 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

Kubernetes and microservices have opened the door to smaller and more frequent releases, while DevOps CI/CD practices and tools have sped up software development and deployment processes. The dynamic nature of these cloud native architectures makes modern applications not just complex, but also difficult to monitor, find and fix problems. With many moving parts across the different stages of software delivery, it’s becoming harder to ensure that once in a production environment, a release will behave as expected. DevOps teams can spend hours trying to diagnose, troubleshoot and remediate issues and risks. This growing complexity and the maintenance efforts it creates has a direct impact on application performance, customer experience and company revenue, making continuous verification a critical next step for modern software delivery.
What is continuous verification?
Continuous verification is a discipline of proactive experimentation, implemented with tooling that verifies system behavior. It uses the outcomes to validate that the application is always following release standards and making decisions that improve the deployment process. Accomplishing this continuous improvement however, can be an overwhelming effort. The challenge put to continuous verification is to identify the hidden failure points and software degradations across a constantly changing system without slowing the release down.
What’s missing from continuous verification implementations?
Implementing continuous verification is the next phase to deploying production-ready applications faster, but there’s a gap in the way that it’s currently being implemented with existing tools.
Monitoring doesn’t equal verification
With more knowledge about the properties of complex systems, companies are trying to implement continuous verification. A common approach has been to piece together a patchwork of tooling for debugging and system exploration of unexpected patterns. This usually includes monitoring (Grafana, Lens, Cloudwatch, Kubernetes dashboard), real-time data collection and querying (Prometheus), logging (Coralogix, Logz, Elastic/ELK), and observability tools (Datadog, NewRelic).
In theory, having multiple sources of data that observe all the different components of your systems should give you enough confidence. In practice, verifying and approving releases is still manual, time-intensive and can be error-prone. Teams are reacting to hundreds, if not thousands, of fast-moving events from multiple tools and data sources. Each of these provides a separated snapshot of the workload at specific stages and gives a limited insight into its impact on the application as a whole.
Verification is siloed from the pipeline
When companies initially started to build continuous delivery pipelines, they often did so while considering continuous verification as an extension, not an integral part of the process. Adding tooling on top can deliver potentially significant insights about application performance, but doesn’t guarantee smooth or fast delivery. Instead of running an automatic event driven process, the release metadata is manually watched, integrated and analyzed outside of the pipeline to assess risk, resolve failures and approve promotion of releases. With these manual processes, it’s often not clear who owns verification. Is it the app developer who has to assess the risk of a build, the QA or tester who runs experiments against the release, or DevOps who ultimately decides when and if a deployment is safe to go into production?
Starting to improve continuous verification
To have control over how applications behave after changes, continuous verification shouldn’t be viewed as a manual extension of CI/CD or as a collection of tools executing external phases. It should be an integrated part of the software delivery lifecycle (‘SDLC’) as a well-defined process that drives CI/CD to take action based on the verification outputs. Building these processes into the SDLC can accelerate deployments by finding issues at a stage when they can be fixed quickly and easily, and before their impact is felt in production. As we learn more about what’s needed, we’re seeing a clearer picture of what well-implemented continuous verification should look like.
CD processes are a closed loop. Pipelines trigger testing, and outcomes are fed back into the pipeline. Necessary rollback actions are carried out automatically.
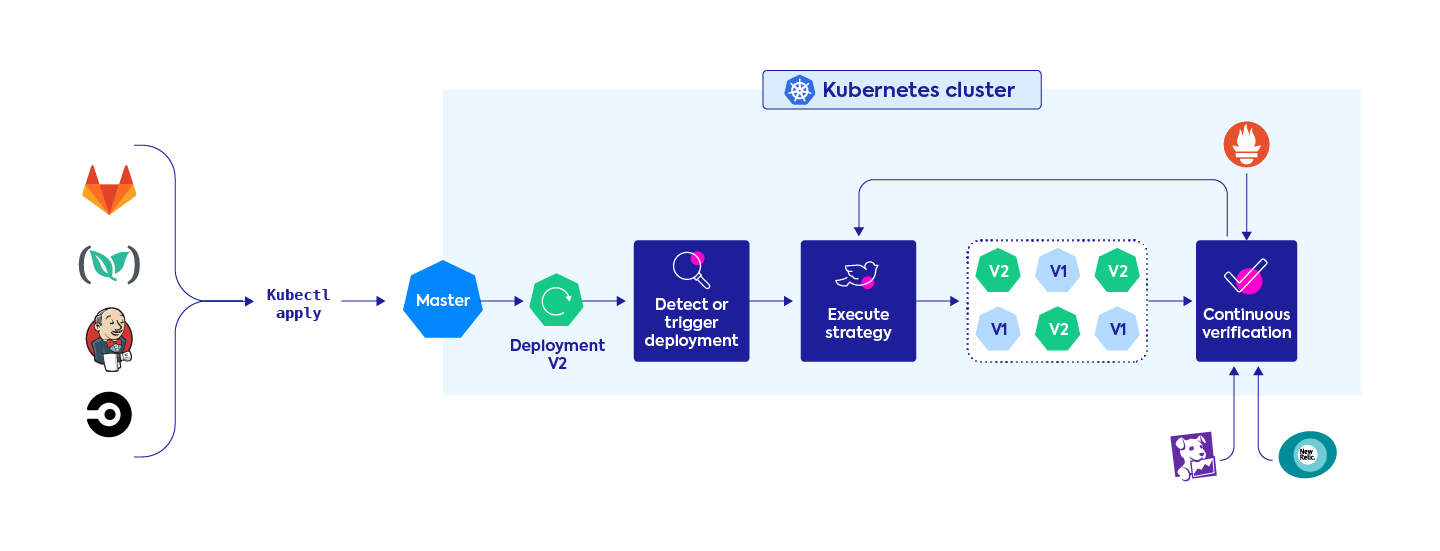
New deployments are compared to safe versions. Deviations from defined, reasonable performance baselines trigger alerts and rollbacks.
