 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

The cloud native revolution brought by Kubernetes has transformed the way we build and deliver software, but the world of big data has for too long been left on the side of this transformation. Thanks to many contributions from the open source community, Apache Spark integration on top of Kubernetes is now officially generally available with the recent releases this year.
As Spot customers followed this trend and moved their data engineering, data science, and data analytics workloads to Kubernetes, we decided to accelerate this transition by building a fully automated and optimized Spark platform on top of Ocean, our serverless infrastructure engine for containers. The acquisition of Data Mechanics in June 2021 accelerated this roadmap as their capabilities were integrated.
Spot is excited to announce the launch of Ocean for Apache Spark, now available in preview for select AWS customers.
A New Approach To Running Apache Spark in the Cloud
The State of Apache Spark Today
Most deployments of Spark today run on top of Hadoop YARN or proprietary cluster managers. These deployment models require each application to run on its own isolated cluster, which is not cost effective, and often suffer instability due to a lack of isolation: global Spark versions and libraries, resource starvation and fate-sharing.
It falls upon end users to manage the infrastructure and configurations of their jobs, and make complex tradeoffs between costs, stability, and performance. This results in a big loss of productivity for data teams, and suboptimal infrastructure leading to poor performance and high cloud bills.
The Future of Apache Spark is Cloud-Native
The ability to run Apache Spark workloads inside isolated Docker containers managed by Kubernetes is a game-changer for the industry. It’s finally possible to use a single cloud agnostic infrastructure across the entire tech stack, from general-purpose microservices to big data.
But running Spark-on-Kubernetes open source or even using managed platforms like EMR on EKS, is hard. Data teams are forced to cope with the complexity of Kubernetes such as creating, scaling and maintaining the cluster itself, then configure Spark to run efficiently on top of it. Basic monitoring functionality is often missing – forcing Spark developers to go through painful manual troubleshooting whenever something is failing.
Ocean for Apache Spark gives data teams the power and flexibility of Kubernetes without its complexity. It provides Spark-centric interfaces designed to improve the developer experience, while its serverless infrastructure engine is continuously autoscaled and optimized to deliver the highest possible performance at the lowest possible costs.
