 Microsoft Azure
Microsoft Azure Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) How to Operationalize FinOps
How to Operationalize FinOps

As an open-source, distributed, general-purpose cluster-computing framework, Apache Spark is popular for machine learning, data processing, ETL, and data streaming.
While Spark manages the scheduling and processing needed for big data workloads and applications, it requires resources like vCPUs and memory to run on.
These resources can either be a group of VMs that are configured and installed to act as a Spark cluster or as is becoming increasingly common, use Kubernetes pods that will act as the underlying infrastructure for the Spark cluster.
In this post, we will be focusing on how to run Apache Spark on Kubernetes without having to handle the nitty-gritty details of infrastructure management.
Advantages of running Apache Spark on Kubernetes
Since Spark 2.3, using Kubernetes has allowed data scientists and engineers to enjoy the many benefits of containers such as portability, consistent performance and faster scaling along with a built-in mechanism for servicing burstable workloads/applications during peaks, scheduling and placement of applications on appropriate nodes, managing applications in a declarative way and more.
In the context of a Spark workload this provides the following advantages:
- Reduced cluster waste:
- Only the exact resources needed by the workload/application are used
- Cluster only runs when needed and shuts down when there’s no workload running
- Each Spark workload gets its own “piece” of infrastructure (which is scaled down when the process ends). This reduces the possibility of several workloads racing over the same resources
- Fast cluster spin-up time due to the immediate scaling of containers and Kubernetes
While this sounds great, we’re still missing one key ingredient. For Kubernetes to manage all the different workloads, Spark or otherwise, it needs some underlying compute infrastructure. With most workloads being quite dynamic, scaling instances up and down will require some form of Kubernetes infrastructure autoscaling. Of course one can take a do-it-yourself approach using the open-source Cluster-Autoscaler. But this requires significant configuration and ongoing management of Cluster-Autoscaler and all associated components (e.g. auto scaling groups) which might be a heavy burden for some teams.
Let’s take a look at a turn-key alternative and then how it supports Spark workloads.
The serverless experience for Kubernetes infrastructure
Ocean by Spot is an infrastructure automation and optimization solution for containers in the cloud (working with EKS, GKE, AKS, ECS and other orchestration options). It continuously monitors and optimizes infrastructure to meet containers’ needs, ensuring the best pricing, lifecycle, performance, and availability.
Some of the key benefits of Ocean include:
- Pod-driven autoscaling that out-of-the-box, takes into consideration Pod requirements, and rapidly spins up (or down), the relevant nodes so your workloads always will have sufficient resources. Additionally, intelligent bin-packing of Pods onto available nodes, drives optimal cluster utilization and cost reduction.
- Container-level cost allocation and accountability that provides insight into team, project or application costs with drill-down by namespaces, deployments, resources, labels, annotations and other container-related entities
- Resource right-sizing that is based on real-time measurement of your pods’ CPU and Memory consumption enabling you to right-size your container requirements for cost-efficient cluster deployments. This creates a positive cycle as pods are rightsized, nodes can then be downsized for greater utilization and cost efficiency.
- Immediate scaling for high priority workloads with Ocean’s “headroom”, a customizable buffer of extra CPU and Memory for every cluster, ensuring your important workloads will immediately run whenever needed.
- Dramatic cost optimization that is achieved by Ocean running containerized workloads on spot instances with an enterprise-level SLA for availability.
Hands-free Kubernetes infrastructure scaling for all Apache Spark workloads
In the following sections, I’ll demonstrate how Ocean scaling works with two Spark workloads, each running via one of the following methods on Kubernetes:
- Spark operator method, originally developed by GCP and maintained by the community, introduces a new set of CRDs into the Kubernetes API-SERVER, allowing users to manage spark workloads in a declarative way (the same way Kubernetes Deployments, StatefulSets, and other objects are managed).
- Spark-submit method (i.e. Kubernetes job with Spark container image), where a Kubernetes Job object will run the Spark container. The Spark container will then communicate with the API-SERVER service inside the cluster and use the spark-submit tool to provision the pods needed for the workloads as well as running the workload itself.
I’ll run the two workloads in parallel to show that it doesn’t matter which workload triggered the scale-up and that Ocean automatically ensures that the workloads have the right amount of resources needed to run.
At the end of the process the 2 workloads will end, and their respective pods will be terminated. This will leave the cluster in an over-provisioned state. Ocean will then automatically scale down the infrastructure resources (i.e. the K8s worker nodes). Additionally, Ocean uses a pod rescheduling simulation to understand which nodes can be automatically drained and terminated while keeping other worker nodes with sufficient resources to support the remaining pods.
Prerequisites
To replicate what I’ve done here, you will need the following:
- AWS account
- Spot.io account connected to an AWS account
- EKS cluster running with infrastructure managed by Ocean
(Ocean can be setup easily using eksctl)
eksctl create cluster \ --name prod \ --nodegroup-name standard-workers \ --spot-ocean
Spark-Submit running method
For the spark-submit method, see this great blog by AWS that provides an example of how to run Apache Spark processing workload on EKS. The blog requires you to create:
- Spark Docker image to be run as a JOB object in K8s
- Spark application Docker image to be run by the spark-submit command
- S3 bucket for the results with permissions from the pod/node to write to the S3 bucket
The Kubernetes Job definition is taken from the GitHub repository – https://github.com/aws-samples/amazon-eks-apache-spark-etl-sample/tree/master/example/kubernetes.
In the “spark-job.yaml” file pay attention to the following replacements that need to be made:
- Line 10 – “<REPO_NAME>/spark:v2.4.4” should be replaced with the one built by the “docker build –target=spark -t <REPO_NAME>/spark:v2.4.4 .” command
- Line 15 – verify the address of the Kubernetes API-SERVER service ip with the following command:
kubectl -n default get service kubernetes -o jsonpath=”{.spec.clusterIP}” - Line 23 – replace the <REPO_NAME>/<IMAGE_NAME>:<TAG> it with the spark application image built with the command docker build -t <REPO_NAME>/<IMAGE_NAME>:v1.0 .
- Line 31 – replace the <YOUR_S3_BUCKET> with the name of the s3 bucket that will contain the process results
Spark-Operator deployment
For the Spark Operator deployment method use the Spark-Operator helm chart. You can install the Spark-Operator with the following commands:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator --set sparkJobNamespace=default
The “sparkJobNamespace” parameter tells the operator which namespace to watch for “SparkApplication” objects managed by the operator.
In order to verify that the Spark-Operator is running, run the following command, and verify its output:
kubectl get pods -n spark-operator NAME READY STATUS RESTARTS AGE spark-operator-sparkoperator-7dbf74fd69-hsfnn 1/1 Running 0 154m
The Spark workload that will be run at this part will be the “spark-pi” which calculates the value of Pi.
