 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

The release of Apache Spark 3.4 introduced Spark Connect, and we are thrilled to announce that we now offer full support for Spark Connect on Spot Ocean for Apache Spark. This blog will provide an overview of what Spark Connect is and how to effectively utilize it with Spot Ocean for Apache Spark.
What is Spark Connect, and why does it matter for Ocean for Apache Spark?
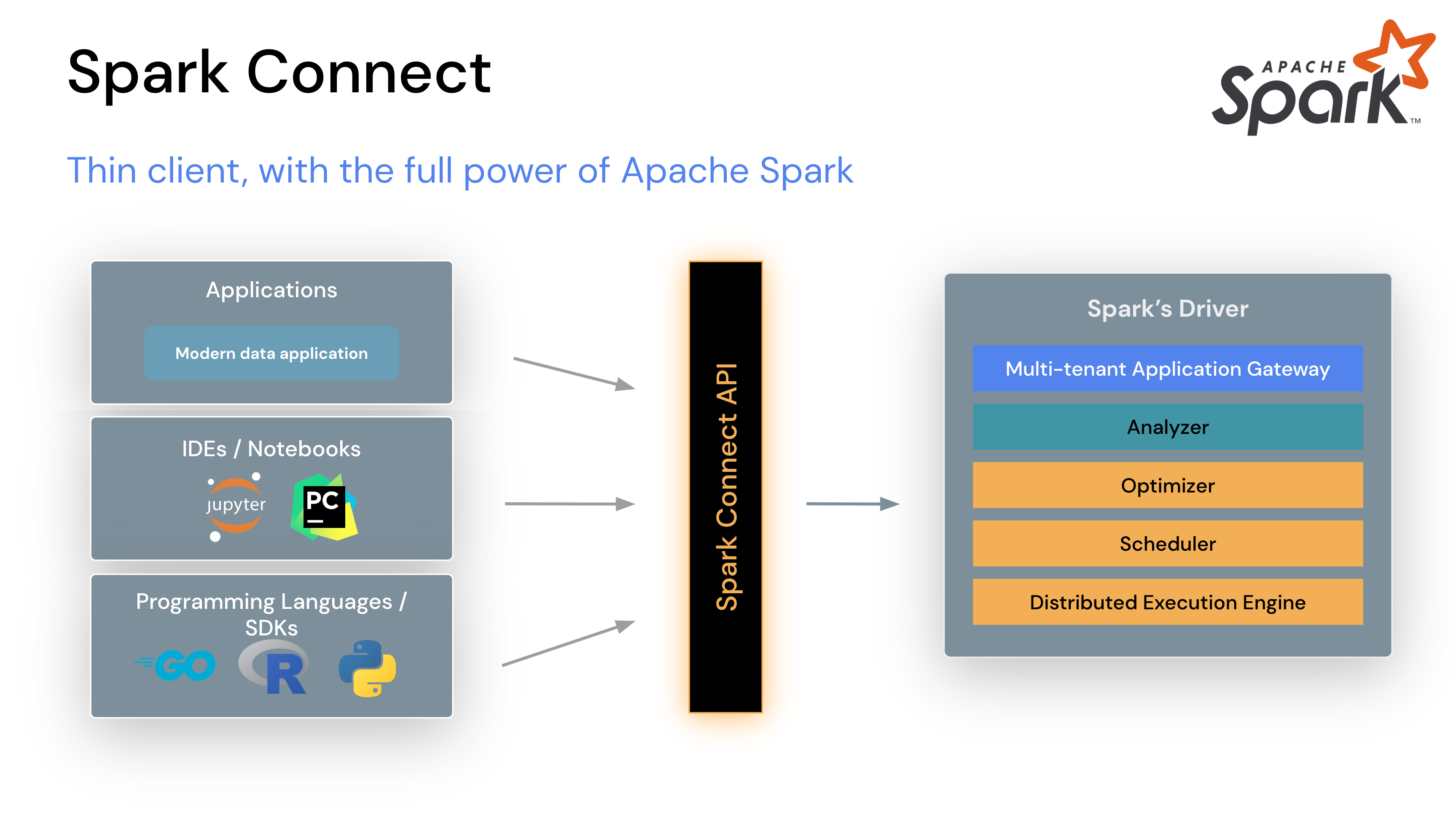
Spark Connect was introduced as a pivotal feature to decouple the client-server architecture. This simplifies the process of interacting with Apache Spark for integrated development environments (IDEs) and modern data applications, with minimal configuration and setup. Spark Connect enables users to establish a connection to Spark using a lightweight client, irrespective of their choice of programming language.