What is Ocean for Apache Spark?
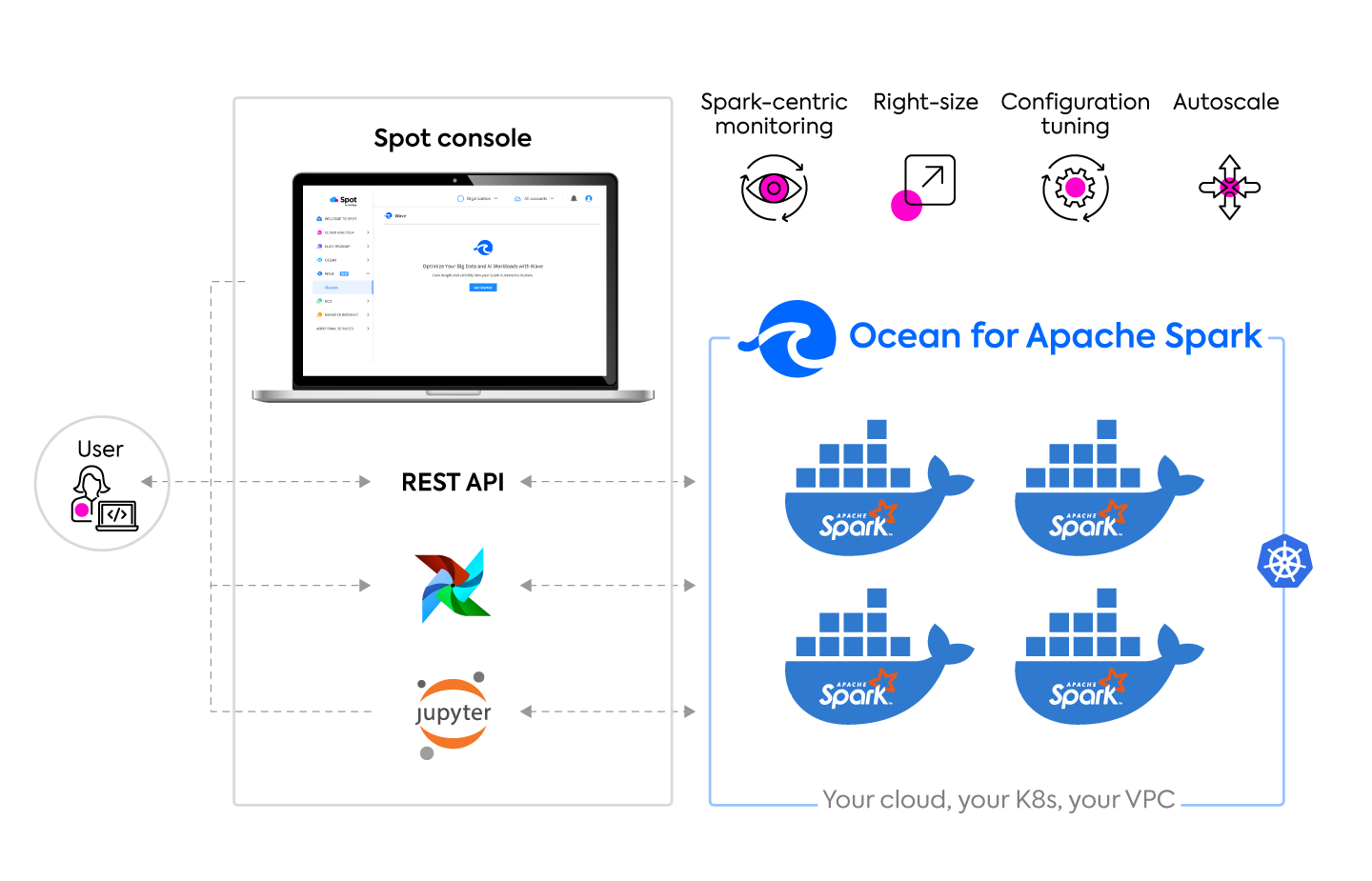
Ocean for Apache Spark is a managed cloud-native Spark service built on top of Ocean’s serverless engine, dedicated to making Apache Spark developer-friendly and cost effective. It gives data teams a serverless experience when working with Apache Spark and it’s deployed on a Kubernetes cluster inside your cloud account.
A Spark-centric observability layer
The Spot console within Ocean serverless infrastructure and Ocean for Apache Spark, gives you visibility over your Kubernetes clusters including its nodes, pods, scaling activity, and costs at the cluster-level.
Ocean for Apache Spark has an additional, Spark-centric observability layer that provides visibility over your Spark applications’ configurations, logs, Spark UI, and key metrics (CPU, Memory, Network and Disk I/O, Spark efficiency ratio, Shuffle). This information is available both while the app is running and after it is completed. Our open source Spark monitoring tool Delight is also natively integrated to help you troubleshoot job performance.
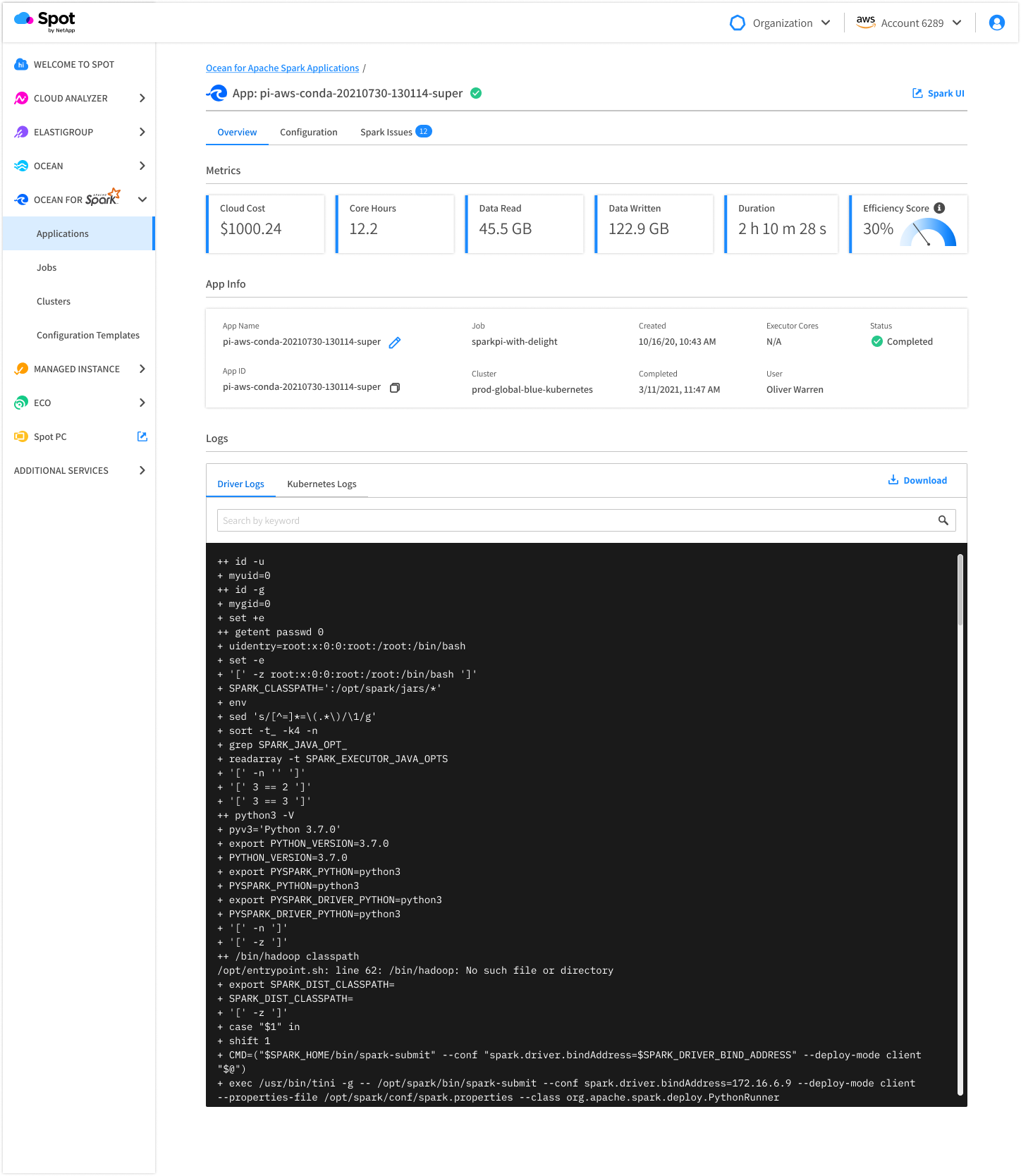