Cluster size before scaling
For this demonstration, I’ve used an EKS cluster with Ocean managing its infrastructure. Below is a screenshot from the Ocean console showing that the initial cluster size was 3 instances (I had some other workloads running on that cluster) with CPU allocation at 73%.
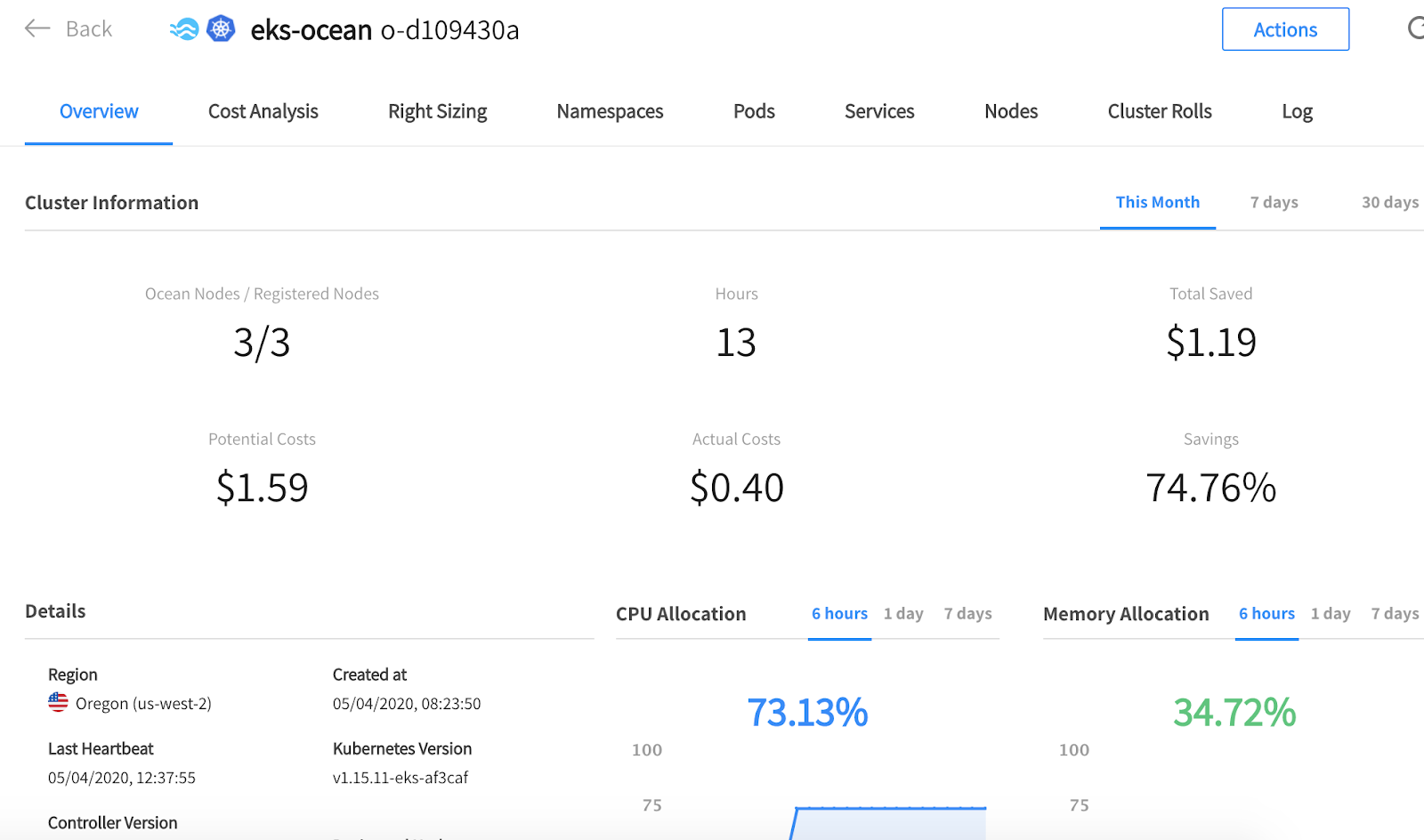
The high CPU allocation of 73% means that there’s almost no waste in our cluster. This is due to Ocean’s autoscaler monitoring the resources consumed by the pods running on each node and reducing the number of nodes to the minimum required for all the pods/applications to continue running.
Now, let’s run our Spark workloads. First, we’ll run the Spark-Pi example. Using the spark-pi.yaml file we can run our first Spark workload. I’ve copied the file locally but you can use this GitHub link to the repository and apply it directly to the cluster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/spark-on-k8s-operator/master/examples/spark-pi.yaml

Spark-Operator will run the first pod which is the Spark driver for our workload process.

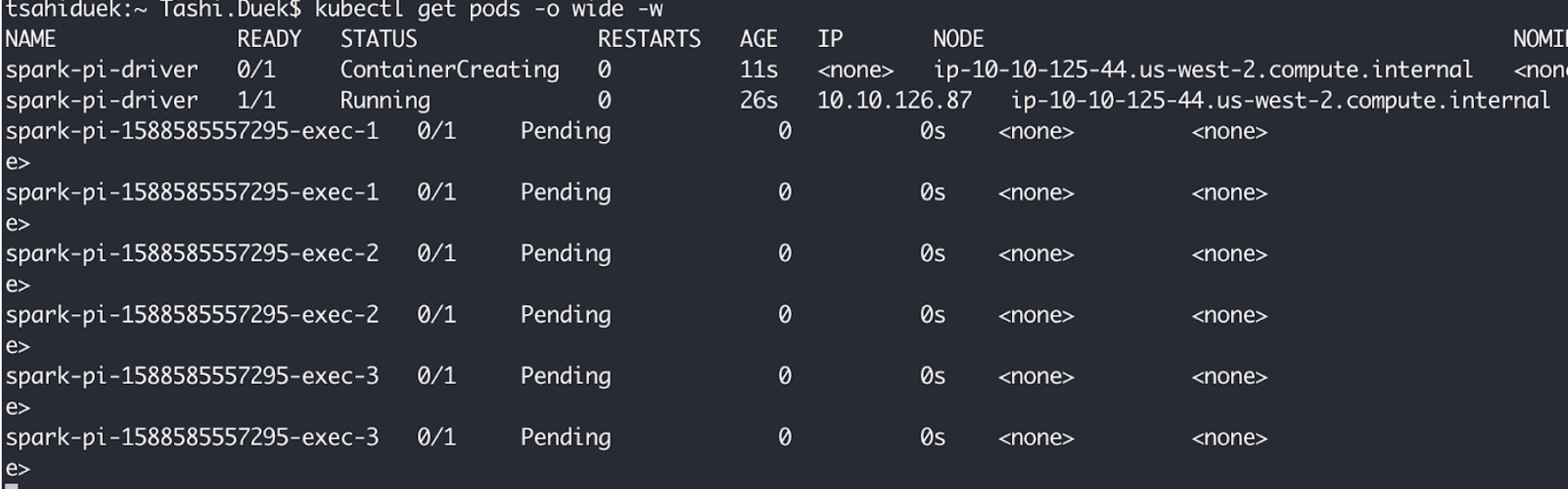
In its turn, the Spark driver pod will launch its executors to perform the actual processing. I’ve updated the yaml file above to include 3 instances, hence there are 3 executors pods. On the default example, you should expect only one executor pod (ending with exec-1 suffix)
As you can see in the screenshot below, the executors’ pod are pending because our cluster doesn’t have enough resources to run the current workload it contains but needs more in order to do the “new” Spark processing workload.