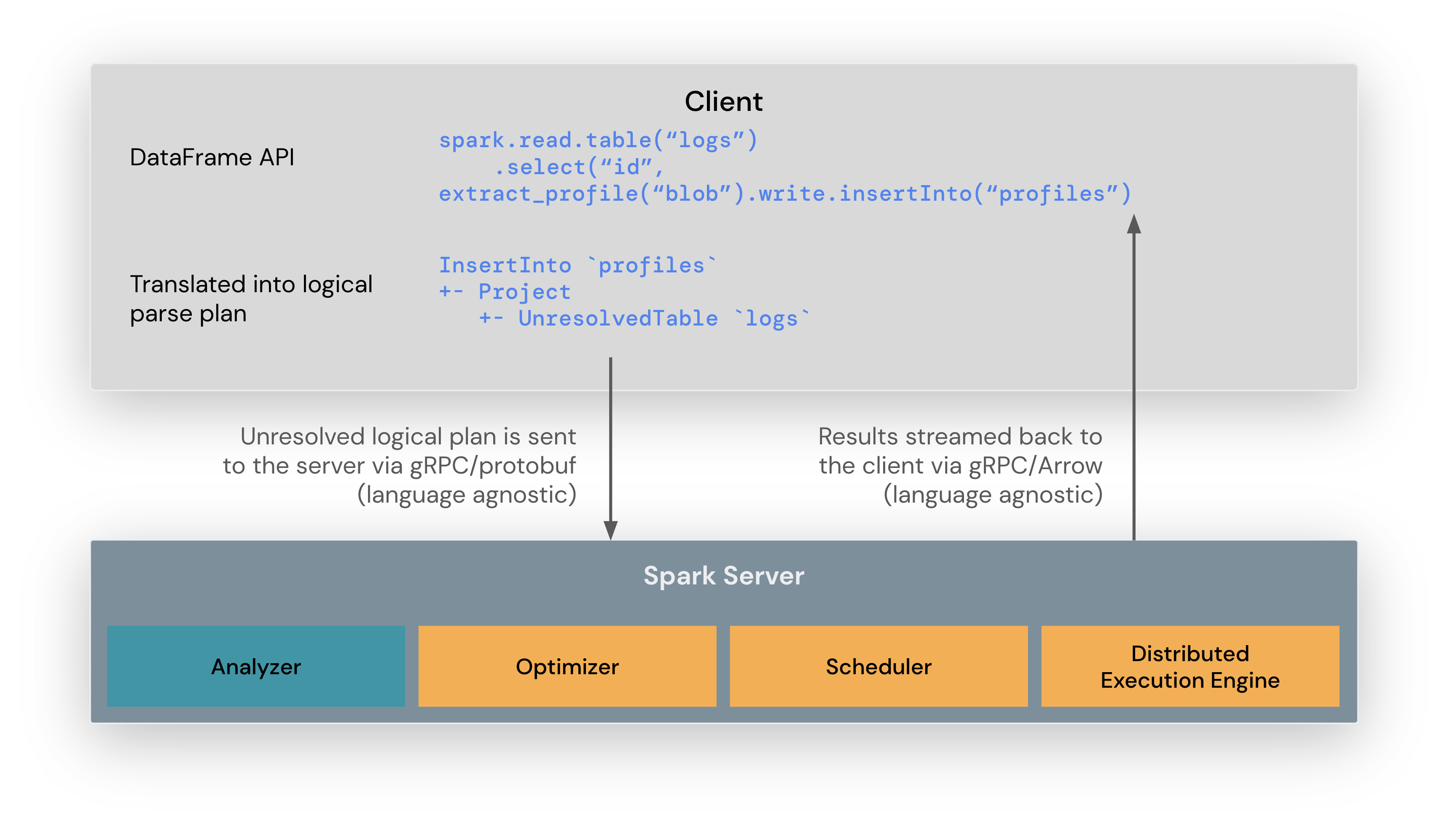
From Spark Connect documentation: “The Spark Connect client is a library designed to simplify Spark application development. It is a thin API that can be embedded everywhere: in application servers, IDEs, notebooks, and programming languages. The Spark Connect API builds on Spark’s DataFrame API using unresolved logical plans as a language-agnostic protocol between the client and the Spark driver.”
