 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Spark is one of the most widely-used compute tools for big data analytics. It excels at real-time batch and stream processing, and powers machine learning, AI, NLP and data analysis applications. Thanks to its in-memory processing capabilities, Spark has risen in popularity. As Spark usage increases, the older Hadoop stack is on the decline with its various limitations that make it harder for data teams to realize business outcomes. Hadoop is difficult to integrate with a broader enterprise technology stack and doesn’t offer flexibility beyond big data workloads. More so, Hadoop isn’t well-suited for real-time analytics – something Kubernetes excels at. Despite Hadoop’s decline in a world dominated by containers and Kubernetes, Spark remains highly relevant. In fact, the advent of Kubernetes has opened up a world of new opportunities to improve on Spark. That’s what we look at in this post – the journey from YARN to Kubernetes for managing Spark applications.
Spark on YARN
Spark uses two key components – a distributed file storage system, and a scheduler to manage workloads. Typically, Spark would be run with HDFS for storage, and with either YARN (Yet Another Resource Manager) or Mesos, two of the most common resource managers. Unlike Mesos which is an OS-level scheduler, YARN is an application-level scheduler. Thus far, YARN has been the preferred option as a scheduler for Spark to handle resource allocation when jobs are submitted. YARN was purpose built to be a resource scheduler for Hadoop jobs while Mesos takes a passive approach to scheduling. Mesos reports on available resources and expects the framework to choose whether to execute the job or not. YARN, on the other hand, is aware of available resources and actively assigns tasks to those resources.
How does YARN work?
A YARN cluster consists of many hosts, some of which are Master hosts, while most are Worker hosts. A ResourceManager handles resources at the cluster level, while a NodeManager manages resources at the individual host level. They keep track of the vcores and memory at both cluster and local host level.
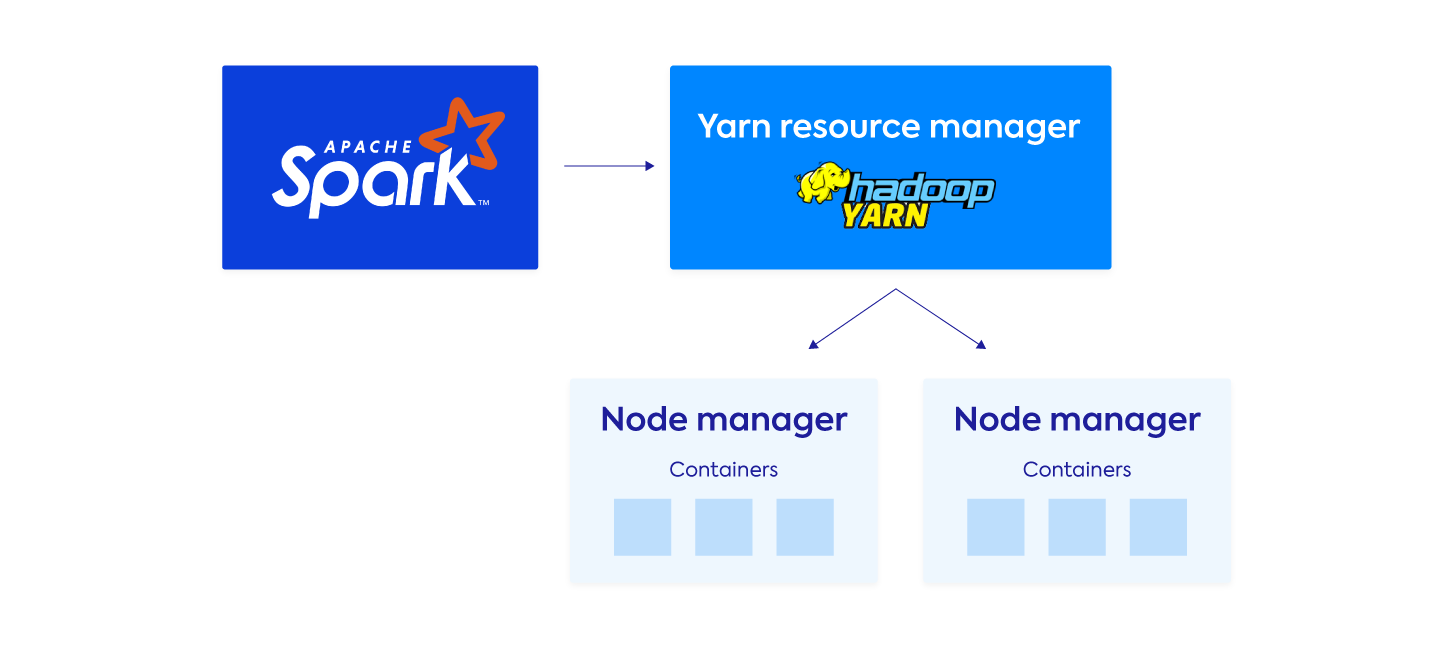
When an application like Spark runs on YARN, the ResourceManager and NodeManager assess the available resources on the cluster and allocate each container to a host. In this way, the key job of YARN is to manage resources and schedule tasks on a cluster.