As you can see – when I “described” the pending pod, I can understand that there is not enough CPU available on the cluster, and that’s exactly where Ocean’s autoscaler comes into action.

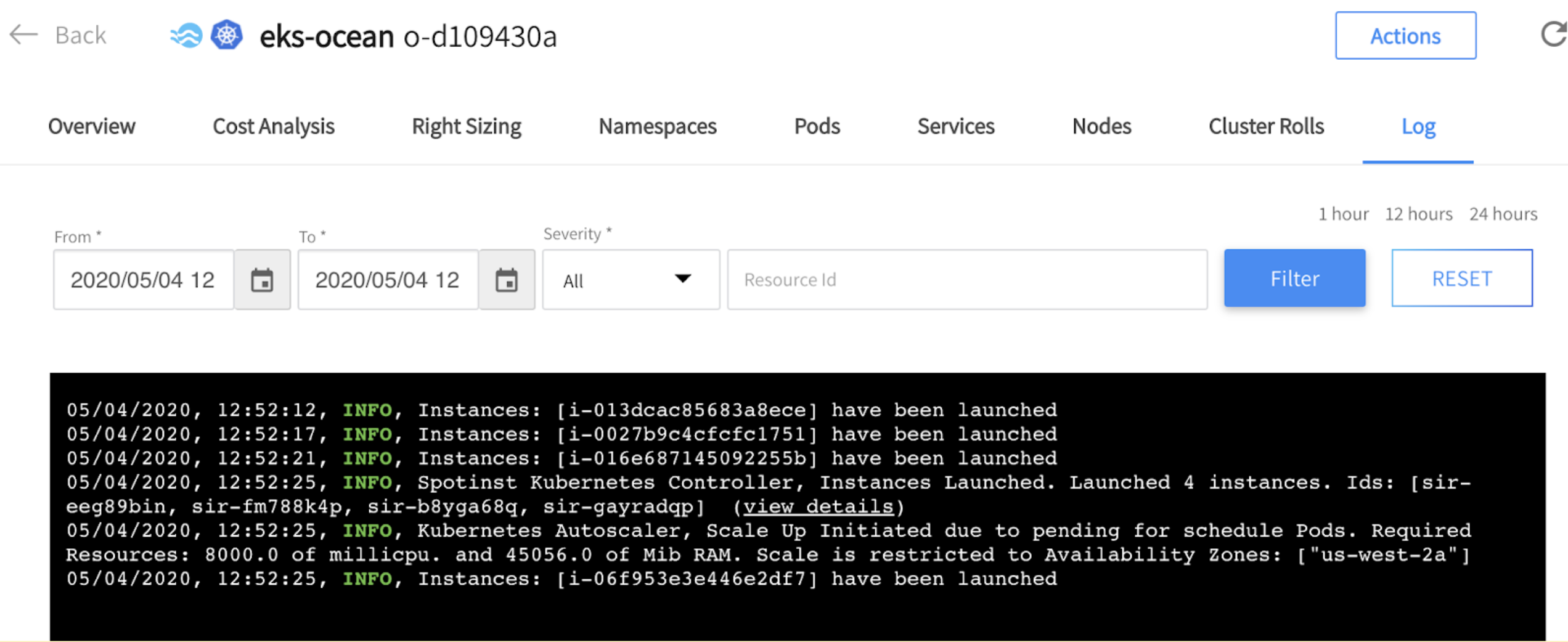
By looking at the Ocean console, under the “Log” tab, we can see that a scaling event had been initiated due to the fact that there are pending pods in the cluster.
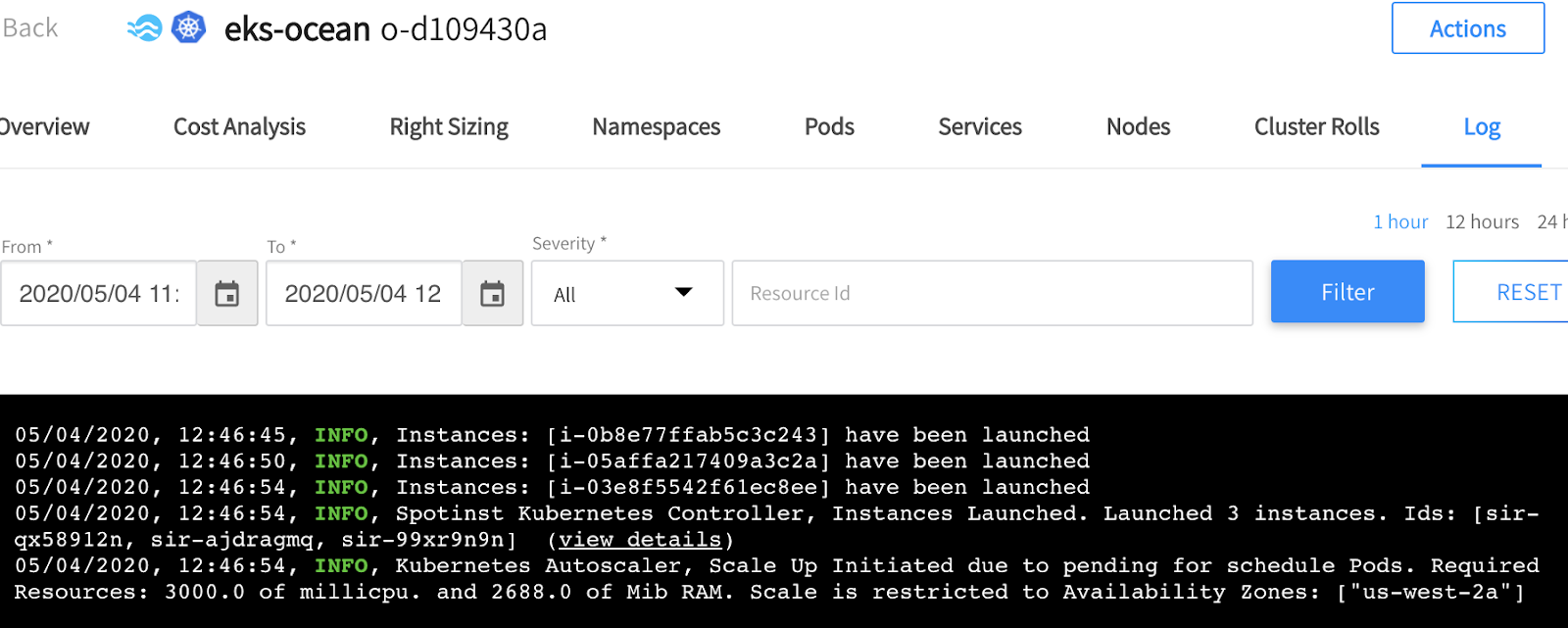
When the instances are launched and connected to the Kubernetes cluster, the pod state changed to “Running” and the workload begins. You can see that after 71 seconds from the moment the pod was created, it changed from a “Pending” state (due to lack of resources) to a “Running” state.

