 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps


One contributor to successful research is the ability to process and analyze enormous amounts of data. The speed of accessing information and performing computations is crucial to research institutions and organizations looking to innovate and lead in their domain. Yet to process and analyze all that data, researchers need high-performance computing resources that can handle these workloads.
What is high-performance computing?
High-performance computing (HPC) refers to a category of servers capable of processing and analyzing substantial amounts of data in a short amount of time. Usually, the HPC workloads require costly servers that provide enormous amounts of vCPU, GPU, and Memory resources. Therefore, HPC service is often more expensive, compared to other services.
Organizations using HPC range from banks and insurance companies all the way to research institutions and data-centric SaaS companies. Some popular HPC workloads or use cases are:
- Artificial intelligence/machine learning (AI/ML): Modeling, Predictions, MLOps
- Finance and insurance: Stock market trends, actuary
- Science and biomedicine: DNA sequencing, drug discovery
- Academic research and education
- Healthcare and life sciences: Modeling and forecasting
HPC Cloud Bursting
Some organizations are used to having stacks of powerful servers on premises to do the heavy lifting computations. These stacks require investment and maintenance, and they may be underused or queued with data scientists waiting to use them. Luckily for these organizations, cloud providers developed the capability known as “cloud bursting.” Cloud bursting enables customers to use cloud resources once their on-premises environments reach peak capacity.
Big data analytics is one such use case for cloud bursting. Tasks like 3D rendering and machine learning require more powerful compute resources, such as processor capacity and internal memory. With cloud bursting for Amazon Web Services, for example, users can manually or automatically provision public cloud services or take advantage of distributed load balancing to operate simultaneously in the cloud and the on-prem data center.
Like with any cloud service, utilizing high-performance computing and cloud bursting requires understanding of their capabilities and limitations.
Does the cloud make HPC cheaper?
Many companies turn to the public cloud where HPC machines can be “borrowed” ad-hoc. But reducing procurement costs for on-premises servers and lowering maintenance overhead doesn’t necessarily mean lower total cost of ownership (TCO) or fewer operational risks. Unsurprisingly, HPC instances can be very expensive to run given the spikes in usage they can incur.
To successfully run HPC workloads in the cloud, there are several key requirements:
- Availability and scalability of HPC resources
- Successful completion of job running time in the desired timeframe, without disruption
- Continuous monitoring of HPC jobs and analyzing the associated cloud costs
How to optimize HPC workloads in the public cloud
The leading hyperscalers provide some general guidelines for reducing idle times and overprovisioning:
In reality, implementing these recommendations is easier said than done. The savings they help achieve are nowhere near the administrative overhead they require from your already-overworked DevOps team, especially at scale.
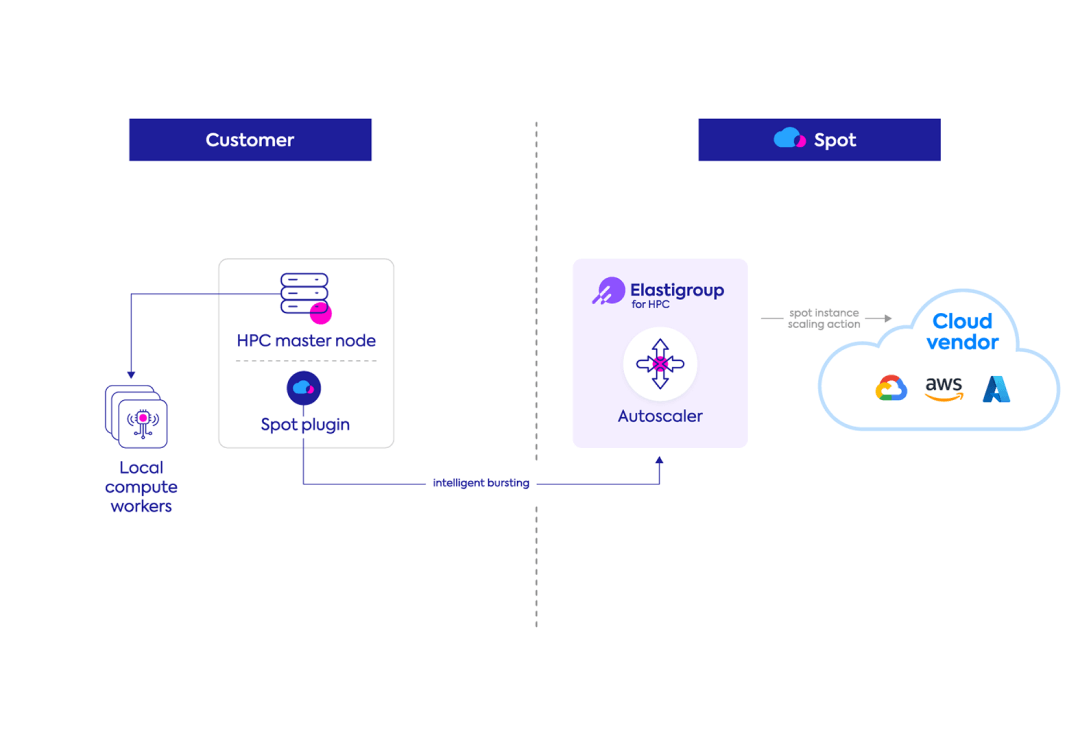
How to use spot instances for HPC
But what about using optimization methods that are not directly related to HPC, such as spot instances? This may be tricky, as spot instances can be taken away anytime with zero notice – a major risk for your most demanding workloads.