Optimized infrastructure aligned to workload requirements. Workloads automatically get the infrastructure they need to run with high performance and cost efficiency.
Dynamic verification of multiple microservices. Changes made to one microservice don’t negatively impact other services they are connected to.
Machine learning to improve CD process automation. Live and historical data is used to make better decisions that find and fix issues faster.
Ocean CD: Developing Continuous Verification as a critical phase of software continuous delivery
Recently announced and now in private preview, Ocean CD is a fully managed SaaS offering that provides end-to-end control and standardization for frequent deployment processes of Kubernetes applications at scale.
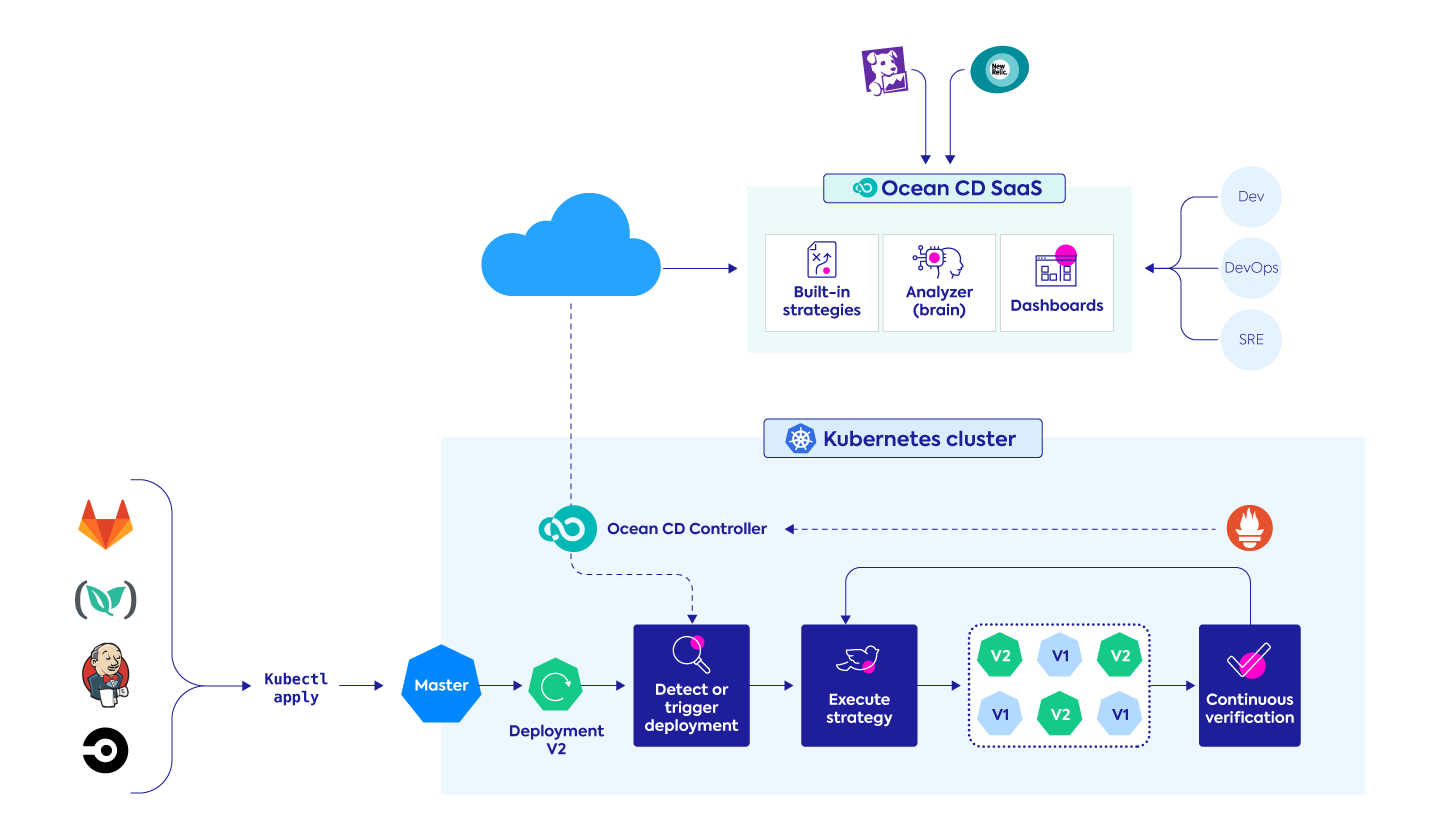
With Ocean CD, Spot has built a developer-centric, Kubernetes-native solution that will simplify release processes and provide full support of progressive delivery with automated deployment rollout and management. Continuous verification as an integrated part of the release process is a core principle of Ocean CD so you can scale faster and with confidence. To get started with Ocean CD, join our private preview.