When the Spark application is done, we can get the process log under the SparkApplication CRD and see that it took 3 seconds for the first executor to complete the JOB (the pod with the “exec-1” suffix).
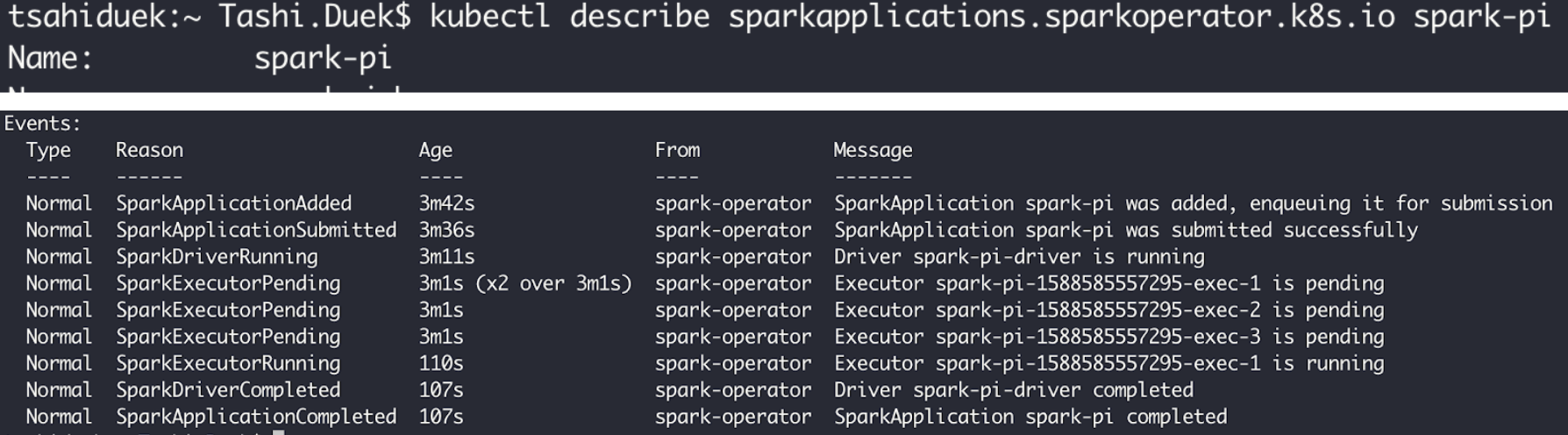
If we want to examine the output of the workload, we’ll need to examine the logs of the Spark driver pod. These are the logs:
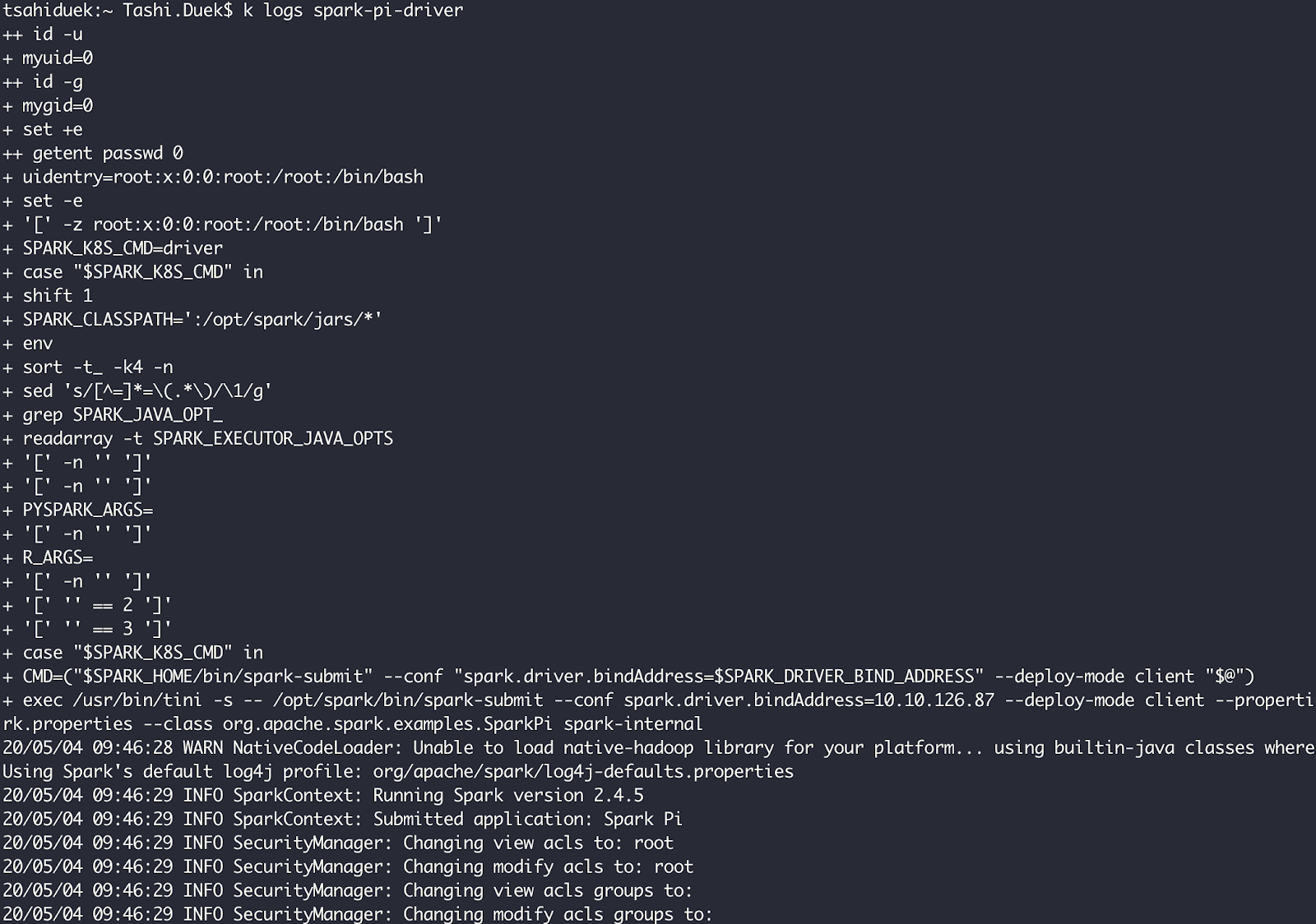
If we’ll scroll until the end, we can see that Pi was calculated pretty well ( March-14 is the easiest way to remember Pi – 3.14).

