 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Infrastructure optimization is the missing piece in your Internal Developer Platform (IDP) resource plane. Here’s how it can help your IDP make an impact, and ideas on how to weave it into your architecture.
Platform engineering and the infrastructure misconception
Infrastructure operations is among the top 3 functionalities and services of an IDP in most organizations, according to Puppet’s 2023 state of platform engineering survey. However, while there’s a consensus around resource provisioning as part of that, resource optimization has not been discussed so far. In fact, compute cost and availability as a juggling act has grown to be a platform engineering axiom. But with intelligent optimization baked into your IDP, it really doesn’t have to be that way.
Where dev and organizational needs meet
Besides making developers happy, the organization has other agendas. First and foremost, they need to deliver value to their stakeholders. For that, they must show profitability. Some strategies they pursue and are relevant to our case include:
- Increasing profit by becoming more efficient on the same budget
- Streamlining costs, including those for cloud infrastructure
- Minimizing liabilities that may result in expenses or loss of revenue, like downtime
With optimized resource provisioning, the IDP can support those strategies without undermining developer experience (DevEx). Unlike other IDP functionalities that affect how devs work, optimization of the underlying infrastructure occurs in the backend. Therefore, the IDP can be 100% opinionated regarding provisioning best practices without devs feeling limited or looked down upon. After all, if queues are avoided and performance is sufficient and consistent, who cares what those machines are called? Not your developers.
What constitutes intelligent optimization?
Optimization of an organization’s underlying infrastructure occurs in the backend. Platform engineers should choose the right tools to serve different stakeholders and business objectives.
If you want to build infrastructure optimization into your IDP, here are the main aspects to consider.
Utilization/efficiency optimization
When you delegate provisioning to a self-service platform with no optimization strategy, waste is 100% inevitable. Users will not pay attention to efficiency when their main task is to deliver code. Instead, they will want to ensure smooth application performance, regardless of cost. Unused machine capacity is not just budget down the drain – it’s also power consumption that harms the planet for no reason. This undermines the sustainability agendas that many large organizations have today.
Here are some provisioning rules that can turn this waste around:
- Default shutdown scheduling: Requested resources are eliminated after regular office hours, unless the developer opts out a specific cluster.
- Automated bin packing: Instead of having nine servers 10% utilized, gather those small workloads in one server. Bin packing can be user-specific or not, according to your security policies.
- Dynamic storage volume: Your IDP should regularly remove idle storage. It’s also recommended to align attached volume and IOPS with node size to avoid overprovisioning in smaller nodes.
Reliability/availability optimization
While spot machines are a big cost saver, they are also inconsistent and stateless by nature. To minimize spot interruptions, an IDP can benefit from several capabilities that increase spot consistency:
- Market intelligence helps choose the spot markets least prone to interruptions.
- Predictive rebalancing replaces spot machines before they’re evicted involuntarily due to unavailability.
- Data and network persistence for stateful workloads can normally be simply obtained by reattachment. One exception is when your OS or storage are hosted in a different AZ than your application. In this case, instead of reattachment, you will need frequent snapshots.
- “Roly-poly” fallback moves your workload to on-demand or existing commitments if there is no spot availability. When spots are once again available, you want to hop back onto them.
These crucial features make many workloads suitable to run reliably on spot capacity. In fact, spot capacity can gradually become your IDP’s provisioning standard, or default.
To determine the importance of highest uptime on a new cluster, your IDP should present developers with several preliminary questions:
- What are the technical requirements (e.g., memory, CPU, expected duration)?
- Does it require application persistence?
- Is it customer-facing?
Your IDP should consider those factors and provision accordingly. Remember: fault-sensitive and customer-facing workloads might not be good candidates for spot capacity, but they’re perfectly fit for other purchase options, like commitments.
Performance optimization
The idea is making sure your applications get the compute performance they need without overspending. In other words, you want to meet workload requirements, but not wildly exceed them. Requirements are typically part of the YAML, where resource requests at both container and pod level are specified.
To make this happen, your IDP should allow for a variety of machine types, considering:
- Underlying machine technologies such as CPU architecture and generation – enabling a mixture of x86 and ARM drives optimal balancing between cost and availability
- GPUs for model training workloads
- Specialized instance and VM families, such as compute-optimized, memory-optimized, or HPC
Your IDP should also have some workflows in place to serve post-deployment scenarios, such as:
- Autoscaling: This single word encompasses multiple procedures: knowing when to scale up or down, determining what types of instances to spin up, and keeping those instances available for as long as the workload requires. EC2 ASG’s is an example for rigid, rule-based autoscaling. You might want to get acquainted with additional K8s autoscaling methods like HPA or event-driven autoscaling.
