 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

In modern cloud architecture applications are broken down into independent building blocks usually as microservices. These microservices allow teams to be more agile and deploy faster. Microservices form distributed systems in which communication between them is critical in order to create the unified system. A good practice for such communication is to implement an event-driven architecture.
What is event driven architecture?
Event-driven architecture is a software design pattern in which components are built to react upon events. One component will produce an event whereby a second reacts, as opposed to a request-driven architecture where a component initiates a request received from another component. In an event-driven architecture, the first component will produce the event which the consumer will react to. This approach limits coupling between components; one is not aware of the other. Event-driven architecture will also allow the distribution of events to many subscribers.
Event-driven architecture is typically implemented in one of two ways:
Point-to-point messaging
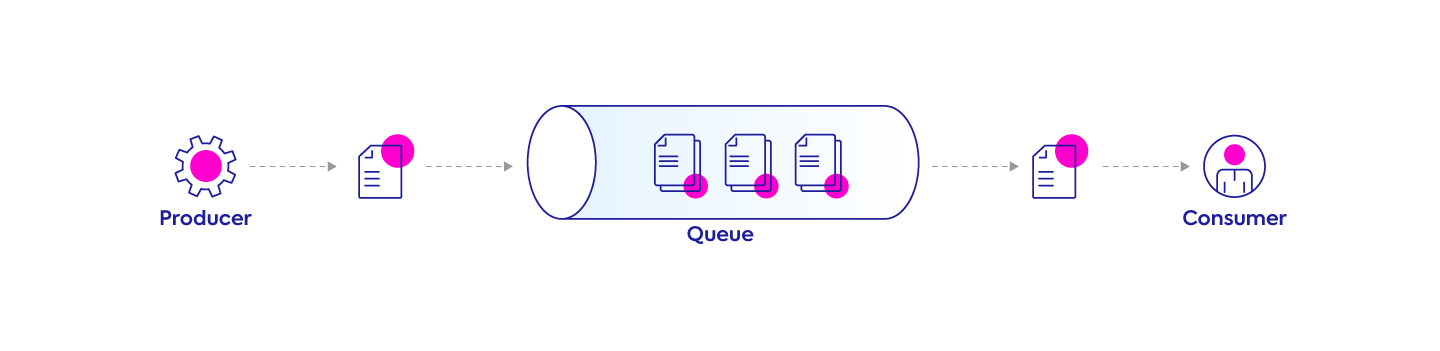
Involves two main components, a producer and a consumer. The producer is responsible for posting messages to the queue while the consumer takes those messages and acts upon them. Each message is processed only once with only one consumer executing the specific task.
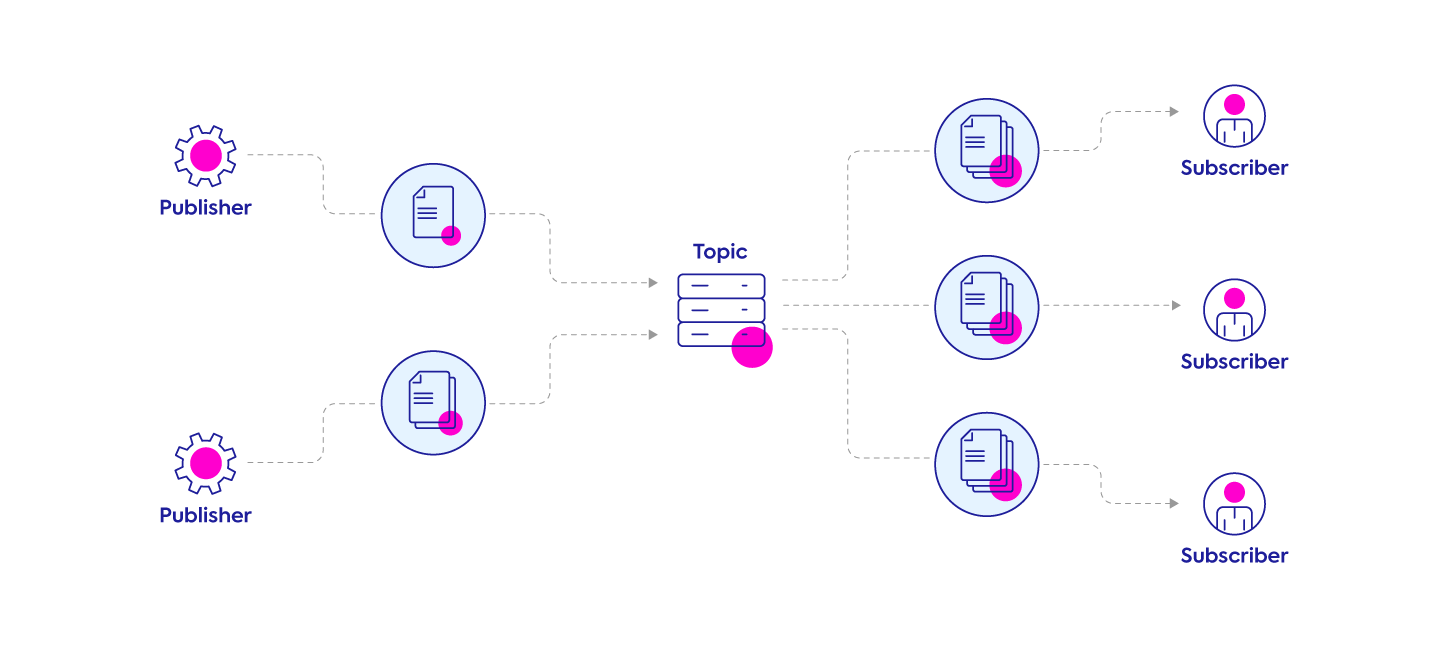
Publish/Subscribe