Spark-Submit method
The second method of submitting Spark workloads will be using the spark=submit command which uses Kubernetes Job.

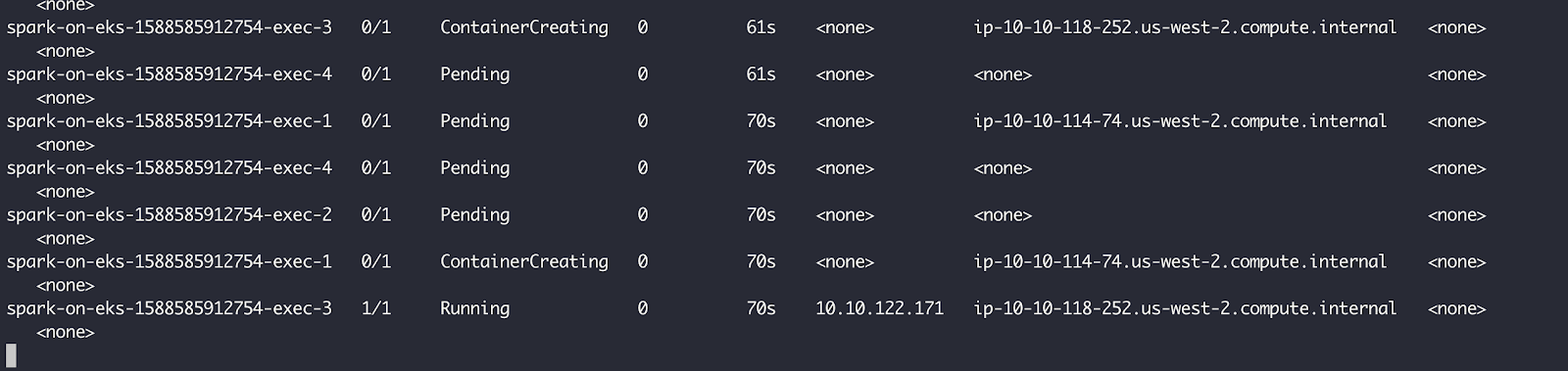
By running “kubectl get pods”, we can see that the “spark-on-eks-cfw6v” pod was created, reached its running state and immediately created the driver pod which in turn, created 4 executors. The executors, however, are pending because of a lack of resources.
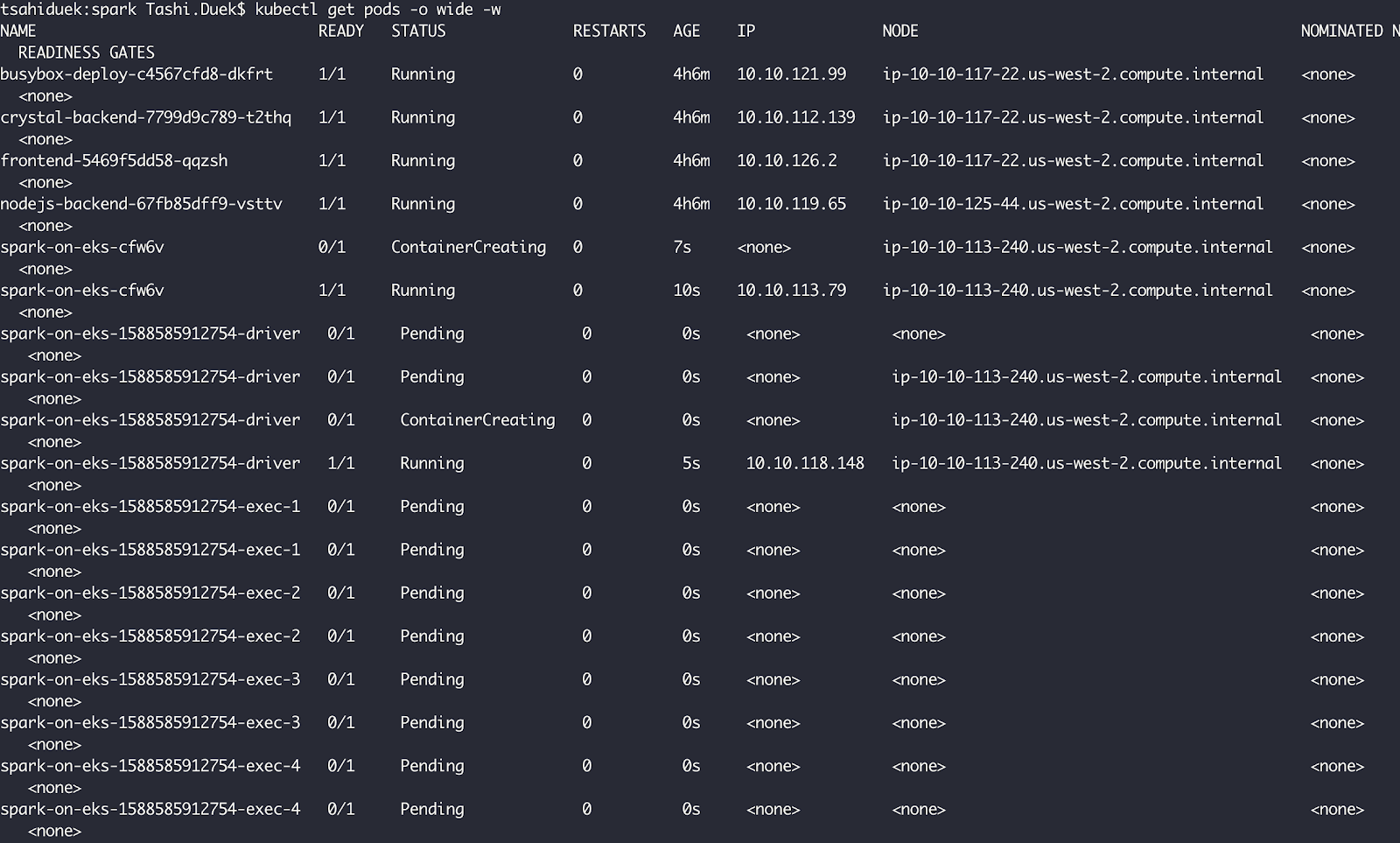
Ocean identifies this as well and launches more instances to provide enough resources for the pending pods.