- Automated rightsizing: Create a workflow automation for applying rightsizing recommendations. Define thresholds for the gap between resource requirement and actual utilization, and a timeframe to observe those before rightsizing. For example, if the gap consistently exceeds 15% in one hour, consider rightsizing.
Price & cost optimization
Discounted compute is a near-instant way to streamline how your organization uses cloud. Fault-tolerant workloads, whether stateless or stateful, are great candidates for spot machines – given that there is appropriate automation in place. Mature, predictable workloads that cannot tolerate spot interruptions are ideal for commitments like RIs or SPs. You want your IDP to provision and manage those automatically.
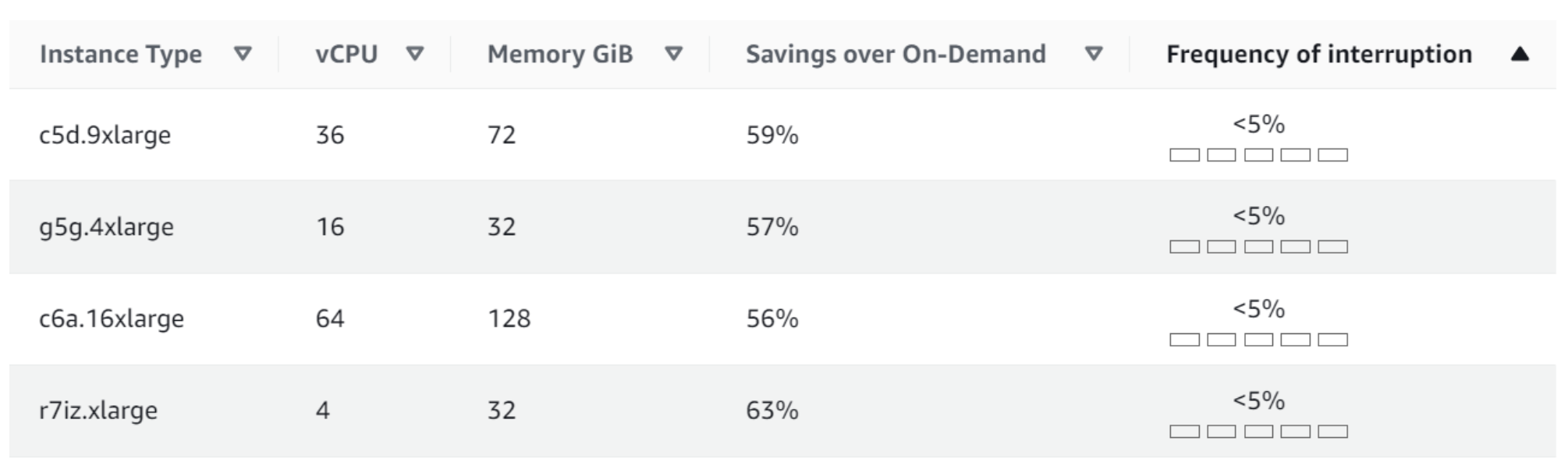
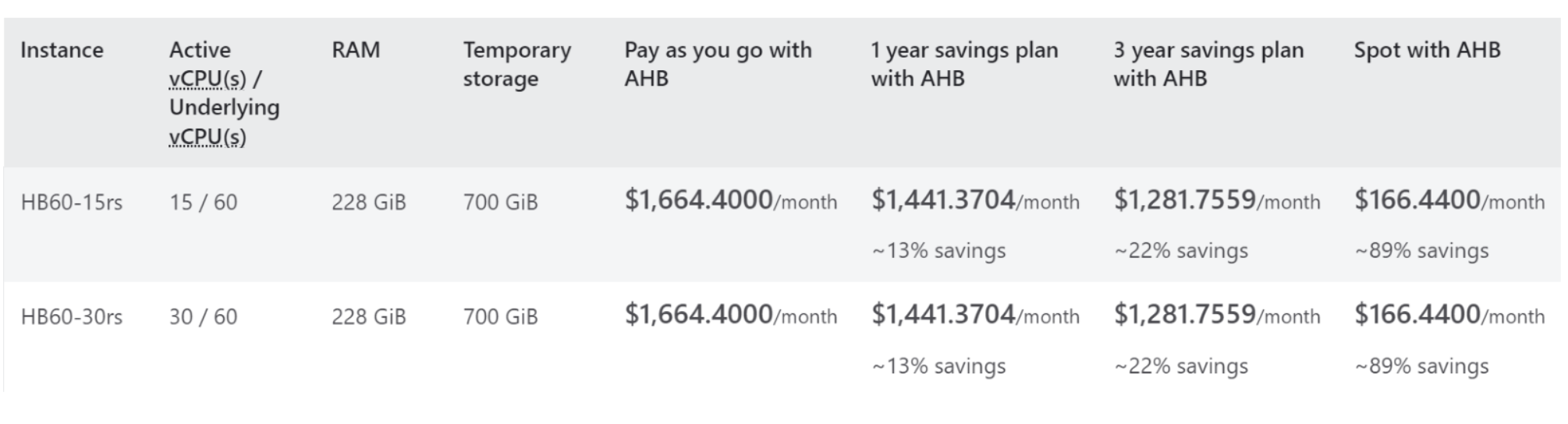
How to plan your IDP to provision discounted compute
Step 1: Map out common types of dev, testing, and production workloads in your organization. Be sure to record their actual storage, memory, and vCPU/GPU requirements.
Step 2: Using CSP spot tables like those sampled here and define the discounted resource that can serve them.
Step 3: Locate a third-party optimizer tool that positively supports your use case – both from CSP and workload standpoints. For example, if your organization frequently uses HPC, look for a tool that declaratively supports that.
Step 4: Integrate your optimizer into your IDP. Integration doesn’t have to be direct – many optimizers have Terraform modules for cluster creation or migration. Some modules may be CSP-specific, like this EKS-Terraform one.
Your IDP should enable cost accountability
An IDP gives developers the freedom to provision their own resources, within the policies you defined. And, as we just witnessed above, an IDP can and should be opinionated about the optimization of provisioned resources.
Still, an IDP is not complete without user observability into resource usage and spend. First, and most obviously, if you want Dev to be accountable for their consumption, you should provide them with a way to track it. It allows them to streamline proactively before they’re shouted at from the corner office (or desk).
