 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

At Spotinst, we love to follow how people are implementing and using large-scale compute projects. We get even more excited when people make breakthroughs that simplify these and democratize their use. That is why when Jeremy Howard from fast.ai posted last month that “Anyone can train Imagenet in 18 minutes“, we wanted to see if there was any way we could help.
It just so happens that using AWS EC2 Spot capacity was discussed and eventually lead to this Stack Overflow question by Yaroslav Bulatov regarding spot instance startup time and warming EBS volumes.
Spot instances, unlike on-demand, cannot be stopped by the user. This puts Spot Instances, while 70-90% cheaper, at a disadvantage when starting and stopping compute jobs. To understand why, we must understand how an AWS instance is launched and how EBS storage is allocated.
When starting any EC2 Spot or on-demand instance, EC2 will pull an AMI from Amazon S3. When this happens, only the blocks that are needed are copied. In this state, the EBS volume is not “warm”. As the EBS volume needs to read more files, blocks are fetched from S3. Once all of the files or blocks are read, the volume is warm and there is no S3 penalty. At this point, an on-demand instance can be started and stopped repeatedly and the EBS volume maintains all blocks locally between instance state changes.
Since spot instances can only be terminated upon request, the AMI and any snapshots are forced to be re-fetched from S3. For an application that loads a large number of python libraries, this could mean seconds to minutes of latency as blocks are fetched from S3.
When you have the lofty goal of running ImageNet in under 18 minutes, seconds are valuable and the first latency hit to pull a block from S3 is unacceptable.
This leaves the question, does cost savings have to come with a speed penalty? There must be a better way!
Warm EBS and Spot Instances