Similar to before, the pods transition to “Running state” a mere 61 seconds after their creation.
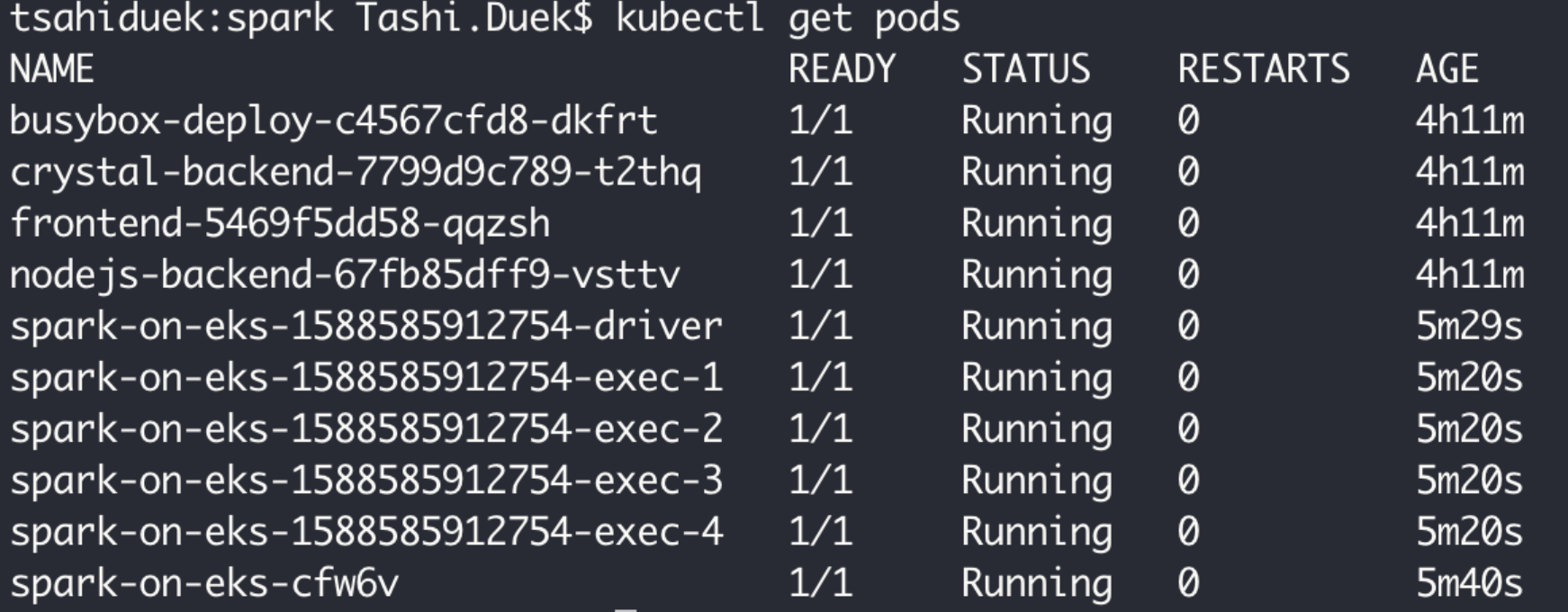
Now that all the instances are up and running, we can see that the job, driver and all 4 executors are running.
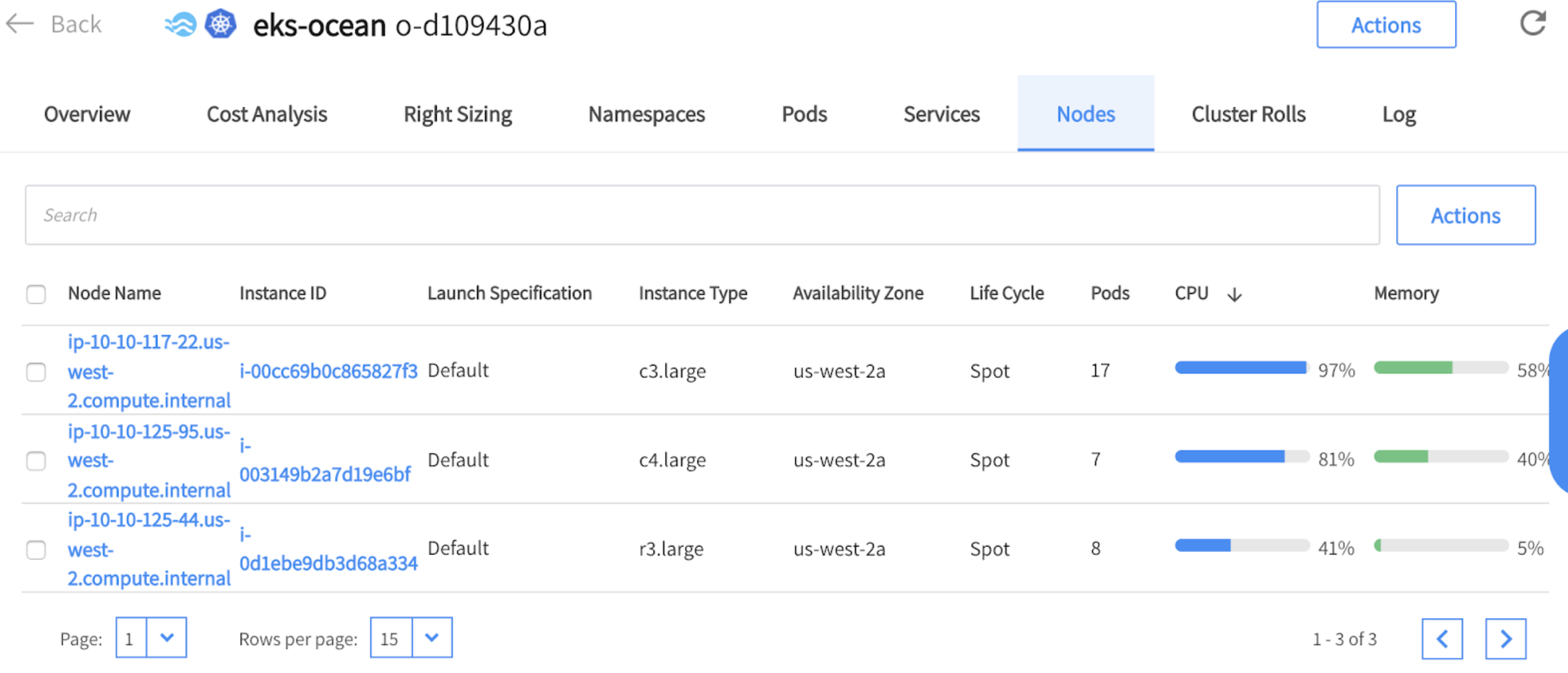
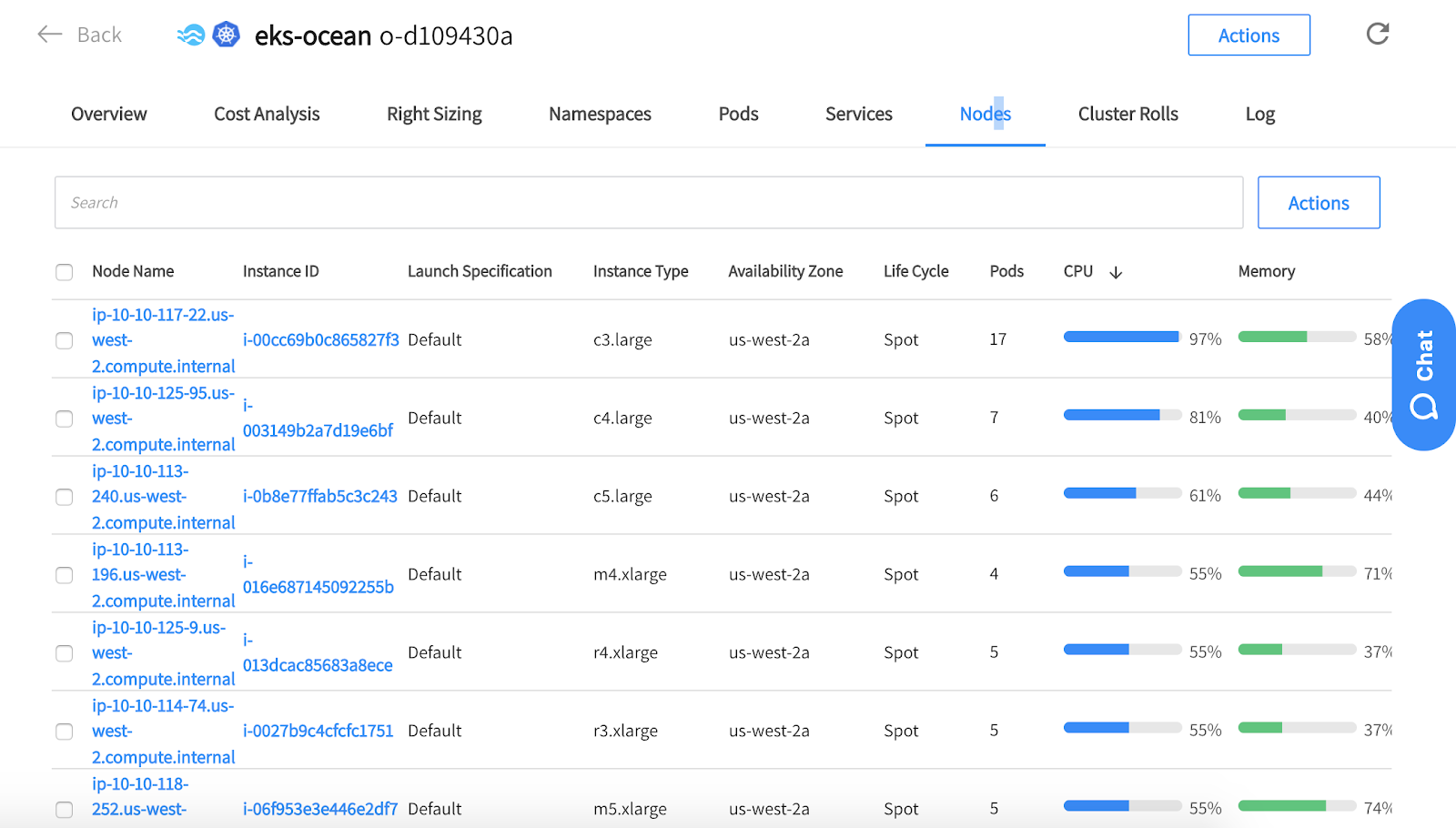
By looking at the Ocean console (under the nodes tab) we can see that the nodes were provisioned to meet the resource requirements of the executors’ pods of our Spark workload.
You can see that the nodes are from different instance-types and sizes and run as spot instances. Ocean leverages a mixed blend of diverse spot markets as part of the way it ensures the availability of instances in case of spot instance interruptions. Ocean also takes into consideration the pods’ requirements and therefore some of the instances are different in terms of size to ensure enough capacity for the various pods that need to run on the cluster.