The Publish/Subscribe model allows messages to be broadcast to different parts of a system. The publisher will post events to the topic while all subscribers are notified about the event. This approach is used when multiple components need to be alerted when an event occurs.
As both event-driven architectures and Kubernetes environments become more common and more complex, it is crucial to have a solution that will allow your infrastructure to scale based on your message queue or event source length. Kubernetes Horizontal Pod Autoscaler (HPA) scales resources based on a provided metric (usually CPU or Memory utilization), however it does not have native support for event-sources. As such, there is a delay in scale-up of new Pods while the event source gets populated with events. This can be solved using custom metrics with the HPA or we can use the Kubernetes-based Event-Driven Auto-Scaler ( KEDA).
Introducing KEDA
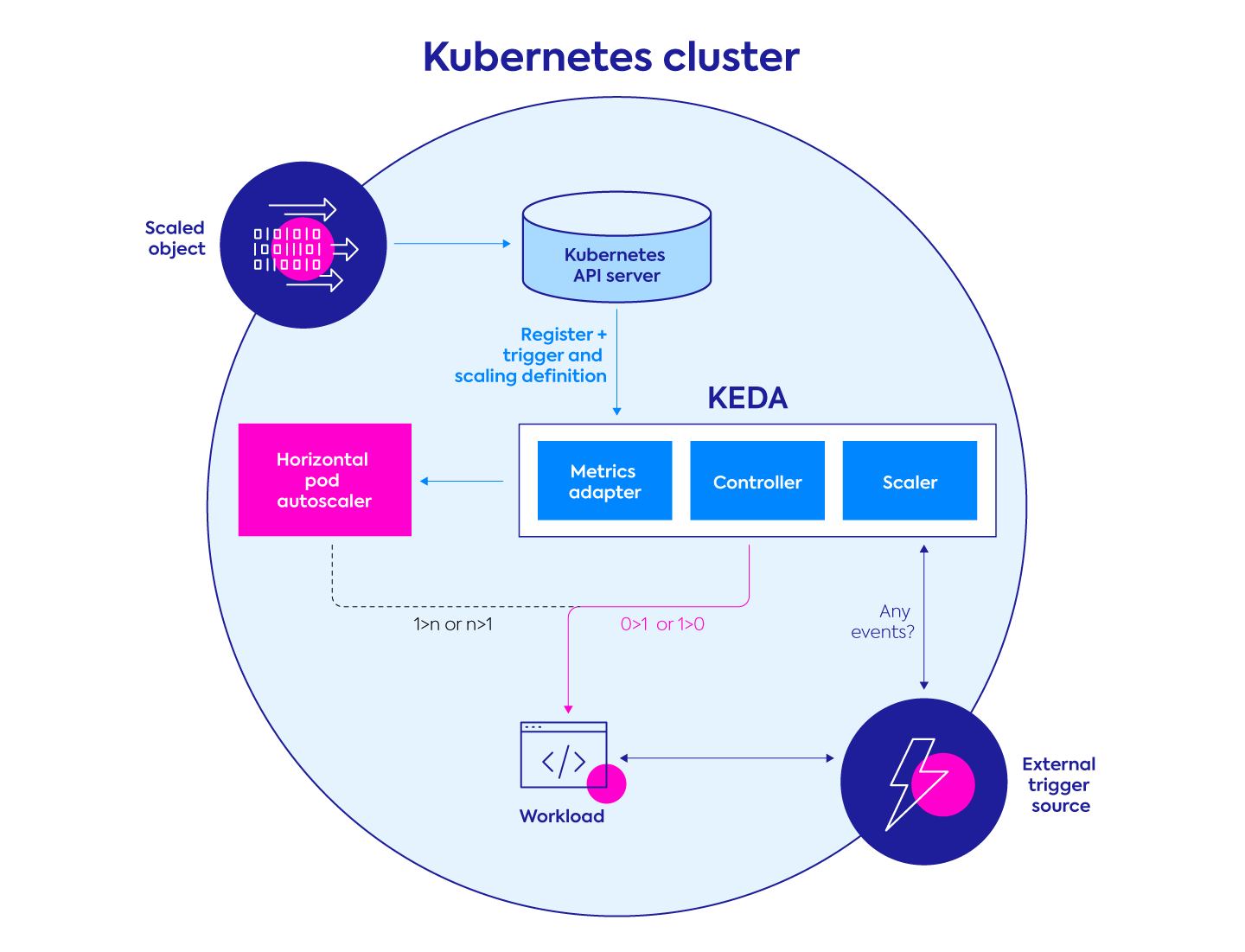
KEDA is a single-purpose, lightweight, open-source component, built to activate a Kubernetes Deployment(s) based on events from various sources. KEDA works alongside standard Kubernetes components like the HPA and can extend its functionalities by allowing it to scale according to the number of events in the event source.
How does it work?
KEDA is supported from Kubernetes version 1.16 and above.
KEDA integrates with multiple Scalers (event sources) and uses Custom Resources (CRDs) to define the required/desired scaling behavior and parameters. These custom resources enable you to map an event source (and it’s authentication) to a Deployment, StatefulSet, custom resource, or Job for scaling purposes.