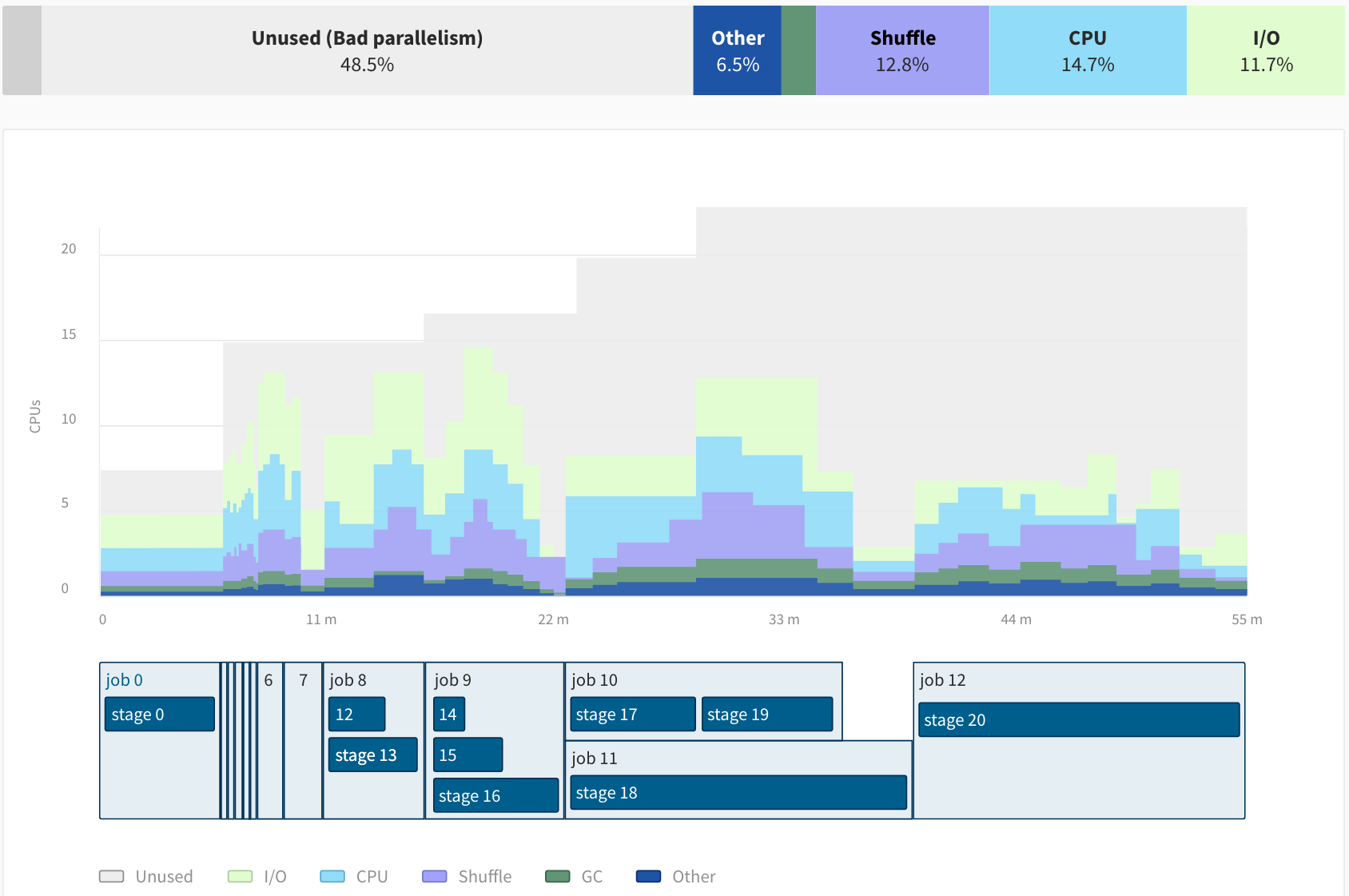
Spark jobs configuration optimization
Ocean for Apache Spark automatically tunes certain infrastructure parameters (e.g. container sizes, number of executors) and Spark configurations (e.g. I/O optimization, memory management, shuffle, Spark feature flags) based on the historical performances of previous executions of your Spark jobs.
You can track the evolution of each of your job’s performance, stability, costs, and other key metrics in a dedicated dashboard to make sure each Spark job is configured to minimize resource usage, while respecting a duration SLA.
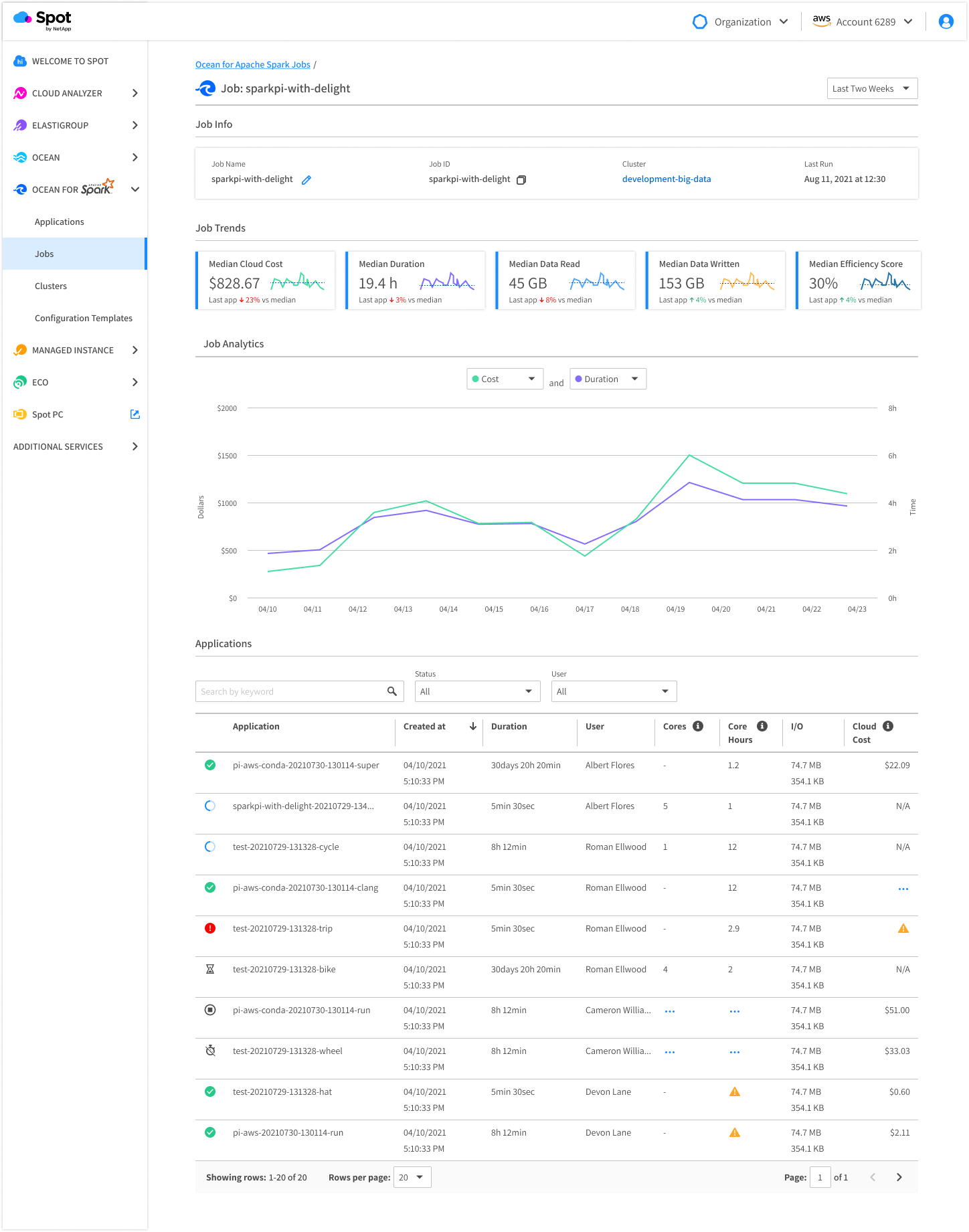
An automatically scaled and optimized infrastructure
Leveraging advanced AI algorithms, Ocean for Apache Spark automatically scales your cluster(s) based on the real-time load, choosing the highest-performance, lowest-cost instances (including spot nodes) matching your workload requirements. It gives you real-time visibility over the infrastructure and its costs, at the level of each Spark job and each Spark user.
The scheduling of pods (containers) onto nodes (instances) is optimized with a bin packing algorithm to maximize efficiency and reduce your costs. An automatic headroom can be configured to guarantee that your Spark applications can start instantaneously without waiting for new capacity to be provisioned.
An open and flexible architecture in your account
Ocean for Apache Spark benefits from the same flexible deployment model as Ocean: you can create a Kubernetes (e.g. EKS) cluster in your AWS account and in your VPC using the AWS console, the Spot console, a command-line utility, or tools like Terraform and Cloudformation. You can configure networking, security policies, and data access rules using your company’s best practices.
Ocean for Apache Spark comes built-in with integrations with popular data tools such as Jupyter notebooks (including JupyterHub), scheduling solutions (like Airflow), and connectors to popular data storage such as object stores, data warehouses, delta lakes, streaming sources, and more. The open source architecture we build upon makes it easy to integrate with the entire cloud native ecosystem, from logging & monitoring, to networking & security, CI/CD, and more.
How To Get Started
Ocean for Apache Spark is now available in preview for specific AWS customers. If you’re interested in getting started with a free POC, schedule an initial meeting with our team of Apache Spark Solutions Architects, so we can discuss your use case and help you with a successful onboarding of our platform.