will be optimized for the running workloads requirements in terms of their size, type, and launch specs, requiring no further readjustment.
Getting Started with Ocean
Ocean provides a simple migration tool that completely automates the import and setup process so that you can import an existing Kubernetes cluster to Ocean in minutes. Once triggered, Ocean will gracefully and automatically drain existing worker nodes in batches, and launch new instances (managed by Ocean) to accommodate the cluster’s workload, all while taking into account any requirements and placement constraints. The entire process is completely transparent and visible to the user, with configurable options such as batch size, standalone pod eviction, and auto-termination of nodes.
If you are interested in learning about getting started with Ocean, visit the Spot Ocean page, head over to the Ocean documentation page, or try out Ocean.