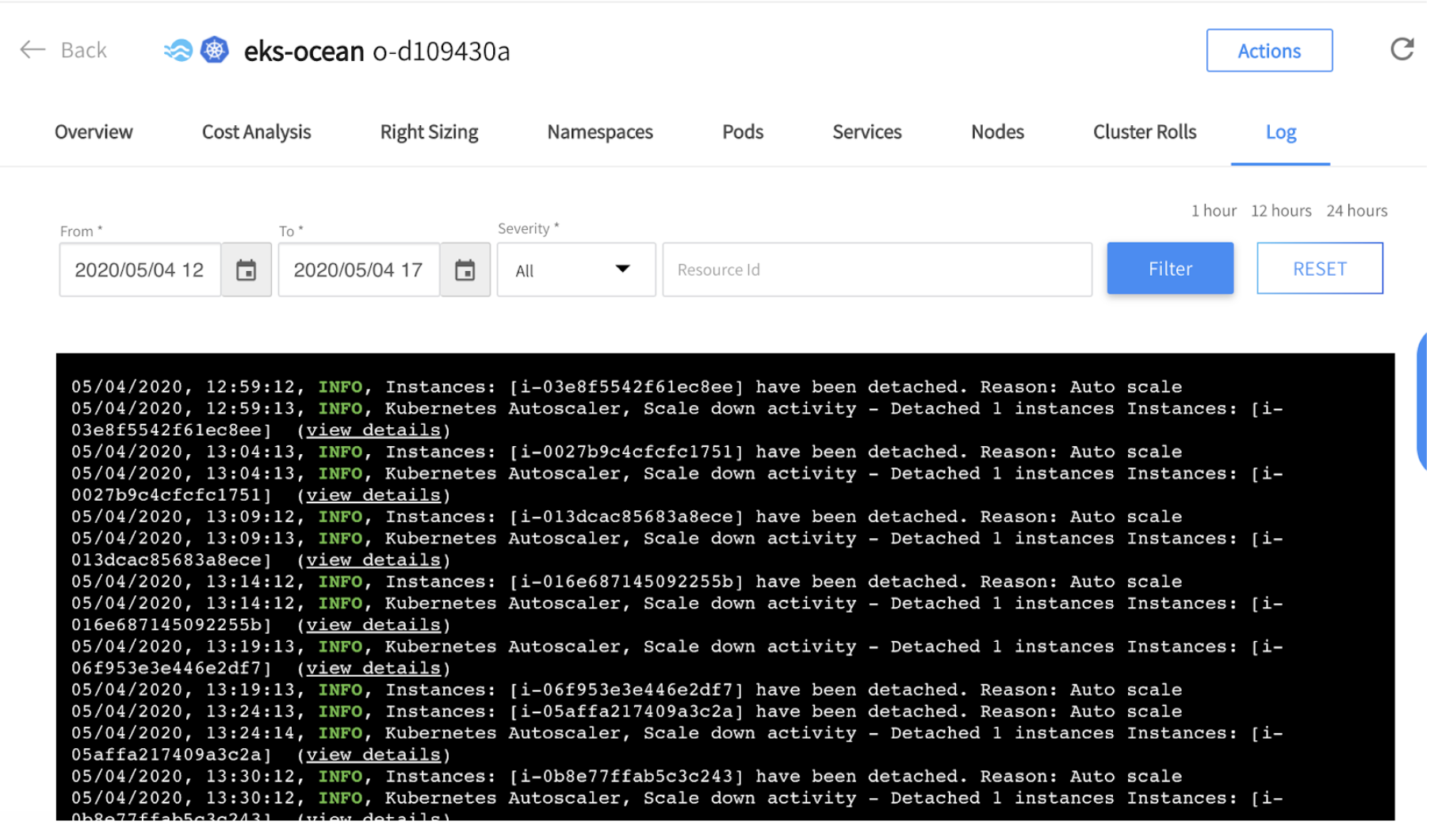
Scaling down the Apache Spark clusters
After our Spark workloads have ended, and the processing is done, the pods are being terminated. Ocean will identify that there are too many resources on the cluster and will initiate scale-down events automatically. All the information about what/when/why instance/s had been scaled down is exposed under the “Logs” tab in the Ocean console.
Going back to the Nodes tab, we can see that there are (again) 3 nodes running in the cluster after all Spark workloads have ended. 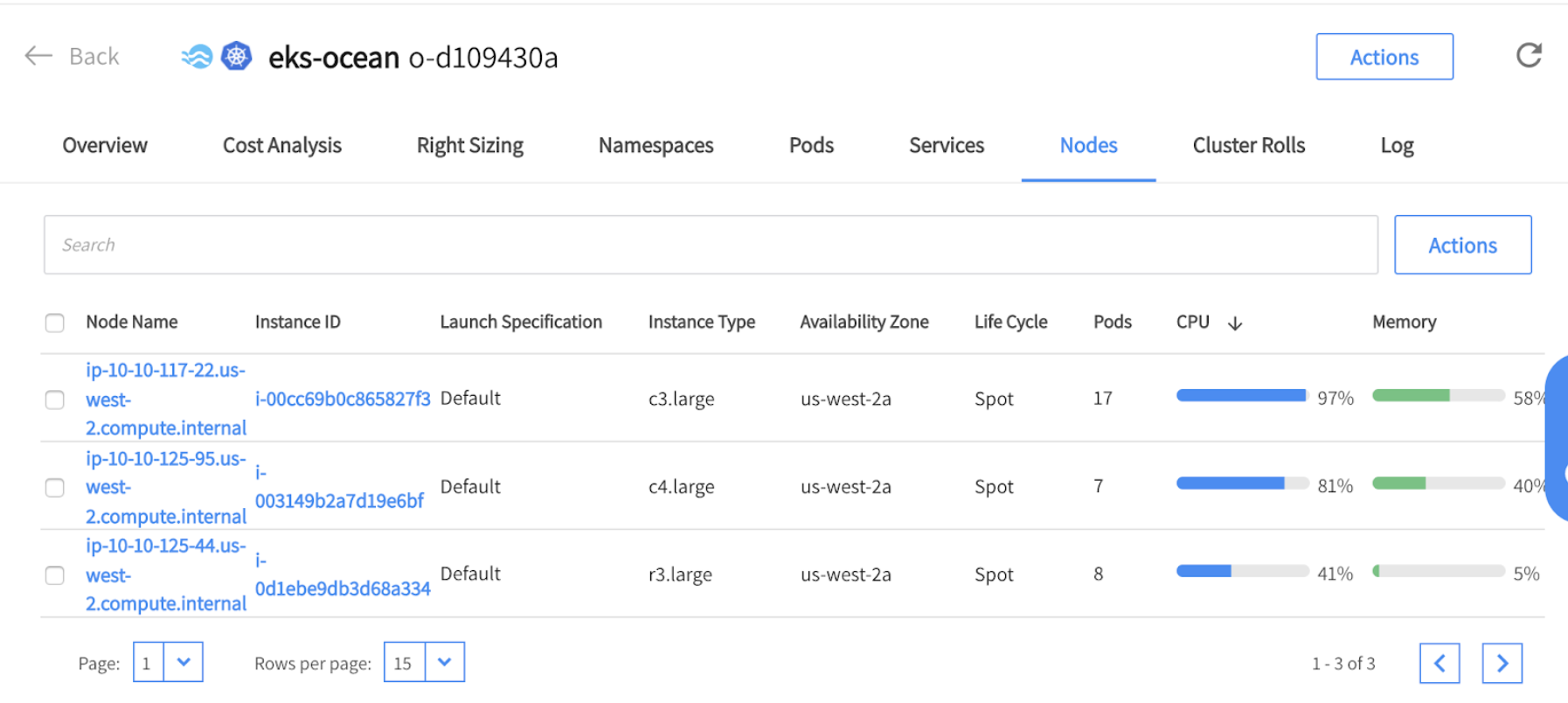
Summary
- We’ve covered why and how users can run their Apache Spark workloads in a Kubernetes cluster.
- We’ve demonstrated the automatic way of managing infrastructure for a Kubernetes cluster without needing to define any scaling rules.
- We’ve seen how Ocean scales-up the right amount of computing resources needed by the Spark workloads and how it automatically scales-down once the processes end.
Now you are set to go! Be in touch with any feedback.