While installing KEDA, the following CRDs are also created as written in the KEDA documentation:
- ScaledObjects (scaledobjects.keda.sh) define the relation between an event source to a specific workload resource (i.e. Deployment, StatefulSet, custom resource for scaling)
- ScaledJobs (scaledjobs.keda.sh) represent the mapping between an event source and Kubernetes Job.
- ScaledObjects/ScaledJobs may also reference TriggerAuthentication (triggerauthentications.keda.sh) or ClusterTriggerAuthentication (clustertriggerauthentications.keda.sh) which contains the authentication configuration or secrets to monitor the event source.
KEDA monitors event sources defined in the ScaledObjects/ScaledJobs and will feed the HPA with the Pods that are needed at a given moment based on the events in the source. These Pods actively pull items from the event source while KEDA continuously monitors it, and will adapt the number of Pods accordingly. Once the event source is empty, KEDA will downscale resources to 0.
KEDA also exposes metrics to Prometheus so you can easily scrape the KEDA metrics to Prometheus and monitor them accordingly.
While using KEDA, your application should implement the communication with the event-source (e.g consume/subscribe, etc).
Let’s See It In Action
For this example, I’m going to use one of the official KEDA examples – https://github.com/kedacore/sample-go-rabbitmq.
I have a cluster deployed on Azure using AKS (this can also be done using any other Kubernetes flavor, managed or unmanaged).
I’m going to use Helm (Helm installation guide) to deploy KEDA.