To get instance speed out of EBS from spot instances on launch, one must forego the use of the root volume and instead rely on pre-provisioned volumes that are already warm. When a spot instance launches, the existing volume is mounted and retains any blocks read from previous use.
It is important to note that for each instance launched, a corresponding warm EBS volume must exist. For 16 p3.16xlarge instances, 16 existing EBS volumes are required. This is equivalent to keeping 16 stopped on-demand instances for future use. The only difference is that these volumes must be mapped to newly launched spot instances.
This pattern is great for data and applications that naturally live on secondary volumes, but what if we want fast loading for packages such as the fast.ai ImageNet or the AWS Deep Learning AMI?
The answer is chroot.
chroot
With chroot, scripts and SSH sessions can remap the root filesystem to a new directory. In this case that will be a snapshot of the of the fast.ai AMI.
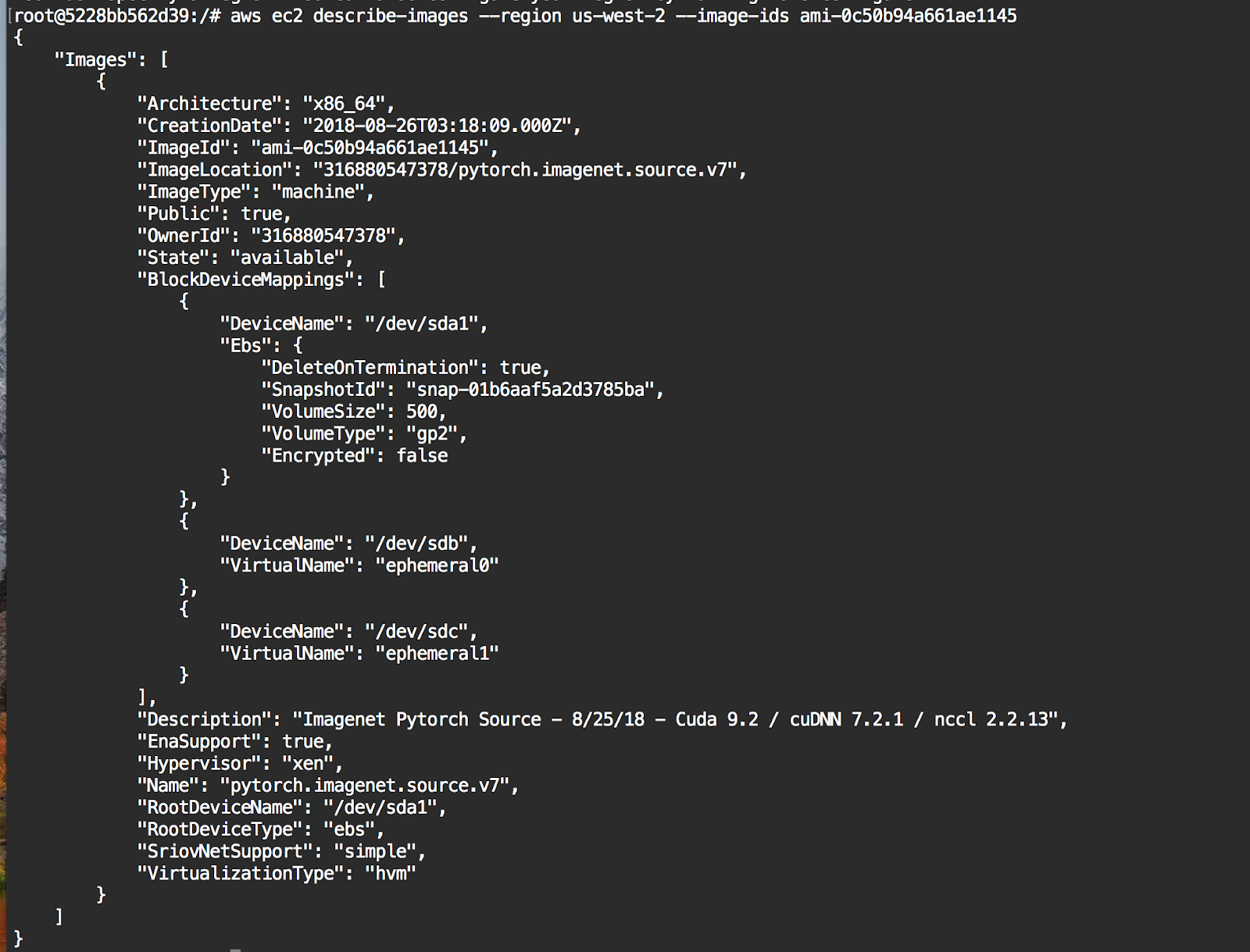
Every AWS AMI is stored on S3 and has a corresponding SnapshotId. This ID can be used to create a new volume, not just a root volume when launching an instance.
Finding the SnapshotId on the fast.ai AMI can be retrieved with the AWS CLI using the describe-images argument – look for it under BlockDeviceMappings.
Once the volume is mounted, the EC2 instance user data will be used to mount and configure the device for chroot. To mount the volume a combination of BlockDeviceMappings and AttachVolume are used depending on whether this is the first launch of the instance or not.
Block Device Mapping
Consecutive Runs
For consecutive EC2 instance launches, it is necessary to save the EBS volume ID that was created and use the AWS API to mount that volume after launching an instance. Use the attach volume API once the instance ID is available.
User Data
Now all new SSH sessions will be isolated to the mounted EBS volume which will retain warm blocks between attachments. Furthermore, when a user or script uses SSH to access the instance, the environment root will be on /dev/xvdf1. Device blocks will only be read from S3 once and retained for future use.