Using YARN is far better than managing Spark as a standalone application. With the large data sets, numerous simultaneous workloads to run, and increasingly complex backend infrastructure, YARN makes it possible to run Spark at scale.
Limitations of YARN in the cloud
Where YARN falls short is in aspects such as version and dependency control, isolating jobs from each other, and optimal resource allocation. In order to run multiple workloads you need dedicated clusters for each workload type. According to Christopher Crosby of Google, YARN “clusters are complicated and have to use more components than are required for a job or model.” As a result YARN makes it difficult to manage tasks efficiently – the very purpose it was created for. YARN forces you to make compromises with highly demanding workloads like real-time processing. Furthermore, as data needs today are not just ‘big’, but also ‘micro’ and short-lived, YARN is unable to keep up with the demands of modern workloads.
Because YARN falls short with job isolation it requires setting up and tearing down the cluster for every new job that needs to be run. This incurs costs, is an error prone process, and wastes compute resources. These maintenance tasks take the focus away from the jobs to be run on Spark – which is the priority.
To make things worse, the talent pool of Spark infrastructure and platform is shrinking by the day as the workforce is mass migrating to the next wave in big data resource management – Kubernetes.
Kubernetes is replacing YARN
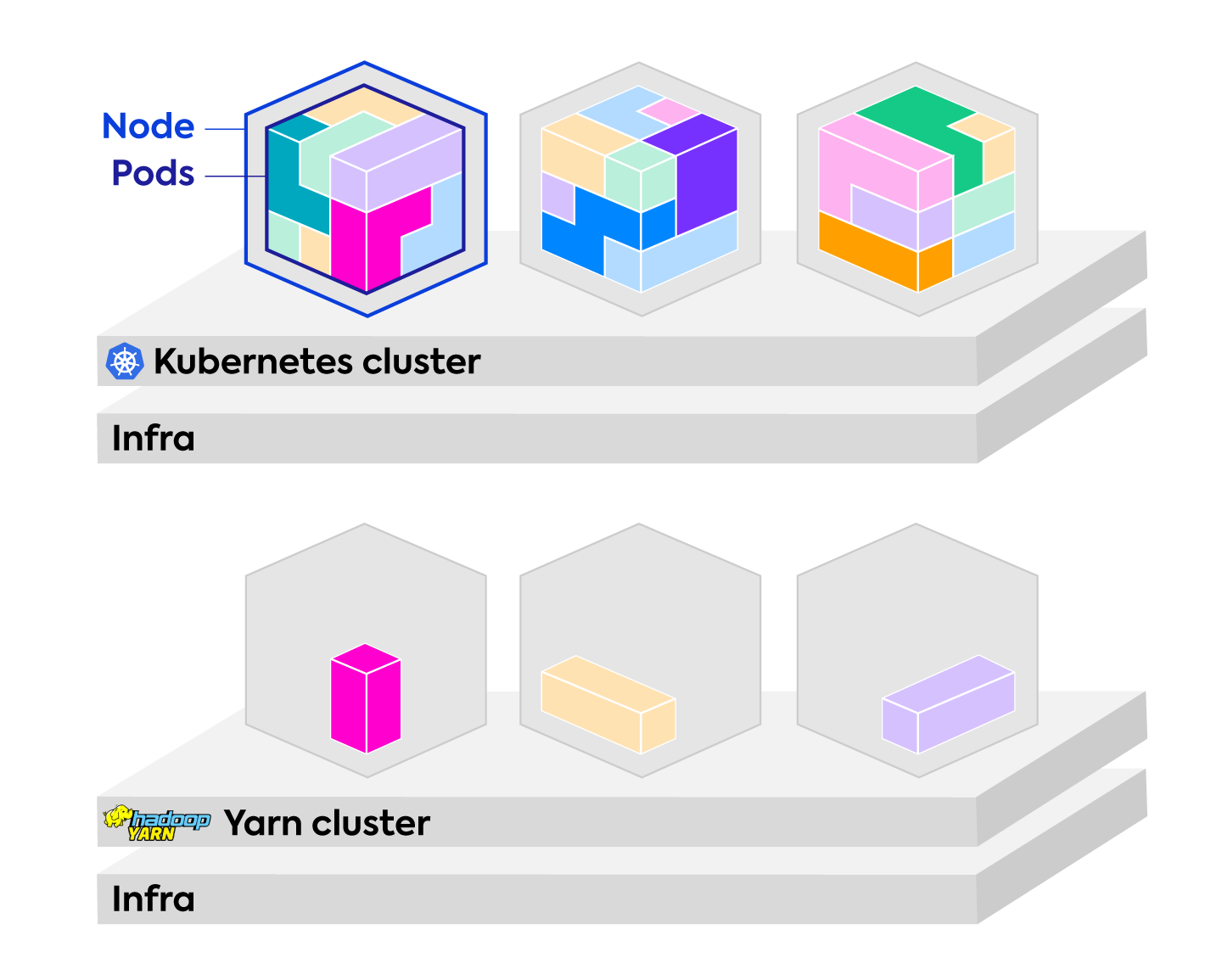
Kubernetes is known today as a container orchestration platform. As its usage continues to explode, Kubernetes is leaving no enterprise technology untouched – that includes Spark. There are many advantages to using Kubernetes to manage Spark. In the early days, the key reason used to be that it is easy to deploy Spark applications into existing Kubernetes infrastructure within an organization. This aligns the efforts of the various software delivery teams. This reason is fast-becoming eclipsed as Kubernetes’ many notable advantages tip the scales in its favor by a large margin.