I’ll start by installing the KEDA Helm chart:
helm repo add kedacore https://kedacore.github.io/charts helm repo update kubectl create namespace keda helm install keda kedacore/keda --version 2.0.0 --namespace keda
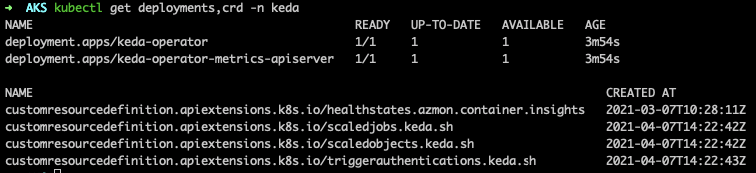
I should now have KEDA available on my cluster. Running the following command will assist with verifying that:
kubectl get deploy,crd -n keda
The output is expected to be similar to :
Next, let’s install Rabbit MQ
kubectl get pods
![]()
Now that we have KEDA deployed and our queue ready, we can set up the ScaledObject
First, let’s clone the repository with our example:
git clone https://github.com/kedacore/sample-go-rabbitmq cd sample-go-rabbitmq
Deploying the consumer
This consumer is set to consume one message per instance, sleep for 1 second, and then acknowledge completion of the message.
The ScaledObject included in the deployment is set to scale to a minimum of 0 replicas on no events, and up to a maximum of 30 replicas on heavy events (optimizing for a queue length of 5 messages per replica). After 30 seconds of no events, the replicas will be scaled down (cool down period). These settings can be changed on the ScaledObject as needed.
kubectl apply -f deploy/deploy-consumer.yaml
The following Kubernetes resources will be created:

kubectl get deploy
![]()
You should see that you have a deployment with 0 replicas.
Publishing messages to the queue
The following job will publish 300 messages to the “hello” queue the deployment is listening to. As the queue builds up, KEDA will help the HPA add more and more pods until the queue is drained after about 2 minutes and up to 30 concurrent pods. You can modify the exact number of published messages in the deploy-publisher-job.yaml file.
kubectl apply -f deploy/deploy-publisher-job.yaml kubectl get deploy -w
You will see the deployment scales and we see that our deployment scales in/out based on the number of events present in our queue. In order to validate that all of those pods have enough compute resources to run on, you should implement an autoscaling mechanism.
Long Running Executors / Scale-down Handling
Another consideration is how to handle long running executions. Imagine KEDA triggers a scale-up of a new Pod that takes several hours to execute. At some point, HPA will need to make a decision about scaling down some of these Pods. Without any specific configurations, this decision is made randomly, and you risk scaling down a Pod that hasn’t finished its work yet.
There are two main ways to handle this:
Leverage the container lifecycle
Kubernetes provides several lifecycle hooks that could be leveraged to delay termination of Pods.
Run as Jobs
When you use the ScaledJob CRD, a single Kubernetes Job will be deployed for each event. With this method, a single event is pulled from the event source, processed to completion and terminated.
Expanding KEDA functionalities using Spot Ocean
While running Kubernetes clusters in the cloud, you’d want to be as efficient as possible in allocating your resources (nodes), autoscaling of the infrastructure is required, and you’d want it to be done while maintaining high availability at low costs. Cluster-autoscaler is one way to achieve this, but it often comes with additional management and architectural efforts.
Alternatively, pairing KEDA with Spot Ocean, Spot’s serverless container engine, brings automation and optimization to these processes. KEDA focuses on adding and removing Pods to the cluster based on the event source length, while Ocean handles infrastructure provisioning by continuously optimizing the resources associated with your Kubernetes cluster.
Ocean is a container driven autoscaler that natively uses cloud excess capacity (AWS Spot instances, GCP Preemptible VMs, and Azure Spot VMs) to run your workloads reliably and efficiently. AI-driven predictive algorithms monitor the spot markets and identify risk of interruption, proactively replacing at-risk instances or falling back to on-demand if there is no excess capacity available. It’ll also add diversification in terms of machine types used in the cluster This reduces the risk of capacity loss and increases the reliability of running on excess capacity, helping to reduce the costs associated with your Kubernetes data plane dramatically. For AWS users leveraging Reserved Instances or Savings Plans, Ocean can prioritize vacant reservations before spot or on-demand.
Other core features in Ocean enable even faster, more efficient scaling. Ocean’s built-in headroom mechanism allows the rapid scale of new Pods without the need to wait for a new instance to launch. Headroom can be configured manually, and can also be configured to be automatic. This will set the headroom capacity as a percentage of the total cluster resources, and will increase or decrease as the cluster changes.
Spot Ocean’s compatibility with KEDA is just one of many ways that Ocean extends the power of Kubernetes to give your cloud infrastructure better efficiency, affordability and performance. To learn more about Spot Ocean, visit our product page.