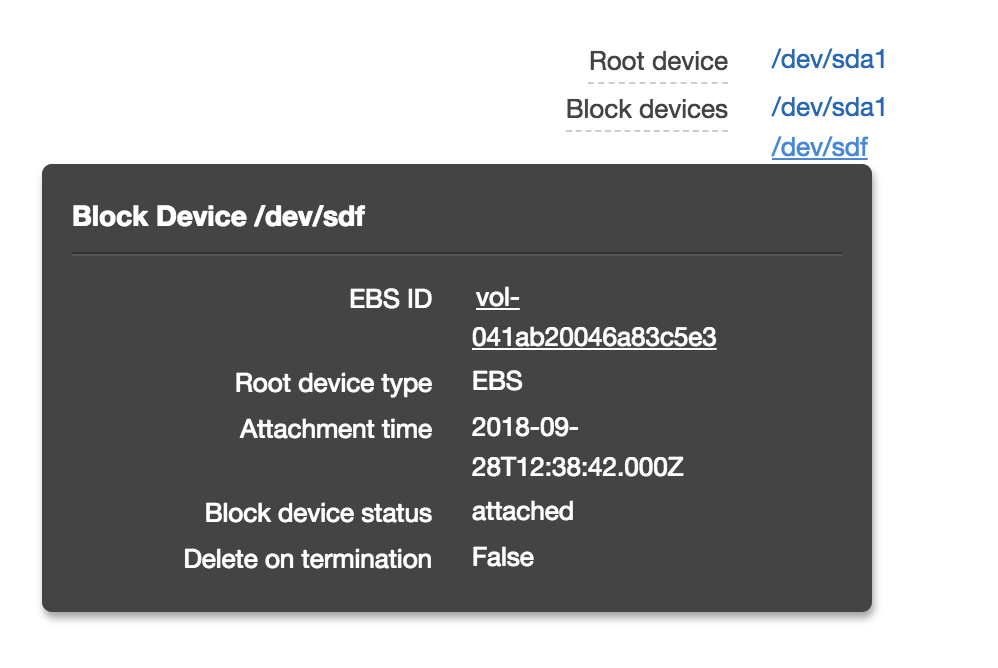
Stateful Elastigroups
At Spotinst, we specialize in running all types of workloads with Spot Instances, and Stateful EBS is one of them. The Elastigroup platform is able to create, track, and manage storage, network, and AMIs associated with a Spot Instance. When the instance is replaced or terminated, Spotinst ensures all of the stateful resources are migrated to a new spot request.
For Imagenet, a stateful Elastigroup is created for each processing node.
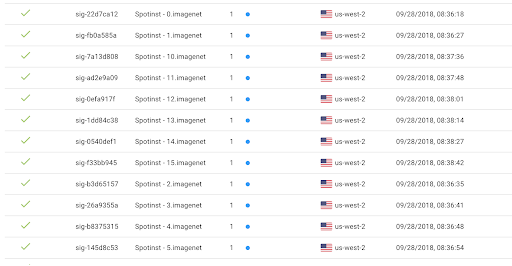
Each group contains a special Stateful ID that will manage network and storage of the spot request.
The image below shows hows the Spotinst platform will automatically retain and re-attach an EBS volume, in this case, the PyTorch fast.ai image.