Support for Kubernetes was experimental starting from version 2.3 in February 2018. However, since version 3.1 released in March 20201, support for Kubernetes has reached general availability. Previously, there were performance differences and reliability issues with Kubernetes, but now, Kubernetes has caught up or surpassed YARN on those fronts. In fact, Amazon ran comparison tests that reported a 5% time saving when using Kubernetes instead of YARN.
Benefits of Spark on Kubernetes
There are numerous advantages to running Spark on Kubernetes rather than YARN. Let’s look at the key benefits:
- Package all dependencies along with Spark applications in containers. This avoids dependency issues that are common with Spark.
- Kubernetes’ Resource Quota, and Namespaces bring greater control over how applications consume and share system resources.
- Swappable backed infrastructure means Spark applications are now portable across hybrid cloud setups.
- Kubernetes Role and ClusterRole features allow you to set fine-grained permissions for resources and organize these permissions based on API groups.
- Tag container images for version control which facilitates better auditing, and ability to rollback failed deployments.
- The Kubernetes ecosystem is blooming with powerful open source add-ons for management & monitoring. Prometheus for time-series data, Fluentd for log aggregation, and Grafana for data visualization are a few of the notable examples.
- GitOps allows you to manage infrastructure and application deployments declaratively. Flux and Argo are two leading GitOps tools that enable this.
- When it comes to set up, you can use Helm charts to install, manage, and version control packages and their dependencies.
This is already a long list of benefits, but the biggest reason to adopt Kubernetes over YARN is that it is the future of big data analytics. With support from every cloud vendor, and enterprise via the CNCF (Cloud Native Computing Foundation) Kubernetes is here to stay, and is revolutionizing how big data is analyzed.
For all its advantages, there are challenges with running Spark on Kubernetes that should not be ignored.
Challenges with Spark on Kubernetes
The first challenge to consider with Kubernetes for Spark is that it requires expertise that data teams lack. If your organization is already investing in Kubernetes operations across teams, this may not be an issue.
At the end of their insightful blog post on the topic of Kubernetes and Spark, Oleksandra Bovkun & Roman Ivanov remark that to fully operate this platform you need to have at least basic knowledge of Kubernetes, Helm, Docker and networking. If you want to avoid it you’ll probably try to bring another layer of abstraction to this platform by creating a UI, which calls Kubernetes API underneath.”
While Kubernetes excels at scaling applications, users still have to solve for ways to scale the underlying infrastructure. Spark applications can be dynamic and giving them infrastructure that is just as dynamic enables fast application deployment. Delivering flexible, resilient and efficient infrastructure for Kubernetes however requires significant time, expertise and resources.
Another key challenge is cost control while maintaining flexible infrastructure to support dynamic applications. Big data operations are expensive due to the large scale research, testing, modeling, and experimentation. If not kept in check, costs can spiral out of control. A primary way of enforcing cost control is to use spot instances. These instances are offered at significant discounts by cloud vendors. However, they don’t come with guaranteed availability and can be terminated at any time when the provider needs them back. Hence, a vital part of day 2 operations is to have a strategy to save costs while dealing with resilience associated with failing nodes. This requires meticulous planning and is labor intensive.
Kubernetes presents a great opportunity to revolutionize big data analytics with Spark. It decouples workloads from the infrastructure they are run on. It brings with it a completely new set of management and monitoring tooling for Spark. It marginally outperforms the incumbent YARN at processing speeds. It is no longer the experimental option, or a compromise – it is the future of big data analytics. Yet, to reap these benefits it takes a deep understanding of how Kubernetes works to both set up and maintain it.
Run serverless Spark on Kubernetes with Ocean for Apache Spark
With Ocean for Apache Spark, you can automate cloud infrastructure and application management for Apache Spark, in your cloud account and optimize for performance, reliability, and cost-efficiency. Learn more about Ocean for Apache Spark and get a demo today.