Spot Elastigroup for HPC was designed to provide a full, precise solution for the HPC use case. This capability converges and automates all the critical success factors for cloud HPC workloads: availability, scalability, minimum interruptions, continuous monitoring, and optimization.
Elastigroup utilizes the HPC resource connector from workload managers such as IBM LSF or Slurm to scale the HPC workload and burst in the cloud. An agent is installed on the HPC Master, and each job submission in the resource connector is automatically handled by Elastigroup’s engine.
Some highlights:
- High availability and minimized interruptions: Spot market intelligence picks the spot instance market with the highest probability to last through your desired processing interval
- Continuous monitoring and optimization: Dedicated GUI provides you with real-time insights and information about your HPC cluster spend and utilization
We know you want to understand how those work before you consider trying them. Let’s now dive into them, one by one.
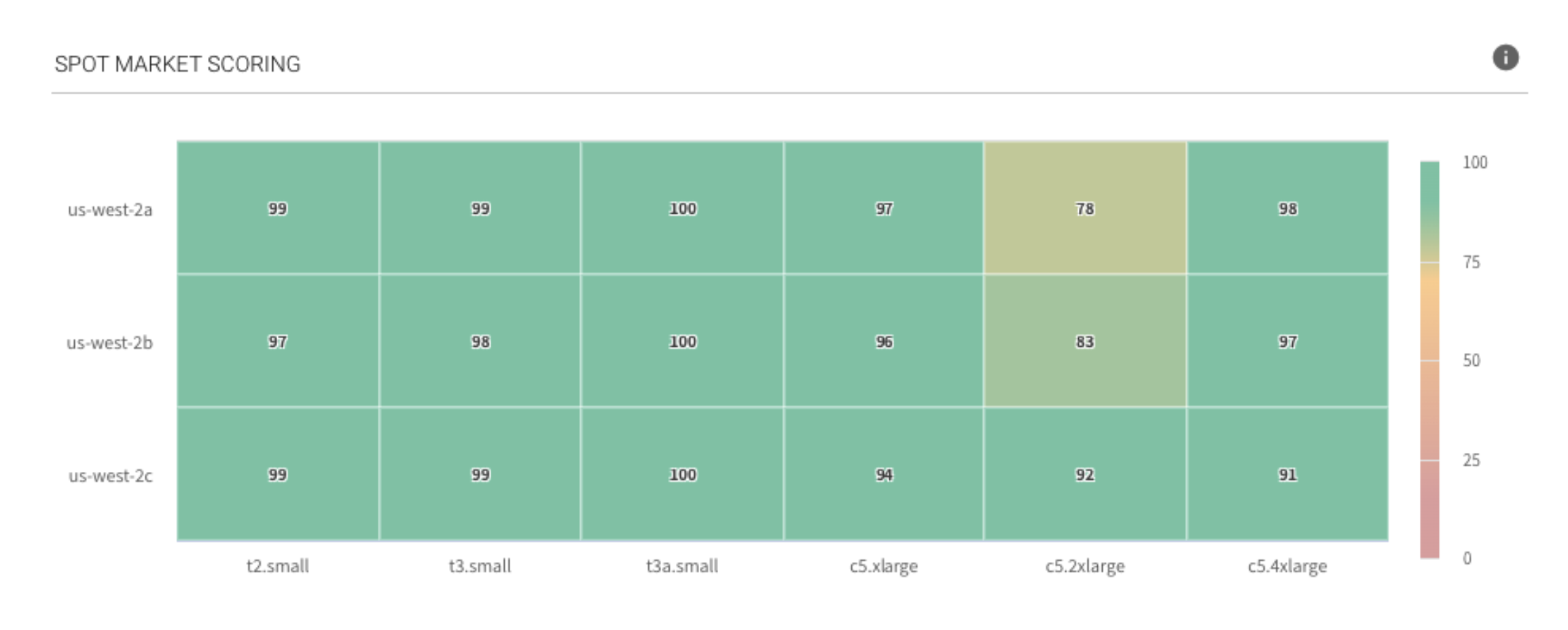
1. Spot market intelligence
Elastigroup’s market intelligence database contains pricing and availability data from the cloud provider’s spot markets. This data is anonymously recorded from Spot’s thousands of customer accounts through the years.