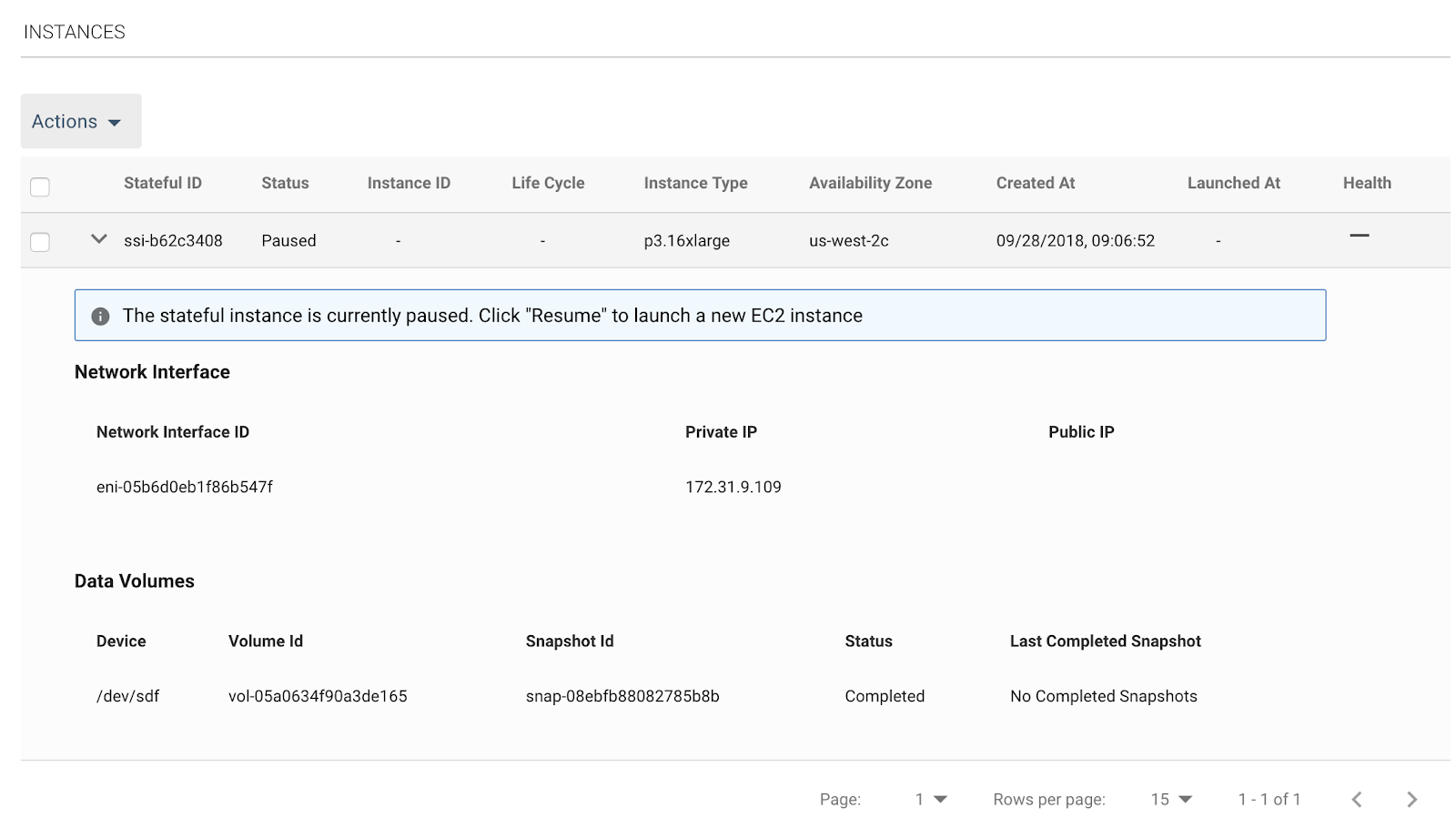
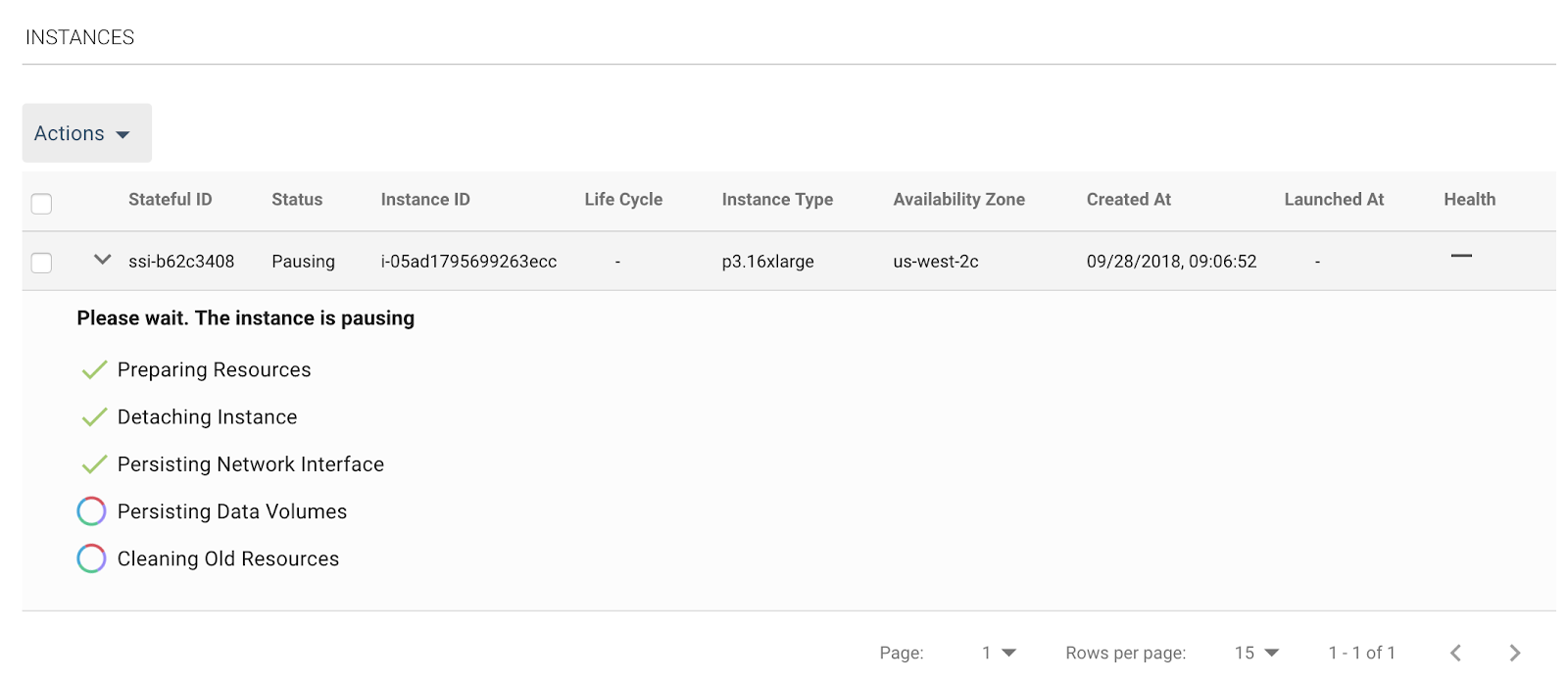
Finally, when no longer needed, Spotinst will ensure the instance is gracefully stopped and the state is saved and tracked.
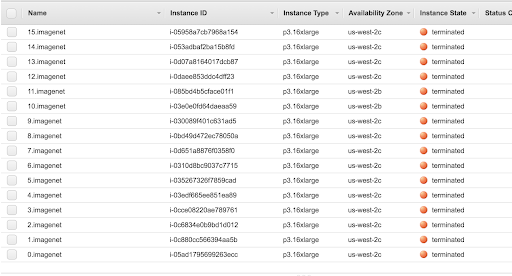
The instance table in the AWS EC2 Web Console verifies that we have not stopped, but terminated, all of the instances used to process ImageNet.
The next time Imagenet is processed, the warm EBS volumes will be used and eliminate any need to pull blocks from S3.