By adopting Spark Connect, Ocean for Apache Spark improved the performance of its Jupyter Notebook integration. Spark Connect offers the convenience of establishing connections to Ocean for Apache Spark from various sources, including terminals and code execution.
Built upon the gRPC framework, Spark Connect significantly extends its language compatibility beyond the existing support in Spark notebooks. By incorporating new languages and frameworks like Go, Rust, and JavaScript, Spark Connect allows for direct interaction with Ocean for Apache Spark from virtually anywhere (even a webpage!).
What are the benefits for Ocean for Apache Spark users?
As developers, we all have preferences for various languages and frameworks, each with its unique appeal and strengths. For Ocean for Apache Spark users, this expansion in language support empowers users to seamlessly integrate Spark into a wider range of data applications and platforms, enhancing its versatility.
Spark Connect brings several advantages:
Enhanced Stability
The decoupled architecture contributes to enhanced stability by isolating clients from the driver component, minimizing potential disruptions.
Version Flexibility
From the perspective of Spark Connect clients, Spark becomes nearly version-agnostic. This flexibility ensures seamless upgradability, allowing server APIs to evolve independently without impacting the client API.
Integration Opportunities
The decoupled client-server model opens doors to create tight integrations with local developer tools, providing developers with a more cohesive and efficient workflow.
Lighter Operability
With the reduction of Spark components on the client side, it is easier to run Spark on smaller devices.
Improved Security
Separating the client process from the Spark server process enhances Spark’s overall security. This separation mitigates the risks associated with tightly coupling the client within the Spark runtime environment.
Additionally, Spark Connect introduces a pivotal shift by moving a layer of functionality to the client side. In the context of Spark’s map/reduce paradigm, data collection now occurs on the client side during the reduce phase. Consequently, all subsequent steps like charting and visualization become the responsibility of the client. This enables us to reduce dependencies within our cloud images, making the deployment process more efficient and the Spark applications less resource intensive.
Ocean for Apache Spark amplifies Spark Connect
Where Spark Connect enables developers to build lightweight, interactive, collaborative clients, Ocean for Apache Spark brings developer-friendliness, resource-efficiency, and cost-savings. If you are integrating a Spark Connect client, three significant benefits of Ocean for Apache Spark are dependency management, right sizing, and live optimization of applications. Ocean for Apache Spark:
- Builds Docker images by testing interdependencies among data engineering libraries
- Auto scales, up and down, Kubernetes nodes and Spark memory, to increase performance and reduce cost
- Parses I/O, CPU, and memory metrics to produce detailed UI charts that suggest improvements to the stability, performance, and efficiency of a developer’s application
How to use Spark Connect with Ocean for Apache Spark
Please check our documentation for more details and guidance on how to use Spark Connect with Ocean for Apache Spark.
Spark Connect is just one of several integrations that Ocean for Apache Spark supports to help data teams run their Spark applications with Kubernetes. Learn how you can easily set up, configure, and scale Spark applications and Kubernetes clusters with Ocean for Apache Spark. Schedule an initial meeting with our team of Apache Spark Solutions Architects, so we can discuss your use case and help you with a successful onboarding to our platform.