In this database, we apply an ML model that, for each spot instance market, provides a dynamic score based on:
- Your desired quantity of vCPU and Memory needed for your HPC jobs
- The probability of an instance being taken away within several timeframes
- Interruption rates
- Capacity trends
- Pricing
Using this model, Elastigroup launches the best spot markets in terms of pricing and availability based on workload requirements.
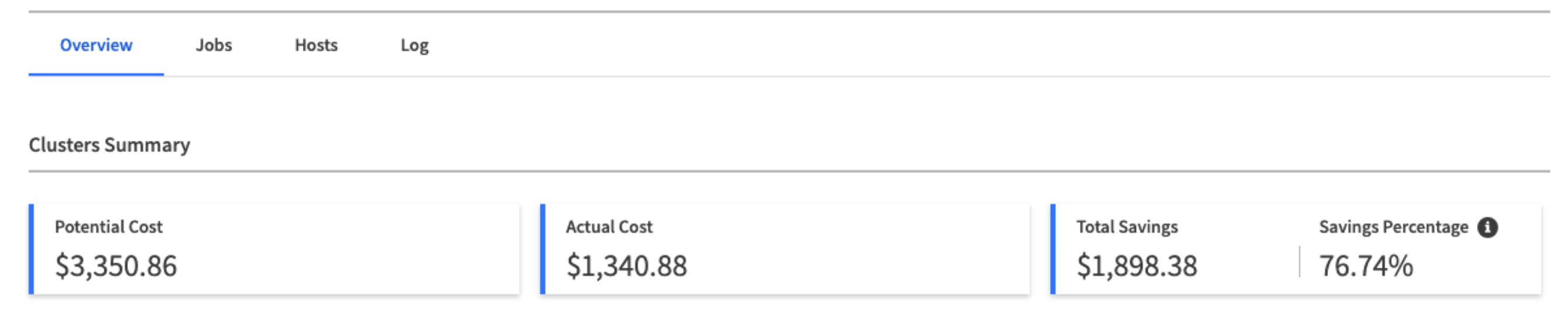
2. Monitoring with GUI
Elastigroup for HPC provides immediate visual insights and monitoring of your HPC workloads so you can make informed decisions.
Using the GUI, you can monitor:
1. Costs: The HPC cluster costs and forecast for next month. You can also review a single job and host costs.
2. Application status: Continuous visibility in real time for your job progress (Completed/Running/Pending status) for your immediate review.

3. Right sizing: Elastigroup monitors your requested jobs’ specifications versus actual resources utilization (vCPU and Memory) and suggests recommendations to optimize your total environment’s cost spend.

A complete flow of a user submitting an HPC job from the CLI and the way the job is added to the GUI. Following the specific job information, you can see the HPC cluster overview page while presenting high-level cost and cluster information.
Your HPC optimization and savings start with Spot Elastigroup
Relying on HPC doesn’t have to equal an astronomical TCO. By leveraging your cloud provider’s spot markets, you can get the compute power your HPC jobs need while staying on or below budget. However, you must be aware of the administrative effort of managing spot instances, especially if you operate HPC workloads often and at scale.
Until now there has been no real shortcut; no hyperscaler or third-party solution offered reliable access and fail-safe mechanisms for spot instances. Spot is the first to unlock the benefits of spot instances for HPC workloads, virtually risk-free: interruptions are minimized, continuity is automated, and budget is preserved.
Spin up your first HPC job free now – it only takes few minutes! Reach out to your Spot contact person for more information or request a demo.