Second, observability also allows Dev to be true partners in the platform design and in the organization’s FinOps initiative. Auditing their requests and usage patterns, they can provide feedback on the IDP’s guardrails. Are these guardrails relevant and effective in preventing waste? Or are they more of an impediment that requires hundreds of exceptions daily and should be revisited?
Suggested architecture
We’ve seen some ways in which resource optimization can make your IDP more impactful – for the engineering body and for the organization. How does this fit into your particular IDP architecture?
Let’s assume your platform team doesn’t have endless dev hours to build all these capabilities in-house. In this likely case, you’ll want a third-party optimization solution that delivers them out-of-the-box.
Let’s further assume that you don’t want to build integrations from scratch if you don’t have to. And you really don’t; infrastructure optimization SaaS can always be consumed via IaC. So, in relation to your IDP, the SaaS will deliver the optimization via Terraform modules, a plugin, or an SDK.
Here are some examples that apply to Spot’s optimization portfolio, and specifically Spot’s infrastructure optimization solutions: Elastigroup (for VMs) and Ocean (for containers).
- IaC modules: Terraform, CloudFormation, or Ansible modules can call the Spot API for actions like creating, updating, and deleting resources.
- Plug-ins: Spot Elastigroup has both Terraform and Jenkins plugins. This allows users to leverage Elastigroup both in provisioning and in single-VM CD pipelines.
- AWS ECS: Spot Ocean interacts with ECS clusters via API calls between the Spot SaaS and ECS. See docs.
- EKS: Spot Ocean can interact with EKS via EKSctl or Terraform. See docs.
- AKS: Spot Ocean interacts with the AKS API using oceanAKSClusterImport or Terraform providers for Ocean AKS cluster ocean-aks-np-k8s, Ocean AKS VNG ocean_aks_np_virtual_node_group.
- SDKs: Go, Java, and Python SDKs allow access to the Spot API.
We’re also working on direct integrations to some off-the-shelf portals. For case-specific advice on how to integrate Spot into your IDP, contact us today.

For more information on Spot’s provisioning integrations, visit our Tools & Provisioning documentation page. And if you’re ready to get started right away, log into the Spot console.