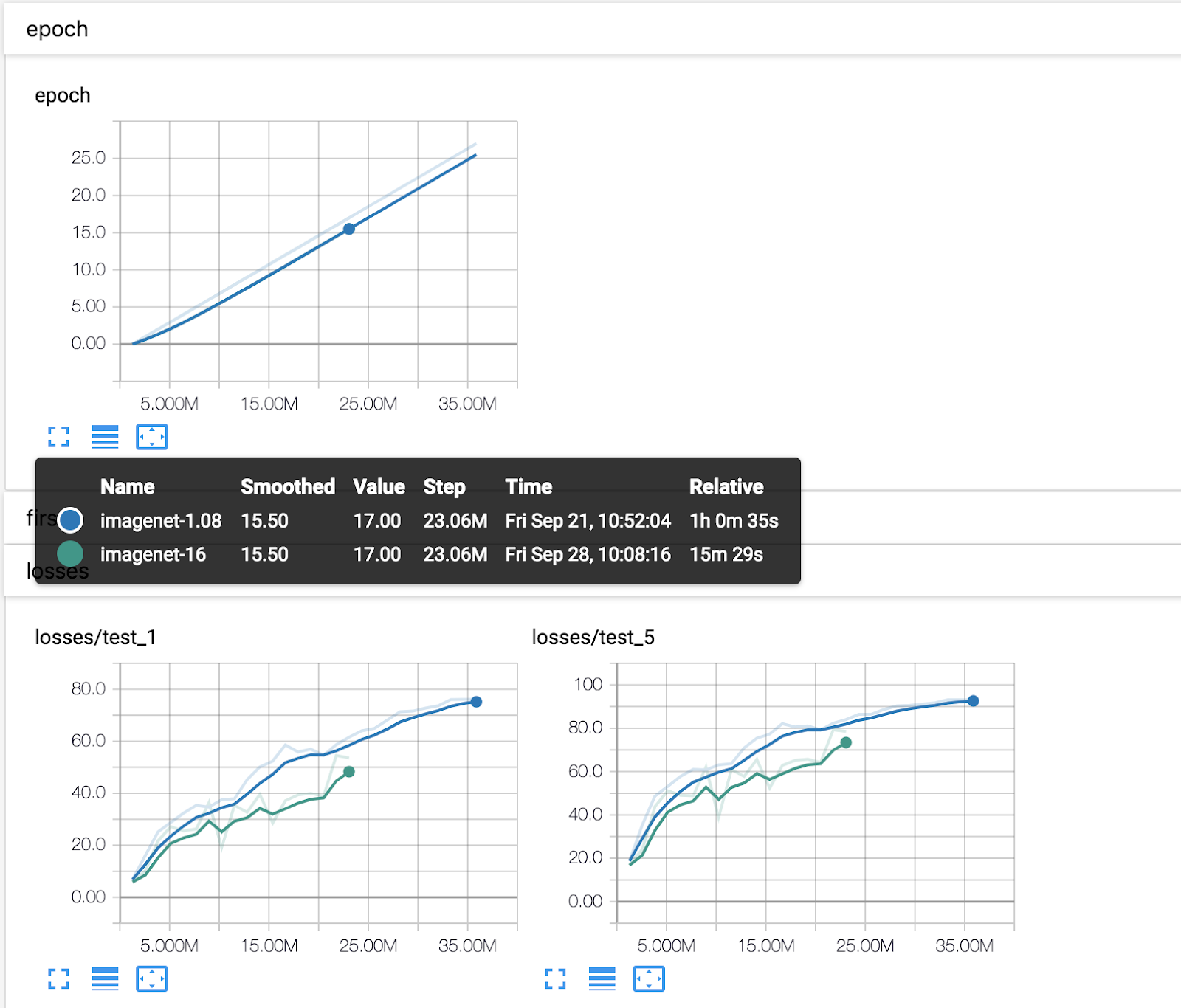
Tensorboard Graphs
Using the process described, we have been able to run ImageNet with the fast.ai PyTorch AMI from 1 to 16 p3.16xlarge instances. The following are graphs from a couple of the runs.
Save Money
Last but not least, save a lot of money. To process Imagenet fast, it takes large and expensive computing resources. With spot instances, it is possible to save 70% when running p3.16xlarge instances and still experience the benefits of warm EBS.
On-demand Linux p3.16xlarge pricing:

Spot instance Linux and Windows p3.16xlarge pricing:

We are continuing to follow up and work with Yaroslav to make this process faster and easily repeatable. Look for code and detailed how-tos coming soon!